本文主要是介绍Pytorch-Lighting使用教程(MNIST为例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、pytorch-lighting简介
1.1 pytorch-lighting是什么
pytorch-lighting(简称pl),基于 PyTorch 的框架。它的核心思想是,将学术代码(模型定义、前向 / 反向、优化器、验证等)与工程代码(for-loop,保存、tensorboard 日志、训练策略等)解耦开来,使得代码更为简洁清晰。
工程代码经常会出现在深度学习代码中,PyTorch Lightning 对这部分逻辑进行了封装,只需要在 Trainer 类中简单设置即可调用,无需重复造轮子。
1.2 pytorch-lighting优势
- 通过抽象出样板工程代码,可以更容易地识别和理解ML代码;
- Lightning的统一结构使得在现有项目的基础上进行构建和理解变得非常容易;
- Lightning 自动化的代码是用经过全面测试、定期维护并遵循ML最佳实践的高质量代码构建的;
pytorch-lighting最大的好处:
(1)是摆脱了硬件依赖,不需要在程序中显式设置.cuda() 等,PyTorch Lightning 会自动将模型、张量的设备放置在合适的设备;移除.train() 等代码,这也会自动切换
(2)支持分布式训练,自动分配资源,能够很好的进行大规模的DL训练
(3)代码量较少,只需要关心关键的逻辑代码,而框架性的东西,pytorch-lighting已经帮你解决(如自动训练,自动debug)
二、基于Pytorch-Lighting框架训练MNIST模型
1、仅仅训练
下载的所有的数据集都用于训练(没有评估和测试过程,不清楚模型的好与坏)。
# 1. 导入所需的模块
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import lightning.pytorch as pl# 2. 定义编码器和解码器
# 2.1 定义基础编码器Encoder
class Encoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(28 * 28, 64), nn.ReLU(), nn.Linear(64, 3))def forward(self, x):return self.l1(x)# 2.2 定义基础解码器Decoder
class Decoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(3, 64), nn.ReLU(), nn.Linear(64, 28 * 28))def forward(self, x):return self.l1(x)# 3. 定义LightningModule
class LitAutoEncoder(pl.LightningModule):# 3.1 加载基础模型def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoder# 3.2 训练过程设置def training_step(self, batch, batch_idx): # 每一个batch数据运算计算loss# training_step defines the train loop.x, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)loss = F.mse_loss(x_hat, x)return loss# 3.3 优化器设置def configure_optimizers(self):optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)return optimizer# 4. 定义训练数据
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train_loader = DataLoader(dataset)# 5. 实例化模型
autoencoder = LitAutoEncoder(Encoder(), Decoder())# 6. 开始训练
trainer = pl.Trainer(max_epochs=10)
trainer.fit(model=autoencoder, train_dataloaders=train_loader)class LitAutoEncoder(pl.LightningModule):
- 将模型定义代码写在
__init__中- 定义前向传播逻辑
- 将优化器代码写在
configure_optimizers钩子中- 训练代码写在
training_step钩子中,可使用self.log随时记录变量的值,会保存在 tensorboard 中- 验证代码写在
validation_step钩子中- 移除硬件调用
.cuda()等,PyTorch Lightning 会自动将模型、张量的设备放置在合适的设备;移除.train()等代码,这也会自动切换- 根据需要,重写其他钩子函数,例如
validation_epoch_end,对validation_step的结果进行汇总;train_dataloader,定义训练数据的加载逻辑- 实例化 Lightning Module 和 Trainer 对象,传入数据集
- 定义训练参数和回调函数,例如训练设备、数量、保存策略,Early Stop、半精度等
运行结果:
2、添加验证和测试模块
在训练之后,加入了测试和评估功能,能更好的指导模型的性能。
# 1. 导入所需的模块
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import lightning.pytorch as plimport torch.utils.data as data
from torchvision import datasets
import torchvision.transforms as transformsfrom torch.utils.data import DataLoader# 2. 定义编码器和解码器
# 2.1 定义基础编码器Encoder
class Encoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(28 * 28, 64), nn.ReLU(), nn.Linear(64, 3))def forward(self, x):return self.l1(x)# 2.2 定义基础解码器Decoder
class Decoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(3, 64), nn.ReLU(), nn.Linear(64, 28 * 28))def forward(self, x):return self.l1(x)# 3. 定义LightningModule
class LitAutoEncoder(pl.LightningModule):# 3.1 加载基础模型def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoder# 3.2 训练过程设置def training_step(self, batch, batch_idx): # 每一个batch数据运算计算loss# training_step defines the train loop.x, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)loss = F.mse_loss(x_hat, x)return loss# 3.3 测试过程设置def test_step(self, batch, batch_idx):# this is the test loopx, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)test_loss = F.mse_loss(x_hat, x)self.log("test_loss", test_loss)# 3.4 验证过程设置def validation_step(self, batch, batch_idx):# this is the validation loopx, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)val_loss = F.mse_loss(x_hat, x)self.log("val_loss", val_loss)# 3.5 优化器设置def configure_optimizers(self):optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)return optimizer# 4. 定义训练数据
'''
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train_loader = DataLoader(dataset)
'''# 4.1 分别下载并加载训练集和测试集
transform = transforms.ToTensor()
train_set = datasets.MNIST(os.getcwd(), download=False, train=True, transform=transform)
test_set = datasets.MNIST(os.getcwd(), download=False, train=False, transform=transform)# 4.2 将训练集中的20%用于验证集
train_set_size = int(len(train_set) * 0.8)
valid_set_size = len(train_set) - train_set_size# 4.3 设置种子
seed = torch.Generator().manual_seed(42)# 4.4 从训练集中随机拿到80%的测试集和20%的验证集
train_set, valid_set = data.random_split(train_set, [train_set_size, valid_set_size], generator=seed)# 4.5 分别加载训练集和测试集
train_loader = DataLoader(train_set)
valid_loader = DataLoader(valid_set)# 5. 实例化模型
autoencoder = LitAutoEncoder(Encoder(), Decoder())# 6. 实例化Trainer
trainer = pl.Trainer(max_epochs=10)# 7. 开始训练和评估
trainer.fit(autoencoder, train_loader, valid_loader)# 8.开始测试
trainer.test(model=autoencoder, dataloaders=DataLoader(test_set))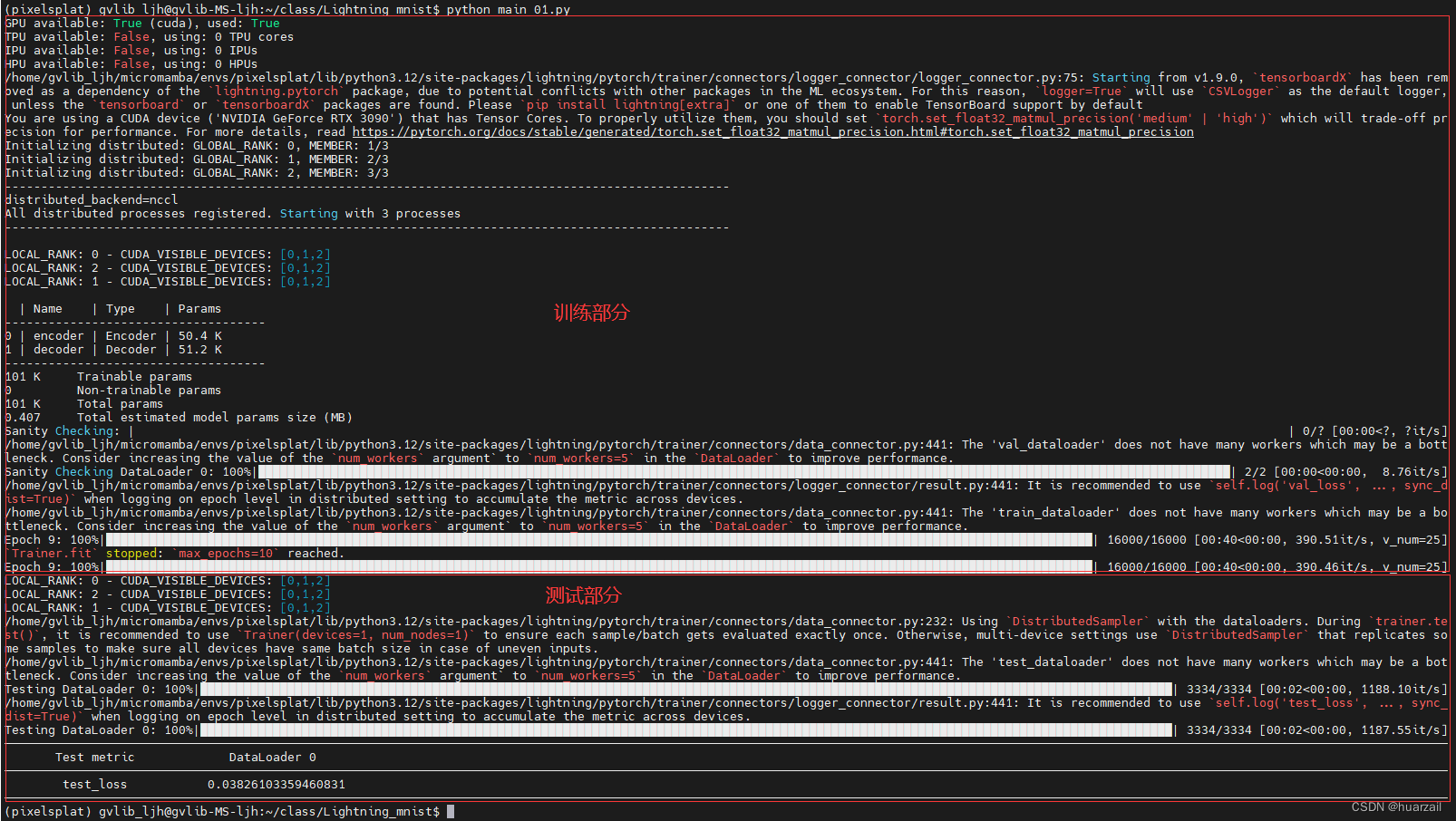
3、权重 & 超参的保存和加载
当模型正在训练时,性能会随着它继续看到更多数据而发生变化。
1)训练完成后,使用在训练过程中发现的最佳性能相对应的权重;
2)权重可以让训练在训练过程中断的情况下从原来的位置恢复。
保存权重:Lightning 会自动为你在当前工作目录下保存一个权重,其中包含上一次训练的状态。这能确保在训练中断的情况下恢复训练。
3.1 自动在当前目录下保存checkpoint
# simply by using the Trainer you get automatic checkpointing
trainer = Trainer()3.2 指定checkpoint保存的目录
# saves checkpoints to 'some/path/' at every epoch end
trainer = Trainer(default_root_dir="some/path/")3.3 加载checkpoint
# trainer.fit(autoencoder, train_loader, valid_loader, ckpt_path="/home/gvlib_ljh/class/Lightning_mnist/lightning_logs/version_25/checkpoints/epoch=9-step=160000.ckpt")4、可视化
在模型开发中,我们跟踪感兴趣的值,例如validation_loss,以可视化模型的学习过程。模型开发就像驾驶一辆没有窗户的汽车,图表和日志提供了了解汽车行驶方向的窗口。借助 Lightning,可以可视化任何您能想到的东西:数字、文本、图像、音频。
要跟踪指标,只需使用 LightningModule 内可用的 self.log 方法。
class LitModel(pl.LightningModule):def training_step(self, batch, batch_idx):value = ...self.log("some_value", value)同时记录多个指标:
values = {"loss": loss, "acc": acc, "metric_n": metric_n} # add more items if needed
self.log_dict(values)4.1 命令行查看
要在命令行进度栏中查看指标,请将 prog_bar 参数设置为 True。
self.log(..., prog_bar=True)4.2 浏览器查看
默认情况下,Lightning 使用 Tensorboard(如果可用)和一个简单的 CSV 记录器
在命令行中输入(注意:一定是lightning_logs所在的目录):
tensorboard --logdir=lightning_logs/Tensorboard界面:

Tensorboard输出分析:
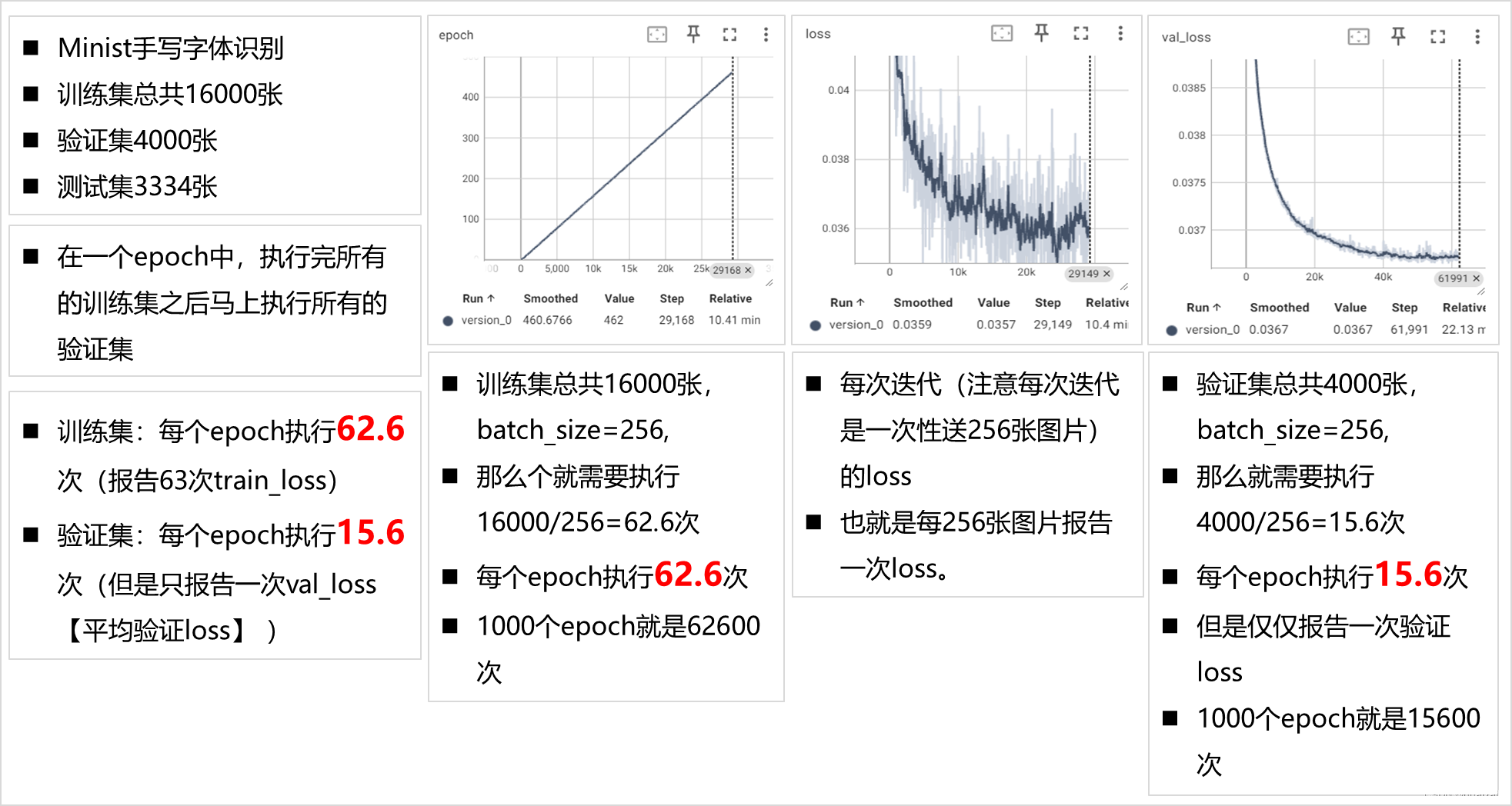
完整的代码:
# 1. 导入所需的模块
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import lightning.pytorch as plimport torch.utils.data as data
from torchvision import datasets
import torchvision.transforms as transformsfrom torch.utils.data import DataLoaderfrom pytorch_lightning.loggers import TensorBoardLogger# 设置浮点矩阵乘法精度为 'medium'
torch.set_float32_matmul_precision('medium')# 2. 定义编码器和解码器
# 2.1 定义基础编码器Encoder
class Encoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(28 * 28, 64), nn.ReLU(), nn.Linear(64, 3))def forward(self, x):return self.l1(x)# 2.2 定义基础解码器Decoder
class Decoder(nn.Module):def __init__(self):super().__init__()self.l1 = nn.Sequential(nn.Linear(3, 64), nn.ReLU(), nn.Linear(64, 28 * 28))def forward(self, x):return self.l1(x)# 3. 定义LightningModule
class LitAutoEncoder(pl.LightningModule):# 3.1 加载基础模型def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoder# 3.2 训练过程设置def training_step(self, batch, batch_idx): # 每一个batch数据运算计算loss# training_step defines the train loop.x, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)loss = F.mse_loss(x_hat, x)batch_idx_value = batch_idx + 1print(" ")values = {"loss": loss, "batch_idx_value": batch_idx_value} # add more items if neededself.log_dict(values)# 在命令行界面显示log'''sync_dist=True:分布式计算,数据同步标志prog_bar=True:在控制台上显示'''self.log("train_loss", loss, sync_dist=True, prog_bar=True)return loss# 3.3 测试过程设置def test_step(self, batch, batch_idx):x, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)test_loss = F.mse_loss(x_hat, x)self.log("test_loss", test_loss, sync_dist=True, prog_bar=True)# 3.4 验证过程设置def validation_step(self, batch, batch_idx):# this is the validation loopx, y = batchx = x.view(x.size(0), -1)z = self.encoder(x)x_hat = self.decoder(z)val_loss = F.mse_loss(x_hat, x)self.log("val_loss", val_loss, sync_dist=True, prog_bar=True)# 3.5 优化器设置def configure_optimizers(self):optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)return optimizer# 4. 定义训练数据
'''
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train_loader = DataLoader(dataset)
'''# 4.1 分别下载并加载训练集和测试集
transform = transforms.ToTensor()
train_set = datasets.MNIST(os.getcwd(), download=False, train=True, transform=transform)
test_set = datasets.MNIST(os.getcwd(), download=False, train=False, transform=transform)# 4.2 将训练集中的20%用于验证集
train_set_size = int(len(train_set) * 0.8)
valid_set_size = len(train_set) - train_set_size# 4.3 设置种子
seed = torch.Generator().manual_seed(42)# 4.4 从训练集中随机拿到80%的测试集和20%的验证集
train_set, valid_set = data.random_split(train_set, [train_set_size, valid_set_size], generator=seed)# 4.5 分别加载训练集和测试集
train_loader = DataLoader(train_set, batch_size=256, num_workers=5)
valid_loader = DataLoader(valid_set, batch_size=128, num_workers=5)# 5. 实例化模型
autoencoder = LitAutoEncoder(Encoder(), Decoder())# 6. 实例化Trainer
trainer = pl.Trainer(max_epochs=1000)# 7. 开始训练和评估
trainer.fit(autoencoder, train_loader, valid_loader)
# 7. 从checkpoint恢复状态
# trainer.fit(autoencoder, train_loader, valid_loader, ckpt_path="/home/gvlib_ljh/class/Lightning_mnist/lightning_logs/version_25/checkpoints/epoch=9-step=160000.ckpt")# 8.开始测试
trainer.test(model=autoencoder, dataloaders=DataLoader(test_set))参考:
https://zhuanlan.zhihu.com/p/659631467
这篇关于Pytorch-Lighting使用教程(MNIST为例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






