本文主要是介绍摸鱼大数据——Hive函数7-9,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
7、日期时间函数
Hive函数链接:LanguageManual UDF - Apache Hive - Apache Software Foundation
SimpleDateFormat (Java Platform SE 8 )
current_timestamp: 获取时间原点到现在的秒/毫秒,底层自动转换方便查看的日期格式 常用 to_date: 字符串格式时间戳转日期(年月日) current_date: 获取当前日期(年月日) 常用 year: 获取指定日期时间中的年 常用 month:获取指定日期时间中的月 常用 day:获取指定日期时间中的日 常用 hour:获取指定日期时间中的时 minute:获取指定日期时间中的分 second:获取指定日期时间中的秒 dayofmonth: 获取指定日期时间中的月中第几天 dayofweek:获取指定日期时间中的周中第几天 quarter:获取指定日期时间中的所属季度 weekofyear:获取指定日期时间中的年中第几周 datediff: 获取两个指定时间的差值 常用 date_add: 在指定日期时间上加几天 常用 date_sub: 在指定日期时间上减几天 unix_timestamp: 获取unix时间戳(时间原点到现在的秒/毫秒) 注意: 可以使用yyyyMMdd HH:mm:ss进行格式化转换 from_unixtime: 把unix时间戳转换为日期格式的时间 注意: 如果传入的参数是0,获取的是时间原点1970-01-01 00:00:00
示例:
select`current_date`(), -- 获取当前的日期`current_timestamp`(); -- 获取当前的日期时间
-- to_date:将字符串内容转成日期对象
select to_date("2024-04-25");
select to_date("2024-04-25 16:39:30");
-- 年月日时分秒分别获取
selectyear("2024-04-25 16:39:30") as my_year,month("2024-04-25 16:39:30") as my_month,day("2024-04-25 16:39:30") as my_day,dayofweek("2024-04-25 16:39:30") as dw1, -- 返回值是5。因为周日是1,周日 周一 周二 ... 周六dayofweek("2024-04-28 16:39:30") as dw2, -- 返回值是1。因为周日是1,周日 周一 周二 ... 周六hour("2024-04-25 16:39:30") as my_hour,minute("2024-04-25 16:39:30") as my_minute,second("2024-04-25 16:39:30") as my_second;
-- 日期时间的加减
/*datediff(大的日期,小的日期):计算两个日期的天差值*/
selectdatediff("2024-04-24 16:39:30","2024-04-25 16:39:30") as `差值1`, -- 去公司里面不要用中文datediff("2024-04-24 16:39:10","2024-04-25 16:39:30") as `差值2`, -- 去公司里面不要用中文datediff("2024-03-25 16:39:10","2024-04-25 16:39:30") as `差值3`, -- 去公司里面不要用中文datediff("2023-03-25 16:39:10","2024-04-25 16:39:30") as `差值4`, -- 去公司里面不要用中文date_add("2024-04-25 16:39:30",1) as add1,date_add("2024-04-25 16:39:30",-1) as add2,date_sub("2024-04-25 16:39:30",1) as sub1,date_sub("2024-04-25 16:39:30",-1) as sub2;
-- unix_timestamp:获取当前的时间戳
select unix_timestamp(),`current_timestamp`();
-- from_unixtime:将时间戳转成日期对象
select from_unixtime(1714035105),from_utc_timestamp(1714035105,"PRC");
-- 需求:将这个时间日期4/25/2024 17:08:20变成中国喜欢用的。2024-04-25 17:08:20
-- 旧的日期时间 -> 时间戳 -> 新格式的日期时间
describe function extended unix_timestamp;
describe function extended from_unixtime;
selectunix_timestamp("4/25/2024 17:08:20","M/dd/yyyy HH:mm:ss"),-- 旧的日期时间 -> 时间戳from_unixtime(unix_timestamp("4/25/2024 17:08:20","M/dd/yyyy HH:mm:ss"),"yyyy-MM-dd HH:mm:ss") -- 时间戳 -> 新格式的日期时间
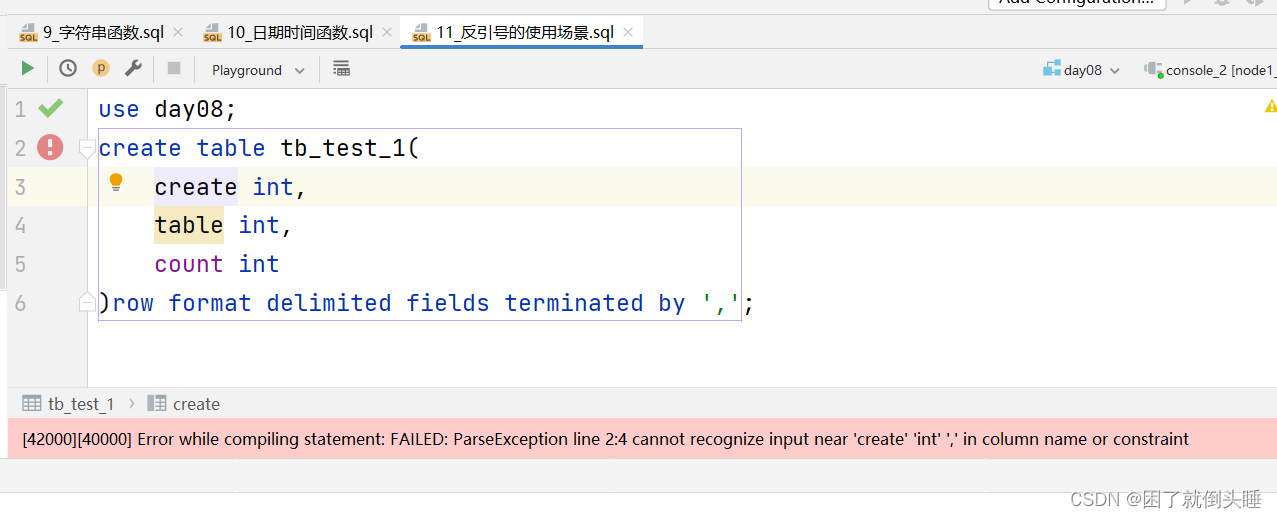
原因: 建表的时候,字段名称或者表名称最好不要和hive中的关键字(系统内部自己用的,例如:create、count、sum、max等)重名 解决办法:1- 推荐取个不一样的名词2- 加上反引号``
use day08; create table tb_test_1(`create` int,`table` int,count int )row format delimited fields terminated by ','; select count(count) from tb_test_1;
8、条件函数
if(参数1,参数2,参数3): if(判断条件,条件成立(true)的时候执行,条件不成立(false)的时候执行)。if可以嵌套 case...when.then...end: 分条件判断 使用推荐: 如果判断比较简单推荐使用if,如果判断条件很多推荐使用case when isnull(数据) : 判断是否为空。如果为空(null值)返回true;否则返回false。 注意: null才是空值。空字符串不是空值 isnotnull(数据): 判断是否不为空。如果为空(null值)返回false;否则返回true。 nvl(数据,参数2): 返回里面第一个不为空的值 coalesce(参数1,参数2...): 返回里面第一个不为空的值
示例:
-- if(判断条件,条件成立(true)的时候执行,条件不成立(false)的时候执行)。if可以嵌套
selectif(20>18,"可以去上网","回家写作业"),if(10>18,"可以去上网","回家写作业"),if(10>18,null,"回家写作业"),if(10>18,"可以去上网",null),if(10>18,"可以去上网",if(10<15,"写小学作业","写初中作业")); -- if嵌套
-- isnull和isnotnull:返回true和false
select isnull(null),isnull("hello"),isnull(123),isnotnull("hello"),isnotnull(null);
-- nvl(字段名,默认值)
select nvl("hello",123),nvl(null,"world"),nvl(19.99,123);
-- coalesce(字段1,字段2,....):返回参数列表中第一个不为空null的值
selectcoalesce("hello","world",123,9.99),coalesce(null,"world",123,9.99),coalesce(null,null,123,9.99),coalesce(null,null,null,9.99),coalesce(null,"world",null,9.99);
-- case when
select1 as today,casewhen 4==1 then "周一"when 4==2 then "周二"when 4==3 then "周三"else "休息"end,
case 4when 1 then "周一"when 2 then "周二"when 3 then "周三"else "休息"end;
9、其他函数
-- hash:使用场景,用来对hive数据进行完整性校验。
select hash("world"); -- 113318802
-- md5
select md5("world"); -- 7d793037a0760186574b0282f2f435e7
select md5(concat_ws("_",cast(1 as string),"zhangshan",cast(18 as string),cast(50000 as string),"广州市"));
select current_user(),current_database(),version();
select sha2("allen",224);
select sha2("allen",512);
这篇关于摸鱼大数据——Hive函数7-9的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





