本文主要是介绍【mysql】数据报错: incorrect datetime value ‘0000-00-00 00:00:00‘ for column,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、问题原因
时间字段在导入值'0000-00-00 00:00:00'或者添加 NOT NULL的时间字段时,会往mysql添加0值,此时可能出现此报错。
这是因为当前的MySQL不支持datetime为0,在MySQL5.7版本以上,默认设置sql_mode模式包含NO_ZERO_DATE, NO_ZERO_IN_DATE,表示系统里DATE类型字段不能为0。
二、解决方案
2.1 临时方案,命令行修改,推荐
进入mysql后,执行命令查询当前的模式:
mysql> SELECT @@sql_mode;就可以查到当前系统的sql_mode配置,比如查询结果为:
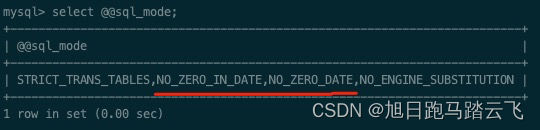
发现配置里有NO_ZERO_DATE,NO_ZERO_IN_DATE,这时我们可以临时移除掉为0限制,它只对本次会话有效:
mysql> SET @@sql_mode = 'STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION';再次查询:
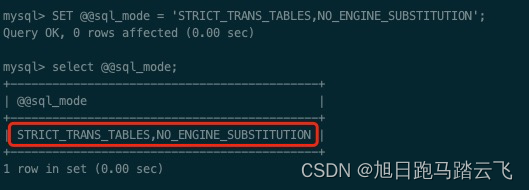
这个方案推荐的理由是,临时修改不会影响现有的模式和数据安全机制。
2.2 全局方案,修改my.cnf或者my.ini,不推荐
mysql的配置文件,在windows系统中是 my.ini,其余系统为 my.cnf。
这里以centos为例,打开配置文件my.cnf
> vi /etc/my.cnf如果存在sql_mode,则移除为0限制。
比如本来配置是 sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,NO_ENGINE_SUBSTITUTION,则修改为sql_mode=STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION:

如果不存在sql_mode,则从默认配置文件拷贝一个过来,并移除为0限制即可,最终配置如上图所示,在节点mysqld下。
这个方案不推荐的理由是,直接修改了sql_mode模式,允许0值存在。
对于字段,我们尽量做到不为null,如果从业务来说可以为空,则为空时设置默认的时间即可。这样从代码和数据优化来说都比较好理解和操作。
2.3 字段类型转换方案,不推荐
也有网友提供了这个方案,先把字段设置成varchar格式,导入数据或者执行命令后,再把字段转换成date格式:
-- 先把字段 clm_date 转换成varchar
mysql> ALTER TABLE tbl_tmp CHANGE clm_date clm_date VARCHAR(20) NULL;-- 导入数据或者执行相关命令
-- ...-- 再把字段 clm_date 的类型转换回datetime
mysql> ALTER TABLE tbl_tmp CHANGE clm_date clm_date DATETIME NOT NULL;这里不推荐的理由,一般来说有了第一种方案,也就没必要进行类型转换。有一种情况就是,如果没有权限设置sql_mode,但是可以进行表格的modify,此时这种方案是可行的。
这篇关于【mysql】数据报错: incorrect datetime value ‘0000-00-00 00:00:00‘ for column的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




