本文主要是介绍汽车数据应用构想(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一直说数据价值场景,啥叫有价值?啥样的场景有价值?按互联网的价值观来看,用户的高频需求就是价值。用户也许不会付费,但只要他天天用,那就是流量,就是用户黏性,就是价值!!!
好了,那用户买车回家以后,最高频场景是啥?停车啊!加油一周一次、洗车两周一次、加玻璃水一月一次、保养半年一次、买保险一年一次……只有停车天天停,每次行程都得停车!
场景一:第一次去某个朋友家玩,对方把小区位置给你发过来,你会啥也不问直接导航过去吗?估计不会,多数人肯定还是要问一句:“车能进小区吗?附近哪儿能停车?”;
场景二:周末带全家去公园玩,本来把附近停车场景都看好了,结果人多出门墨迹,导致11点才到达,围着公园转了一大圈儿,发现全停满了。只能给住在附近的朋友打电话问:“附近哪儿还能停车?”;
场景三:去金融街开会,停车场费用太高,想到有个朋友就在金融街上班,打电话问他:“附近有没有哪个开放小区或闲置空地可以免费停车?”;
以上场景不是我编的,而是真实发生的,“一个朋友”不光知道哪儿能停,甚至还能知道更多细节:路边停车会不会被贴条?免费停车是不是容易被乱停的人挡住?是侧方位还是垂直车位?……总之,“一个朋友”总会知道最适合的停车地点!
“一个朋友”可以是你、是我、是他!每个人都有自己熟悉的地方,但这些信息,车也知道!熄火前的位置信息,必然就是停车位(路上意外不算哈),多个停车位在同一区域,这就是个停车场!
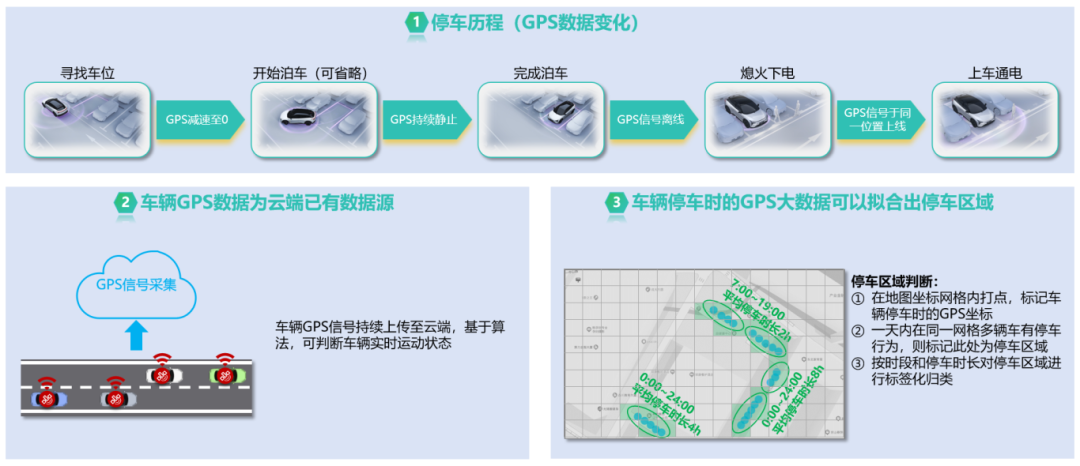
光知道哪儿有停车场就够了吗?那直接地图上找停车场不就完事儿了?用户的痛点到底是啥?看图!

那么通过车辆数据如何解决以上问题呢?今天不说废话,直接上干货,看图!
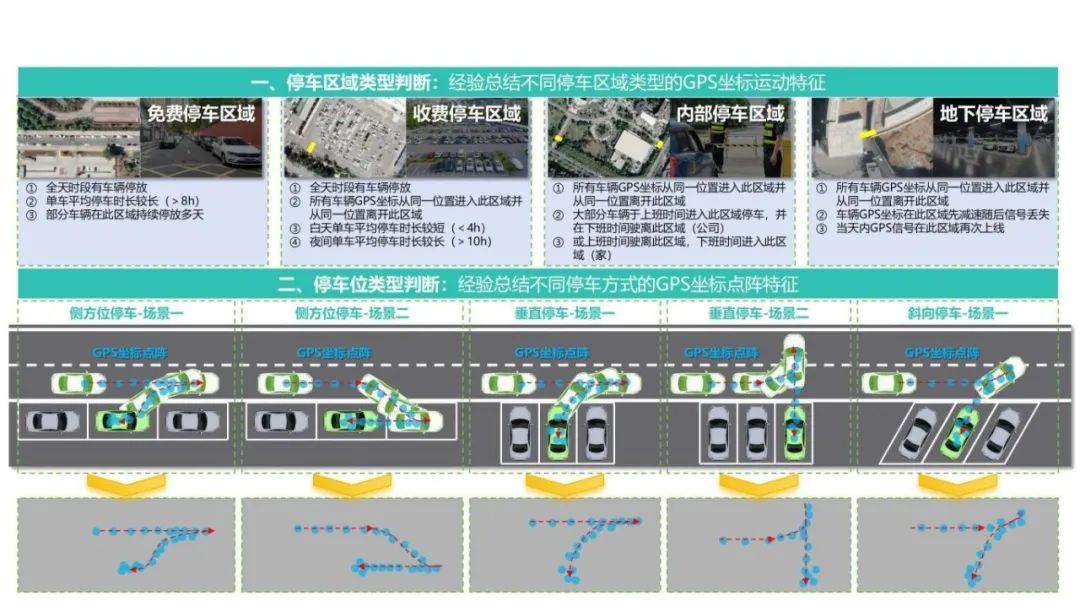
上面说的这些,都是比较普遍的“可视规律”,其实每个人对于停车还有很多自己的小心思:公司园区里,可以弹性工作时间,有些人来得早走得早,那么上班的时候,他选择车位通常是离自己楼门最近的位置,而且还要考虑下班的时候车不会被晚来的车辆给挡住;而晚来晚走的人呢,上班来的时候通常不会在自己楼附近浪费时间找车位,而是直接停到肯定有空位的区域;
这些都是长时间的实践中得到的经验,很多“规律”并不是产品经理一个人就可以想到的,那么大数据的特点正好可以在这里发挥:只看现象,不问因果!一辆长期早到公司的车,都停在同一个地方,那么下次某个人偶尔早到公司,那就直接也停在这个地方就好,前人的经验只要照着做就好!
本期内容所有精华都在图里了,不再多费口舌,下期聊聊充电、加油的场景吧。
文章首发于公众号:昊叔说车
原创不易,转载请告知原作者,注明出处。

这篇关于汽车数据应用构想(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






