本文主要是介绍本地 Java API 访问云上 HDFS 集群的问题与解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
这篇文章默认是已经在云上配置好了 Haoop 集群,因此本文主要是记录一些可能会出现错误的地方。
如果还不会配置 Hadoop 集群,那么可以参考本专栏的另一篇文章:云上配置 Hadoop 集群详解
另外在进行本文的学习之前也建议先看看该文章,因为一些基本概念这里不会再进行解释了嗷。
1、本地(windows)配置主机名映射
在使用 Java API 进行远程访问之前,要先在本地的 Windows 环境下配置上相应的主机名映射捏。
打开下面路径,进行文件配置:
C:\Windows\System32\drivers\etc\hosts
打开该文件,可以看到下面的内容:
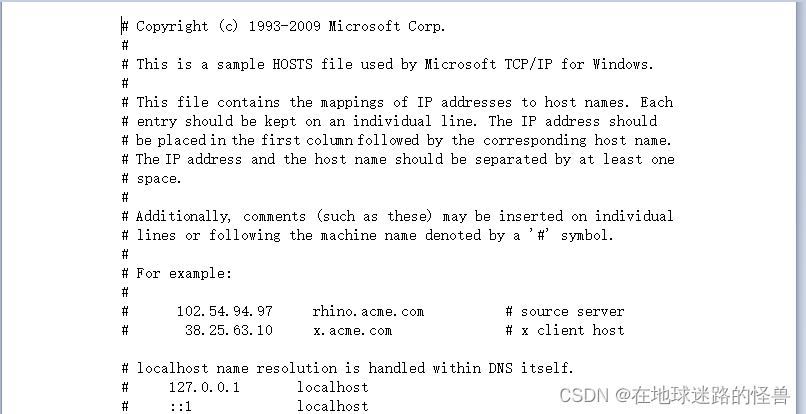
我们需要在上面追加一行内容,内容格式为:
xxx.xxx.xxx.xxx cloud_host_name
其中前面的 xxx.xxx.xxx.xxx 为你的云服务器的公网 IP 地址,后面的 cloud_host_name 则是你云服务器上的主机名称,该主机名称可以在云服务器上键入命令:hostname 得知:
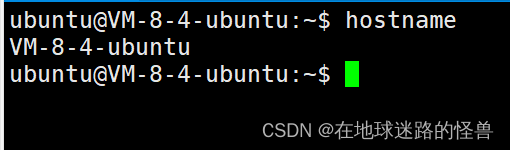
因此,假设你的服务器的公网 IP 地址为 111.123.123.123,且云服务器的主机名为 VM-8-4-ubuntu 那么需要追加的内容就是:
111.123.123.123 VM-8-4-ubuntu
2、本地(windows)配置JDK以及Hadoop的环境变量
本地连接云服务器的Hadoop集群时需要配置 Hadoop 的环境变量,否则启动会报错,而配置 Hadoop 的环境变量时又依赖 JDK 的环境变量,因此也要配置好 JDK 的本地环境变量。
配置环境变量这个网上教程就太多了,随便 CSDN 一下都一大把,因此这里不再赘述。
3、云服务器上需要进行的配置
3.1、首先也是需要进行主机名的映射
Linux的主机名配置在根目录下的 /etc/hosts 文件中,注意需要切换成 root 用户才有权限进行更改:
/etc/hosts

使用 vim 打开后,如下:
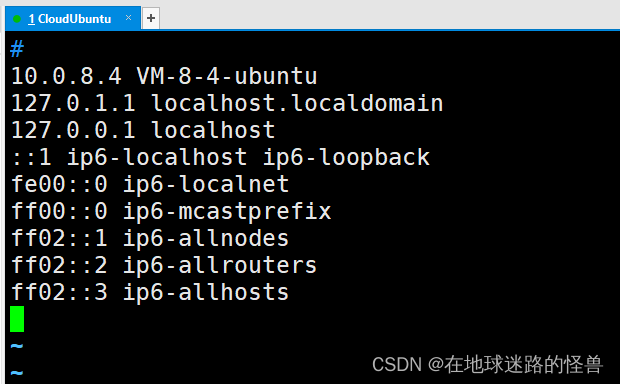
这里要注意,上图已经是我修改过后的 hosts 文件了,因此如果你和我的不一样那么也很正常,你只要改成我上面的样子即可。
那么重点改哪里呢:
众所周知,在我们购买云服务器时,会有两个 IP 地址,一个是公网 IP 地址另一个是内网 IP 地址:

形式基本如上图如所示,那么在云上的 Hadoop 集群中,其内部通信是通过内网进行的,因此我们需要配上类似于刚刚在 Windows 环境上的操作,即在 /etc/hosts 文件中追加下面内容:
内网地址IP 云服务器主机名
如
192.168.88.152 VM-8-4-ubuntu
如果你的云服务器主机名的默认情况下被映射到了别的IP地址(多半是本地环回地址),那么请将其去掉改成上述内容。
总之就是确保你的云服务器主机名所对应的只有一个内网IP地址即可,因为如果有多个的话我们自己设置的内网IP映射主机名的优先级不够别的映射关系级别高,会让我们自己设置的不起作用。
3.2、修改Hadoop的配置文件
主要是 Hadoop 文件夹下的下面几个文件:
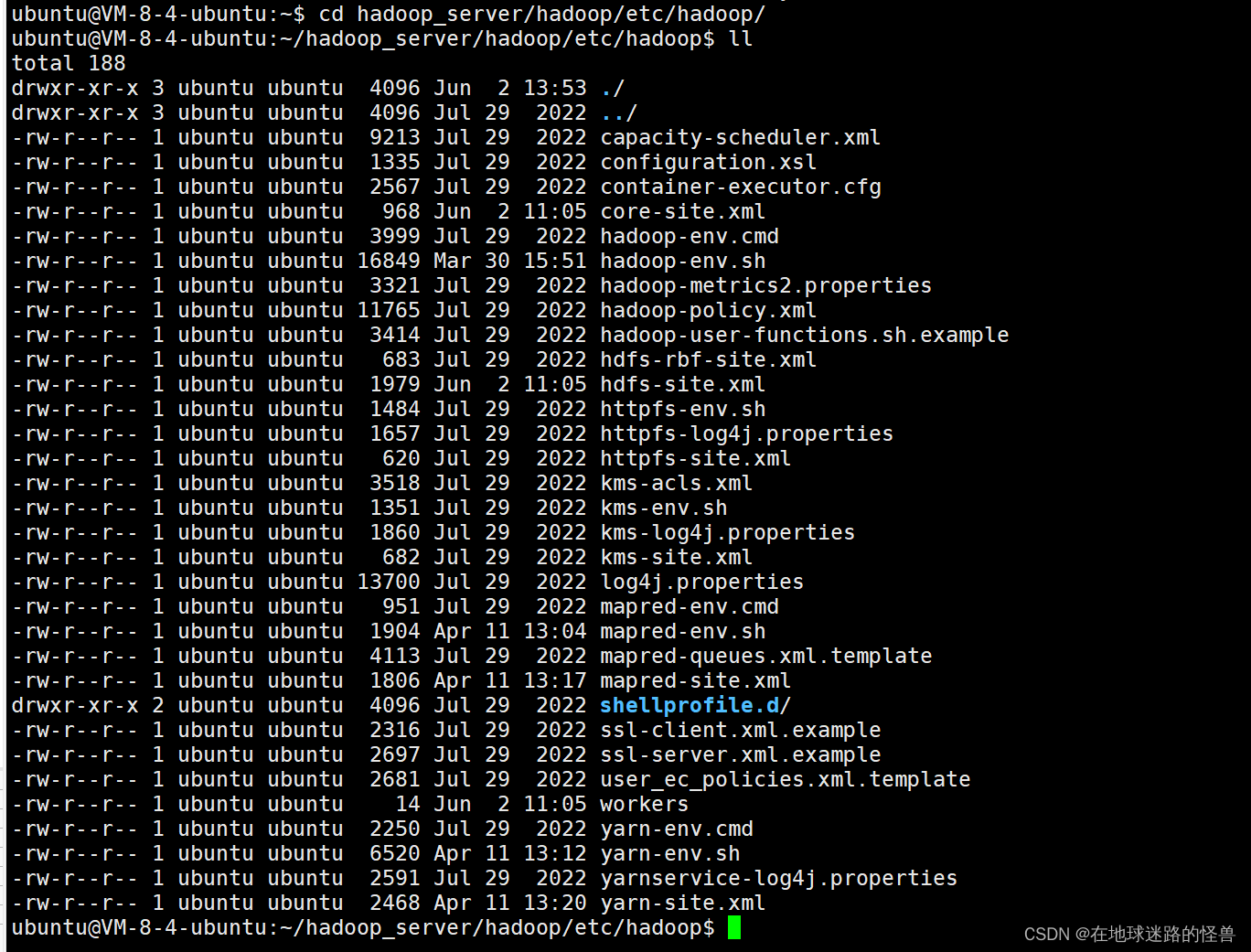
1、修改 workers 文件:
vim 打开 workers ,写入我们的主机名(注意一定是本机的主机名嗷),因为我只有一台云服务器,所以我只在该文件中写入一个主机名即可,因此相当于是在构建一个伪分布式 Hadoop 集群:
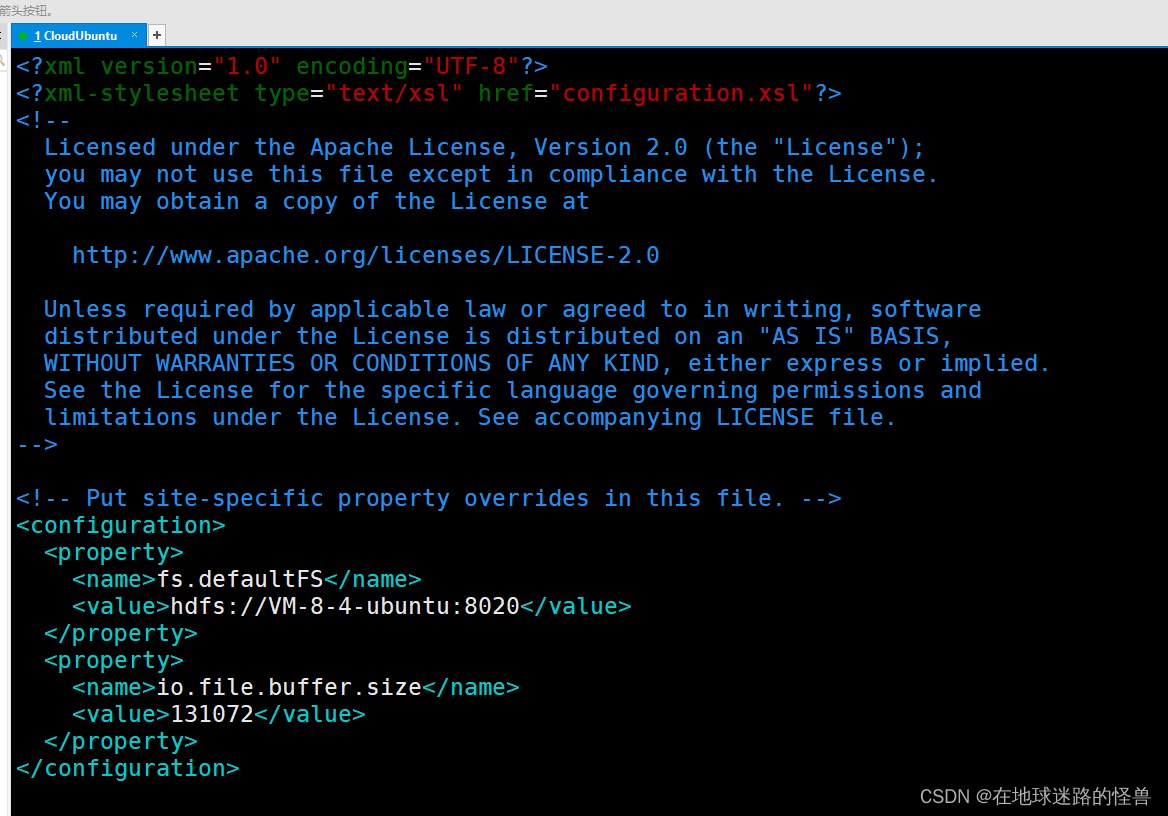
2、vim 打开 core-site.xml 文件:
在该文件中配置好我们的内部通讯端口,也就是我们的 namenode 主节点,我这唯一一台的云服务器既是主节点也是从节点,即既是namenode 节点也就是 datanode 节点,因此这里配置主节点用的是本服务器的主机名(注意一定是本机的主机名嗷):
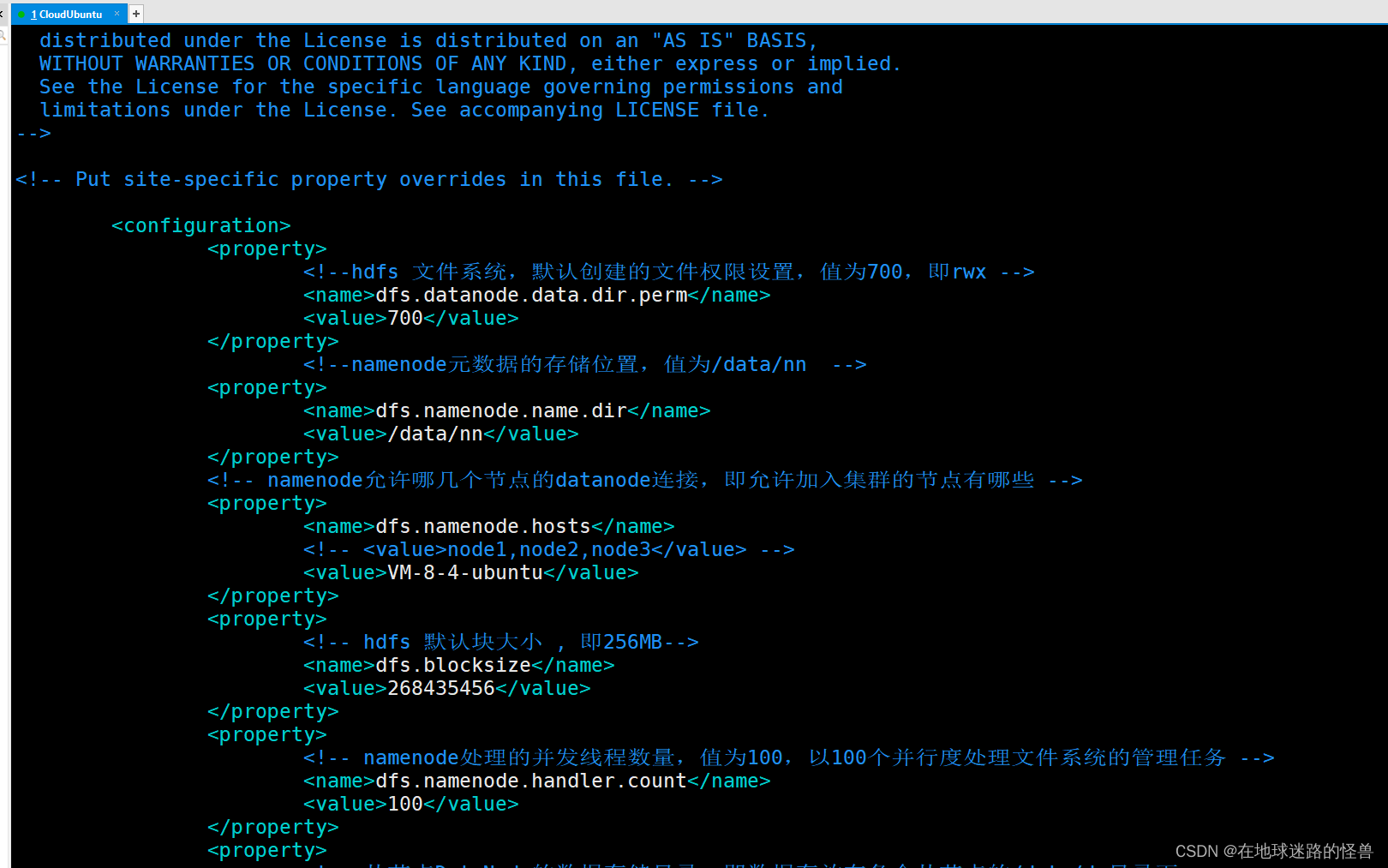
3、vim 打开 hdfs-site.xml 文件
在上文刚刚提过,我这唯一一台服务器既是主节点也是从节点,因此这里配置数据节点 datanode 时,同样采用的本机的主机名(注意一定是本机的主机名嗷):
全部弄完这些之后,就可以格式化 namenode 然后启动 hdfs 集群了。
格式化时不出意外按照上面的配置流程走下来,格式化完后的结果应该如下:

“Shutting down NameNode at VM-8-4ubuntu(也就是你的服务器主机名)/10.0.8.4(也就是你服务器的内网IP地址)”
格式化后如果如上,那么配置应该就没有问题了。
4、注意云服务器的端口开放问题
因为云服务器的端口默认只开放了几个,而 hdfs 集群会涉及较多的端口,因此这里根据我的经验需要开放下面几个:
首先是我们在之前的配置中所配置的 namenode 的通讯端口:8020,注意这个是我们自己可以配置的:

然后是在集群内部各个节点之间的通讯端口,这是 Hadoop 的 HDFS 默认占用的端口,请注意这几个端口有无被占用:

把这几个端口开放了应该连接就没有问题了。
5、测试
可以使用下面的 Java 代码进行简单的测试,也可以让 GPT 生成一些测试代码来进行简单的测试:
@PostMapping("/upload")public ResponseEntity<String> handleFileUpload(@RequestParam("file") MultipartFile file) throws IOException, InterruptedException {//1. 初始化配置对象 需要new出来,用来配置Hadoop的集群节点信息,主要是配置主节点namenodeConfiguration conf = new Configuration();//下面这行代码告诉Hadoop客户端使用数据节点(Datanode)的主机名来建立连接,而不是使用IP地址//因为在分布式环境下,节点(包括数据节点)的IP地址可能会发生变化,而主机名通常是稳定的。//因此,通过使用主机名而不是IP地址,可以提高Hadoop集群的可维护性和可靠性conf.set("dfs.client.use.datanode.hostname", "true");//2. 添加配置 (其实就是提供一个key - value)//xxx.xxx.xxx.xxx改成你的公网IP地址嗷FileSystem fileSystem = FileSystem.get(URI.create("hdfs://xxx.xxx.xxx.xxx:8020"),conf,"ubuntu");//4、将前端传来的文件数据上传至hdfs/*用MultipartFile的getInputStream方法,获得输入流,随后转换成Hadoop的FSDataOutputStream输出流后,就可以将文件上传到Hadoop最后记得flush和close输入输出流*/InputStream inputStream = null;FSDataOutputStream fsDataOutputStream = null;try{inputStream = file.getInputStream();//用户上传文件存储在hdfs中的路径//截取文件名后缀来分别进行存储String fileName = file.getOriginalFilename();Path desPath = new Path("/"+fileName);//创建路径后写入文件fsDataOutputStream = fileSystem.create(desPath);byte[] b = new byte[4096];int read;while((read=inputStream.read(b)) > 0){fsDataOutputStream.write(b,0,read);}fsDataOutputStream.flush();return ResponseEntity.ok().body("File uploaded to HDFS successfully.");} catch (IOException e){e.printStackTrace();} finally {if (null != inputStream) inputStream.close();if (null != fsDataOutputStream) fsDataOutputStream.close();}//关闭hdfs的连接工具if (fileSystem != null) {fileSystem.close();}return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Failed to upload file to HDFS");}
6、其他问题
如果还出现了其他的报错,那么建议自己反复检查一下自己的配置以及程序,不然就多多百度,按我的经验应该是将上面的步骤挨个做完应该就能解决了。
还有一个问题,如果出现了往 HDFS 上写入文件只能写入文件名却无法写入文件内容的情况时,或者报错类似于:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
可以参考下面这篇文章:使用Java API 向 HDFS 中写入数据报错解决;
这篇关于本地 Java API 访问云上 HDFS 集群的问题与解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




