本文主要是介绍【传知代码】图像高清化(论文复现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:在数字化时代的浪潮中,图像已然成为我们生活中不可或缺的一部分。无论是社交媒体上分享的美景,还是工作场合中展示的数据图表,图像都以直观、生动的形式传递着信息,承载着记忆。然而,随着技术的不断进步和人们对视觉体验要求的日益提高,如何使图像在保持原有细节和色彩的基础上,实现更高清晰度的展示,成为了一个值得深入探讨的话题。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
图像超分辨率技术涉及从低分辨率的图像中恢复到高分辨率的图像,这在计算机视觉和图像处理领域是一种关键的方法。由于其具有重建精度高、速度快等特点,已成为研究热点之一。在实际的使用场景中,它具有众多的应用场景。目前,已有许多基于卷积神经网络的超分辨率算法被提出并得到成功应用。随着深度学习技术的不断进步,超分辨率方法在性能上实现了显著的提升。目前已经提出了一些基于卷积神经网络的、能够处理大量低维空间信息的、具有较好泛化能力的、能有效解决高维稀疏问题的超分辨算法。但是,鉴于这些超分辨率技术大部分都是受监控的,它们往往受到特定训练数据的限制,尤其是低分辨率的图像,这些图像是从高分辨率的相应图像中预先获取的。为了减少低分辨率图像带来的损失,人们提出了多种基于无标记样本的低秩表示和降维算法来提高重建质量。但是,真实的低分辨率图像很少受到这些约束的影响,这导致了最先进的方法在实际应用场景中的表现并不理想。
该论文介绍了一种“零样本”图像超分辨率方法,利用单张图像内部信息的重复性训练小型卷积神经网络。该方法可以针对不同的图像进行自适应调整,这使得其能够对真实图像或获取方式未知的图像进行高清化处理,如下图所示展示的效果:

本文复现一下 论文 提出的方法基于自然图像中强大的内部数据重复性。如下图所示,小图像块会在单张图像内部反复出现,不仅在同一尺度内出现,也在不同尺度之间重复出现:

论文所提出的策略是将图像内部数据的重复性与深度学习的泛化特性相结合。利用深度网络对输入图像进行特征提取和分类处理后,再把结果反馈到分类器中去,从而完成了一种基于深度学习的图像复原算法。在没有外部样本可供参考的情况下,我们可以为一个特定的测试图像训练一个小型神经网络,这个网络主要用于处理该图像的超分辨率问题。为了进一步提高模型性能,还使用了一种新的训练方法——基于小波变换和多层感知器的联合建模方式。更具体地说,这种方法是通过从测试图像中提取样本来训练小型卷积神经网络的。这批样本是通过对低分辨率图像执行降采样操作,从而生成其更低分辨率的版本而获得的。由于降维会导致大量冗余信息,因此,首先使用一些简单且有效的特征提取算法来获取训练样本。接下来,这种方法使用这些下采样的图像作为输入数据,并以原始图像为训练目标,以提升网络在重建高分辨率图像方面的能力。图3展示了一幅小猫躺在落叶堆上的照片,通过采用论文提出的超分辨率处理方法,图像中的细节部分变得更为清晰,也就是说,原先模糊的毛发现在变得更加细腻,如下图所示:
由于训练集仅包含一个实例,该方法对该图像进行数据增强。具体地,该方法通过将原图旋转不同角度以提取更多的样本来进行训练。为了加速训练,该方法在每次迭代时,从随机选择的样本对中随机裁剪固定大小的随机区域。为了增加方法的稳健性,以及在非常小的低分辨率图像上也能实现较大的放大效果。该方法将希望的放大倍率 ss 分解成多个更小且等大的放大倍率:
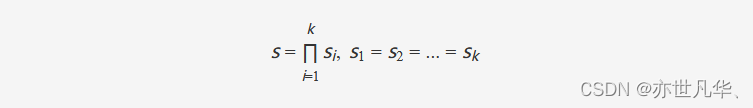
该方法使用的卷积神经网络包含 8 个隐藏层,每层有 64 个通道,并使用 ReLU 激活函数。此外,网络的输入被事先插值到输出大小。该网络只学习插值后的低分辨率图像与其高分辨率父图像之间的残差。训练过程使用 L1 损失函数和 ADAM 优化器。初始学习率为0.001。该方法还会定期对重建误差进行线性拟合,如果标准偏差比线性拟合的斜率大一个因子,就将学习率除以10。当学习率降低到 10−610−6 时,停止训练。
演示效果
配置环境并运行 main.py脚本,效果图4所示。由图4可见,图像的长宽均被放大四倍。观察图3可以发现细节部分变得更加清晰了,如下图所示:

此外,网站还提供了在线体验功能。用户只需要输入一张大小不超过 1MB 的 JPG 图像,网站就会随机截取图像的一部分并放大8倍。在线体验的效果如图5所示,经观察可以发现图片在被放大的同时,细节变得更加丰富,如下图所示:

运行代码如下,解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip image_super_resolution.zip
cd image_super_resolution代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt# 如果希望在本地运行程序,请运行如下命令:
python main.py# 如果希望在线部署,请运行如下命令:
python main-flask.py如果希望使用自己的文件路径或改动其他实验设置,请在文件config.json中修改对应参数。以下是参数含义对照表:
| 参数名 | 含义 |
|---|---|
| max_MB | 输入图像文件大小限制(以 MB 为单位) |
| base64 | 是否将输出转码为 base64 格式 |
| image | 输入图像路径 |
| output | 输出图像路径 |
| in_channels | 输入图像通道数 |
| model_width | 网络宽度 |
| model_depth | 网络深度 |
| model_kernel_size | 网络卷积核大小 |
| lr | 初始学习率 |
| lr_stop | 停止训练时学习率 |
| lr_decay | 学习率衰减率 |
| lr_decay_ratio | 学习率衰减因子 |
| lr_decay_range | 学习率衰减参考范围 |
| lr_decay_step | 学习率衰减检查间隔 |
| num_epochs | 最大迭代次数 |
| crop_size | 训练时输入图像截取大小 |
| patch_size | 测试时输入图像截取大小 |
| scale_factor | 放大率 |
| scale_times | 放大次数 |
核心代码
下面这段代码实现的是一个超分辨率算法,用于将低分辨率图像放大到高分辨率。该算法的输入是一张低分辨率图像,输出是一张高分辨率图像,该算法的实现过程如下:
1)读取超分辨率算法的参数。
2)将输入图像转换为 float32 张量,并将其进行裁剪,以便后续处理。
3)根据不同的缩放程度和旋转角度,生成一系列不同的输入图像。
4)计算采样概率,用于随机选择训练样例。
5)构建一个简单的卷积神经网络模型,并使用 L1 损失函数进行训练。
6)对原图像进行超分辨率处理。具体来说,将原图像拆分成一系列小尺寸图像,对每个小尺寸图像执行超分辨率操作,最后将所有小尺寸图像合并成一张高分辨率图像。
7)将输出的高分辨率图像转换为 PIL 图像格式,并返回。
def super_resolution(input_image, configs, show_process=False):# 参数读取in_channels = configs['in_channels']model_width = configs['model_width']model_depth = configs['model_depth']model_kernel_size = configs['model_kernel_size']lr = configs['lr']lr_stop = configs['lr_stop']lr_decay = configs['lr_decay']lr_decay_ratio = configs['lr_decay_ratio']lr_decay_range = configs['lr_decay_range']lr_decay_step = configs['lr_decay_range']num_epochs = configs['num_epochs']crop_size = configs['crop_size']patch_size = configs['patch_size']scale_factor = configs['scale_factor']scale_times = configs['scale_times']# 将图像转为float32张量init_transforms = v2.Compose([v2.ToImage(),v2.ToDtype(torch.float32, scale=True)])input_image = init_transforms(input_image).unsqueeze(0)# 若图像过小则返回原图像height = input_image.shape[2]width = input_image.shape[3]if height < 3 or width < 3:output_image = input_image.squeeze(0).permute(1, 2, 0)output_image = (torch.clamp(output_image, min=0, max=1) * 255).to(torch.uint8).cpu().numpy()output_image = Image.fromarray(output_image)return output_imagecrop_size = min(height, width, crop_size)crop = v2.RandomCrop([crop_size, crop_size])# 获取不同角度的输入图像images = [[]]for degree in [0, 90, 180, 270]:rotated = v2.functional.rotate(input_image, angle = degree, expand=True)rotated_flipped = v2.functional.horizontal_flip(rotated)images[0].append(rotated)images[0].append(rotated_flipped)# 获取不同缩放程度的图像for scale_time in range(scale_times):images.append([])for image in images[scale_time]:height = image.shape[2]width = image.shape[3]resized = v2.functional.resize(image, [int(height / scale_factor), int(width / scale_factor)])resized = v2.functional.resize(resized, [height, width])images[scale_time + 1].append(resized)# 计算采样概率props = np.array([scale_factor ** (2 * scale_time) for scale_time in range(scale_times)], dtype=np.float32)props = props / np.sum(props)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = SimpleConvNet(in_channels, model_width, model_depth, model_kernel_size).to(device)criterion = nn.L1Loss()optimizer = optim.Adam(model.parameters(), lr=lr)lr_scheduler = StepLR(optimizer, step_size=1, gamma=lr_decay)model.train()current_lr = lrunchanged_epoch = 0loss_epoch = []if show_process:epochs = tqdm(range(num_epochs), desc='Training')else:epochs = range(num_epochs)for epoch in epochs:# 随机抽取训练样例scale_time = np.random.choice(list(range(len(props))), p=props)transfer_id = rd.randint(0, 7)HR_image = images[scale_time][transfer_id]LR_image = images[scale_time + 1][transfer_id]cropped_images = crop(torch.cat([HR_image, LR_image], dim=0))cropped_HR_image = cropped_images[0: 1].to(device)cropped_LR_image = cropped_images[1: 2].to(device)# 计算梯度并更新模型参数optimizer.zero_grad()outputs = model(cropped_LR_image)loss = criterion(outputs, cropped_HR_image)loss.backward()optimizer.step()loss_epoch.append(loss.item())unchanged_epoch += 1# 检查损失并判断是否降低学习率if unchanged_epoch >= lr_decay_step and (epoch + 1) % lr_decay_step == 0:loss_range = np.array(loss_epoch[-min(lr_decay_range, len(loss_epoch)):])epoch_range = np.array(list(range(len(loss_range))))slope, interept = np.polyfit(loss_range, epoch_range, 1)loss_std = np.sqrt(np.var(loss_range - (slope * epoch_range + interept)))if loss_std > -slope * lr_decay_ratio:lr_scheduler.step()unchanged_epoch = 0current_lr = optimizer.param_groups[0]['lr']# 学习率低于最小值则停止训练if current_lr < lr_stop:breakif show_process:print(f'Loss: {np.mean(loss_epoch[-100:])}')model.eval()# 对原图执行超分辨率with torch.no_grad():height = input_image.shape[2]width = input_image.shape[3]for scale_time in range(scale_times):# 将输入图像拆解成一系列小尺寸图像input_image = v2.functional.resize(input_image, [height * scale_factor, width * scale_factor])height = input_image.shape[2]width = input_image.shape[3]pad_h = (patch_size - (height % patch_size)) % patch_sizepad_w = (patch_size - (width % patch_size)) % patch_sizepadding = (0, pad_w, 0, pad_h)input_image = F.pad(input_image, padding, mode='reflect')patches = split_image(input_image, patch_size)output_patches = []if show_process:batches = tqdm(range(patches.size(2)), desc=f'Infering {scale_time + 1}/{scale_times}')else:batches = range(patches.size(2))# 依次对小尺寸图像执行超分辨率for i in batches:output_patches.append([])for j in range(patches.size(3)):patch = patches[:, :, i, j, :, :].to(device)output_patch = model(patch)output_patches[i].append(output_patch)# 融合超分辨率小尺寸图像output_patches = torch.stack([torch.stack(output_patches[i], dim=2) for i in range(patches.size(2))], dim=2)output_image = merge_patches(output_patches)output_image = output_image[:, :, :height, :width]input_image = output_imageoutput_image = output_image.squeeze(0).permute(1, 2, 0)output_image = (torch.clamp(output_image, min=0, max=1) * 255).to(torch.uint8).cpu().numpy()output_image = Image.fromarray(output_image)return output_image写在最后
在深入探讨了图像高清化的奥秘与魅力之后,我们不禁对这项技术产生了更深的敬畏和期待。图像高清化不仅是一项技术革新,更是对人类视觉体验的一次革命性提升,回顾我们所走过的旅程,从最初的简单插值方法到如今基于深度学习的超分辨率技术,图像高清化技术已经取得了长足的进步。这些技术的发展不仅让我们能够欣赏到更为清晰、细腻的图像,更为许多行业带来了前所未有的便利和可能性。
因此,让我们共同期待这一天的到来,期待图像高清化技术为我们带来的更多惊喜和可能。让我们以更加开放的心态和更加敏锐的洞察力,去迎接这个充满挑战和机遇的未来。在这个数字化时代,让我们携手共进,共同开创图像高清化的新篇章!
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号

这篇关于【传知代码】图像高清化(论文复现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






