本文主要是介绍Pointnet学习以及对代码的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于点云不是常规数据格式,通常将此类数据转换为规则的 3D 体素网格或图像集合,然后再用神经网络进行处理。数据表示转换使生成的数据过于庞大。
PointNet是第一个直接处理原始点云的方法。只有全连接层和最大池化层,PointNet网络在推理速度上具有强大的领先优势,并且可以很容易地在CPU上并行化。
应对点云的无序性有三种方案:
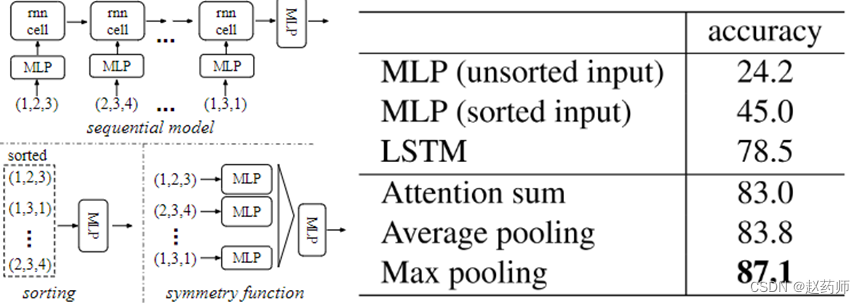
方案1:排序
高维空间的排序,不可稳定。
方案2:假如有N个点,N!种排列训练一个RNN。
2015年《Order Matters: Sequence to sequence for sets》证明RNN网络对序列的排序还是有要求的。
方案3:设计对称函数,因为输入顺序对于对称函数没有影响。比如:加法、乘法
PointNet使用的最大池化,是对称函数。
分类网络以n个点为输入,应用输入和特征变换,然后通过最大池化聚合点特征。输出是 k 个类的分类分数。

Pointnet网络的搭建(tensorflow版):
class PointNet(Model):def __init__(self):super(PointNet, self).__init__()self.MLP64 = layers.Conv1D(filters=64, kernel_size=1, strides=1, padding="valid", activation="relu")self.MLP1024 = layers.Conv1D(filters=1024, kernel_size=1, strides=1, padding="valid", activation="relu")self.Dense10 = layers.Dense(10, activation="softmax")def call(self, inputs, training=None, mask=None):x = self.MLP64(inputs)#(Batch,1,1000,64)print(x.shape)x = self.MLP1024(x)#(Batch,1,1000,1024)print(x.shape)x = tf.reduce_max(x, axis=1)#(Batch,1,1024)print(x.shape)x = layers.Flatten()(x)x = self.Dense10(x)#(Batch,10)print(x.shape)return xmodel = PointNet()
input_shape = (1, 1000, 3)
model.build(input_shape)
model.summary()这是我看pointnet论文后复现的分类网络,由于以前总是对图像进行2D卷积,这里对输入的理解还不深刻。采用了(B,H,W,C)的输入结构,因为是每个点有3个特征,所以将其处理为(B,1,W,C)的结构。但后期发现其比较复杂,所以改进了一下,使用(B,Len,C)的输入结构。
在深度学习中,处理点云数据(Point Cloud Data)或3D形状数据与传统的2D图像数据有所不同。
原始输入结构: (B, H, W, C)
- B:代表批次大小(Batch Size),即一次输入到网络中的样本数量。
- H 和 W:在2D图像中,它们分别代表图像的高度(Height)和宽度(Width)。但在处理点云数据时,由于点云本质上是一组无序的点集合,所以这里的 H 和 W 可能并不是直观意义上的“高度”和“宽度”。在某些情况下,它们可能被用来表示某种形式的网格化点云,但这并不是PointNet的初衷。
- C:代表通道数(Channels),对于RGB图像来说,C=3(红、绿、蓝)。但在点云数据中,每个点可能有多个特征,比如三维坐标(x, y, z)以及其他属性(如颜色、密度等)。
转换为 (B, 1, W, C)
- 将 H 设置为 1 可能是为了尝试将点云数据强制适配到更常见的4D张量结构(即 (B, H, W, C)),但这并不是处理点云数据的最佳方式。因为点云数据中的点是无序的,并且没有固定的网格结构。
改进后的输入结构: (B, Len, C)
- B:仍然代表批次大小。
- Len:代表每个样本中点的数量(Length of points)。这是处理点云数据的更自然的方式,因为它直接反映了点云数据的特点——即一组无序的点集合。
- C:仍然代表每个点的特征通道数。
使用 (B, Len, C) 的输入结构可以更直接地处理点云数据,并且符合PointNet的设计初衷。
def Point_MLP(inputs, num_filters, use_bn=True, activation='relu'):x = layers.Conv1D(num_filters, kernel_size=1, activation=activation, padding='valid')(inputs)if use_bn:x = tf.keras.layers.BatchNormalization()(x)x = tf.keras.layers.Activation(activation)(x)return xdef Model_Point(point_num, feature_num, mode):inputs = layers.Input(shape=(point_num, feature_num))x64 = Point_MLP(inputs, 64) #(B,N,64)x512 = Point_MLP(x64, 512)x1024 = Point_MLP(x512, 1024) #(B,N,1024)gloable = tf.reduce_max(x1024, axis=1) #(None, 1024)if mode == "clc":x = layers.Flatten()(gloable)x = layers.Dense(10, activation="softmax")(x)model = Model(inputs=inputs, outputs=x)if mode == "seg":global_feature_tiled = tf.tile(tf.expand_dims(gloable, 1), [1, tf.shape(x512)[1], 1])concatenated_features = tf.concat([x512, global_feature_tiled], axis=2)#concatenated_features 的形状是 (batch_size, num_points, local_feature_dim + global_feature_dim)model = Model(inputs=inputs, outputs=concatenated_features)return modelPointNet = Model_Point(10000, 3, mode="clc")
PointNet.summary()这篇关于Pointnet学习以及对代码的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






