本文主要是介绍Google力作 | Infini-attention无限长序列处理Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多文章,请关注微信公众号:NLP分享汇
原文链接:Google力作 | Infini-attention无限长序列处理Transformer![]() https://mp.weixin.qq.com/s?__biz=MzU1ODk1NDUzMw==&mid=2247485000&idx=1&sn=e44a7256bcb178df0d2cc9b33c6882a1&chksm=fc1fe702cb686e14b6ced5733b83e9838f933dee1df02a5bdf73c6575106d40fc580063390ac&token=1933560269&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzU1ODk1NDUzMw==&mid=2247485000&idx=1&sn=e44a7256bcb178df0d2cc9b33c6882a1&chksm=fc1fe702cb686e14b6ced5733b83e9838f933dee1df02a5bdf73c6575106d40fc580063390ac&token=1933560269&lang=zh_CN#rd

论文链接:https://arxiv.org/pdf/2404.07143.pdf
这篇论文的标题是《Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention》,作者是Tsendsuren Munkhdalai、Manaal Faruqui和Siddharth Gopal,来自Google。论文介绍了一种新的方法,可以将基于Transformer的大型语言模型(LLMs)扩展到无限长的输入,同时保持内存和计算资源的有界性。核心是一种名为Infini-attention的新型注意力机制。
摘要(Abstract)
-
论文提出了一种有效的方法,使得基于Transformer的大型语言模型能够处理无限长的输入序列,同时保持内存和计算资源的有界性。
-
介绍了Infini-attention,这是一种新的注意力技术,它在传统的注意力机制中加入了压缩记忆(compressive memory),并在单个Transformer块中集成了masked局部注意力和long-term线性注意力机制。
-
通过在长上下文语言建模基准、1M序列长度的密钥上下文块检索和500K长度的书籍摘要任务上的实验,证明了该方法的有效性。
-
该方法引入了最小化的有界内存参数,并使得大型语言模型能够进行快速的流式推理。
方法(Method)
-
论文比较了Infini-Transformer和Transformer-XL,并解释了Infini-Transformer是如何在每个段上计算标准的因果点积注意力上下文的。
-
介绍了Infini-attention的工作原理,包括局部注意力、压缩记忆、长期上下文注入等。
-
详细描述了压缩记忆的实现方式,包括记忆检索和更新过程。
-
讨论了Infini-Transformer如何通过压缩记忆和局部注意力状态的结合来输出最终的上下文。
Infini-attention
图1展示了Infini-attention的结构,它是一个用于处理无限长上下文的注意力机制。这个结构的核心在于它将压缩记忆(compressive memory)整合到了传统的注意力机制中,并在单个Transformer块内实现了局部注意力和长期线性注意力的结合。
图1还展示了Infini-attention与传统Transformer注意力机制的区别。在传统的Transformer中,随着序列长度的增加,注意力机制的内存占用和计算复杂度也会增加。而在Infini-attention中,通过压缩记忆的使用,可以有效地处理无限长的序列,同时保持内存占用和计算复杂度的有界性。
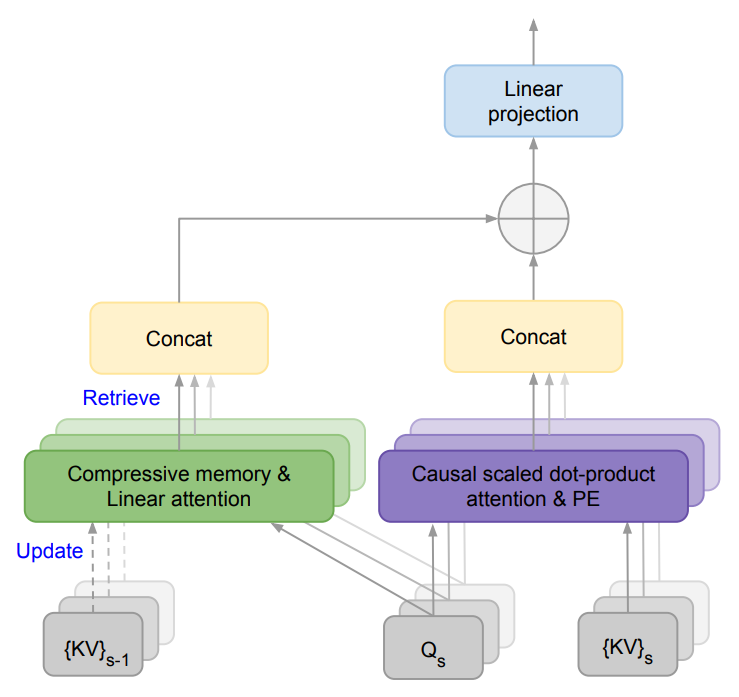
图1 Infini-attention
整体而言,图1揭示了Infini-attention如何通过结合压缩记忆和线性注意力机制,使得Transformer模型能够高效地处理长序列数据,同时保持计算资源的可管理性。
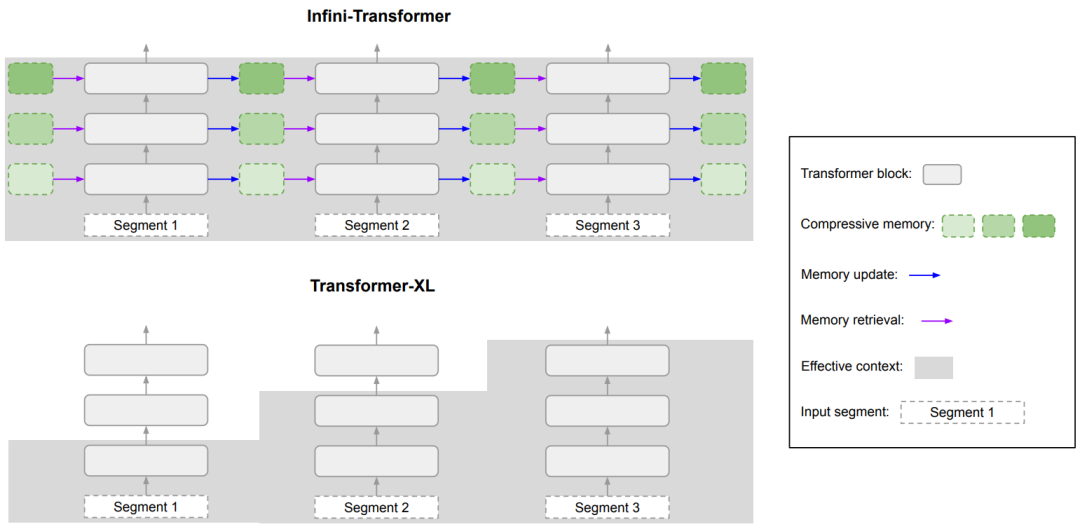
图2 Infini-Transformer vs Transformer-XL
图2比较了Infini-Transformer和Transformer-XL两种模型在处理长序列时对上下文信息的处理方式。这两种模型都操作于序列的段(segments),并且在每个段内计算因果点积注意力上下文。以下是图2中展示的主要组件和流程:
-
输入序列(Input segments)
-
输入序列被分割成多个段(segments),每个段包含一定数量的标记(tokens)。
-
-
注意力查询(Q)、键(K)和值(V)
-
对于每个输入段,都会计算出对应的查询(Q)、键(K)和值(V)向量。这些向量是通过输入序列与训练得到的投影矩阵(WQ、WK和WV)相乘得到的。
-
-
压缩记忆(Compressive memory)
-
压缩记忆是一个固定大小的存储结构,它用于存储和回忆过去的上下文信息。在Infini-attention中,压缩记忆通过关联矩阵(associative matrix)来参数化,这允许它以高效的方式更新和检索信息。
-
-
线性注意力(Linear attention)
-
线性注意力机制用于从压缩记忆中检索信息。它通过将当前的查询向量与压缩记忆的关联矩阵相乘来实现,从而得到长期记忆检索的值向量(Amem)。
-
-
记忆更新(Memory update)
-
当处理新的输入段时,会根据新的键和值向量更新压缩记忆。这个过程涉及到将新的记忆条目与旧的记忆条目结合,并更新关联矩阵。
-
-
长期上下文注入(Long-term context injection)
-
通过一个学习的门控标量(β),将局部注意力状态(Adot)和从压缩记忆中检索到的内容(Amem)结合起来,形成最终的上下文表示。
-
-
多头注意力(Multi-head attention)
-
多头注意力机制并行计算多个上下文状态,然后将这些状态连接起来,并通过一个投影矩阵(WO)转换为最终的注意力输出(O)。
-
图2强调了Infini-Transformer如何通过压缩记忆来维持整个序列的历史信息,这使得模型能够处理更长的上下文,而不仅仅是最近的段。这种结构允许Infini-Transformer在处理每个新的序列段时,都能够访问到之前的上下文信息,从而提高了模型处理长序列的能力。相比之下,Transformer-XL虽然通过缓存机制扩展了上下文窗口,但它的有效上下文长度仍然受限,因为它只保留了最近段的信息。这种对比展示了Infini-Transformer在处理长序列时的优势。
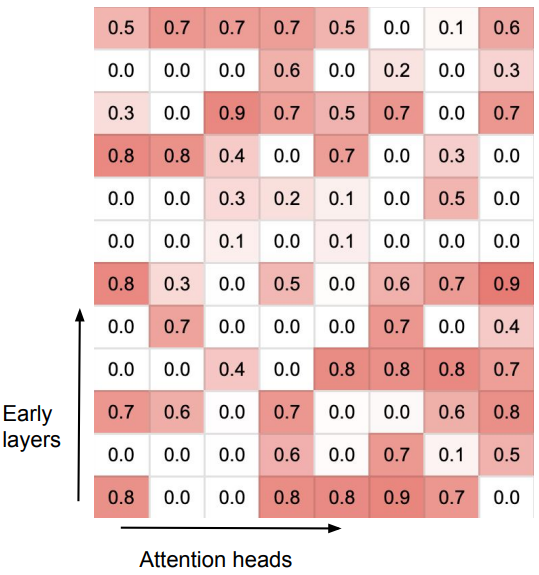
图3 gating score
图3在论文中展示了Infini-Transformer中使用Infini-attention机制训练后,注意力头(attention heads)的门控得分(gating score)分布情况。门控得分是通过sigmoid函数应用于学习的门控标量β得到的,用于控制在长短期信息流之间的平衡。
揭示了Infini-Transformer如何通过Infini-attention机制在模型内部学习和利用不同类型的注意力头,以适应长序列数据的处理。这种机制使得模型能够在保持有界内存和计算资源的同时,有效地处理和整合长期和短期的上下文信息。
实验结果(Experiments)
表1

表1在论文中列出了不同Transformer模型的内存占用(memory footprint)、上下文长度(context length)以及它们的记忆更新(memory update)和检索(memory retrieval)机制。这些模型都使用了段级别的记忆,即它们在处理长序列时会将输入分割成多个段,并在每个段上独立地应用注意力机制。
-
Transformer-XL
-
内存占用:N是输入段的长度,l是层数,H是注意力头的数量,dkey和dvalue分别是键和值的维度。
-
有效上下文长度:N × l,表示模型可以覆盖从当前段开始的N个标记以及前l个段的历史信息。
-
记忆更新和检索:Transformer-XL在每个层级上缓存最后一个段的键值状态,并在处理新段时丢弃旧的状态。
-
-
Compressive Transformer
-
内存占用:c是压缩记忆的大小,dmodel是模型的维度。
-
有效上下文长度:r是压缩比率。
-
记忆更新和检索:Compressive Transformer增加了一个压缩记忆缓存,用于存储过去段激活的压缩表示,从而扩展了上下文窗口。
-
-
Memorizing Transformers
-
内存占用:S是段的数量。
-
有效上下文长度:N × S,表示模型可以存储整个输入序列的键值状态。
-
记忆更新和检索:Memorizing Transformers存储整个序列的键值状态作为上下文,但由于存储成本很高,它们通常只使用单层注意力。
-
-
RMT (Recurrent Memory Transformer) 和 AutoCompressors
-
内存占用:p是软提示摘要向量的数量。
-
有效上下文长度:N × S,与Memorizing Transformers相同。
-
记忆更新和检索:这两种模型通过将输入压缩成摘要向量,并将其作为额外的软提示输入传递给后续段,从而允许潜在的无限上下文长度。但是,这些技术的成功率高度依赖于软提示向量的大小。
-
-
Infini-Transformers
-
内存占用:对于单层模型来说,内存复杂度是常数。
-
有效上下文长度:N × S,与上述模型相同,但内存占用显著减少。
-
记忆更新和检索:Infini-Transformer通过线性注意力和压缩记忆机制,以增量方式更新和检索固定数量的记忆参数。
-
表1突出了Infini-Transformer在内存效率方面的优势,它通过压缩记忆机制实现了对长序列的有效处理,同时保持了较低的内存占用。这使得Infini-Transformer在处理长序列任务时,如长上下文语言建模和书籍摘要,具有显著的性能优势。
表2

在长上下文语言建模任务中,不同模型之间的性能比较,特别是在平均token级困惑度(average token-level perplexity)方面的表现。困惑度是衡量语言模型预测序列中下一个词的不确定性的指标,困惑度越低,表示模型对数据的预测越准确,性能越好。表2中列出了几种不同的模型配置,并展示了它们在不同长度序列上的表现。
表2中的数据表明,Infini-Transformer在长上下文语言建模任务上取得了优于Transformer-XL和Memorizing Transformers的结果,同时保持了更低的内存占用。此外,Infini-Transformer的两种配置(线性和线性+Delta)都显示出了良好的性能,其中线性+Delta配置可能是指在线性注意力机制的基础上增加了Delta规则,以进一步优化记忆更新过程。这些结果强调了Infini-Transformer在处理长序列数据时的有效性和效率。
总结来说,Infini-Transformer在处理长上下文语言建模任务时,不仅在预测准确性上超越了Memorizing Transformers,而且还大幅提高了内存使用效率,实现了显著的压缩比。这表明Infini-Transformer是一种非常适合处理长文本序列的高效模型。
表3
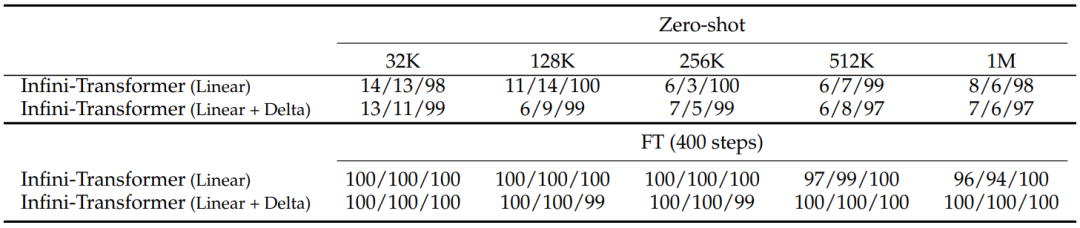
表3展示了Infini-Transformer在处理长序列的密钥检索任务时的性能。这个任务的目标是从一段很长的文本中检索出一个隐藏的密钥(passkey)。表中列出了不同模型配置在不同长度的输入序列上的表现,包括零次准确率(Zero-shot accuracy)和经过微调(Fine-tuning, FT)后的准确率。
表3中的数据表明,Infini-Transformer在处理长序列密钥检索任务时具有很好的性能,尤其是经过微调后,准确率得到了显著提升。此外,模型能够在不同位置准确地检索出密钥,这表明了其对长序列中信息的强大记忆和检索能力。这些结果进一步证实了Infini-Transformer在处理长序列任务方面的有效性。
表4
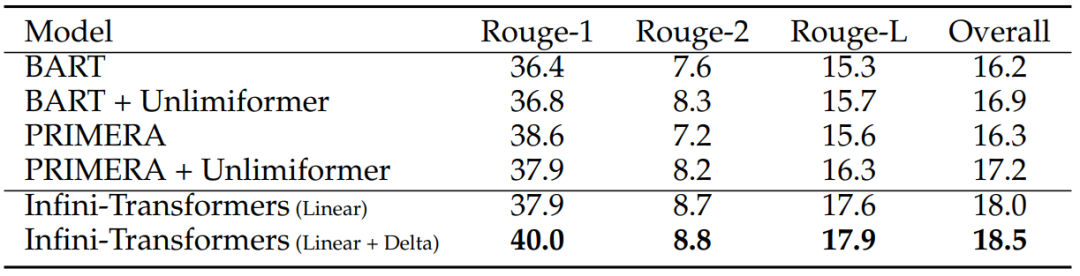
表4展示了Infini-Transformer在500K长度书籍摘要(BookSum)任务上的性能结果。这个任务的目标是生成一整本书的摘要。表中列出了不同模型的Rouge分数,这是一种常用的自然语言生成任务的评估指标,用于衡量生成文本与参考文本的重叠程度。Rouge分数越高,表示生成的摘要质量越好。表中比较了Infini-Transformer与其他几种模型的性能。
表4数据表明,Infini-Transformer在长序列的书籍摘要任务上具有很好的性能,能够生成高质量的摘要文本。此外,增加Delta规则的配置(Linear + Delta)在某些情况下能够进一步提升模型的性能。这些结果进一步证实了Infini-Transformer在处理长文本和生成任务方面的有效性和优越性。
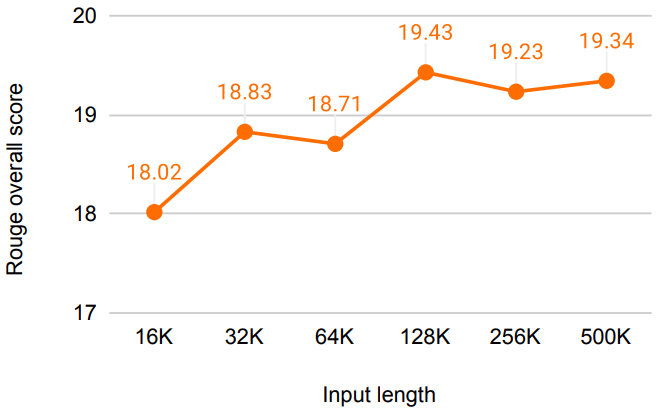
图5 输入长度对rouge分数影响
图5在论文中展示了Infini-Transformer在500K长度书籍摘要(BookSum)任务上的性能趋势,特别是在提供不同数量的书籍文本作为输入时的Rouge总分变化。Rouge总分是评估文本摘要质量的一个指标,它衡量生成摘要与参考摘要之间的重叠程度。
图5通过直观地展示了输入长度对模型性能的影响,强调了Infini-Transformer能够有效地利用大量输入文本信息来生成高质量的摘要。这种趋势也验证了Infini-attention机制在处理长序列数据时的有效性,特别是在需要理解和生成长文本内容的应用场景中。通过图4,我们可以得出结论,Infini-Transformer是一个强大的模型,适用于需要处理和生成长文本序列的任务。
这篇关于Google力作 | Infini-attention无限长序列处理Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




