本文主要是介绍【从零开始学爬虫】通过新浪财经采集上市公司高管信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
l 采集网站
【场景描述】采集新浪财经所有行业板块中上市公司的高管信息。
【源网站介绍】
新浪财经,提供7X24小时财经资讯及全球金融市场报价,覆盖股票、债券、基金、期货、信托、理财、管理等多种面向个人和企业的服务。
【使用工具】前嗅ForeSpider数据采集系统,点击下方链接可免费下载
http://www.forenose.com/view/forespider/view/download.html
【入口网址】
http://finance.sina.com.cn/stock/sl/#sinaindustry_1
【采集内容】
采集新浪财经所有行业板块中上市公司的高管信息。
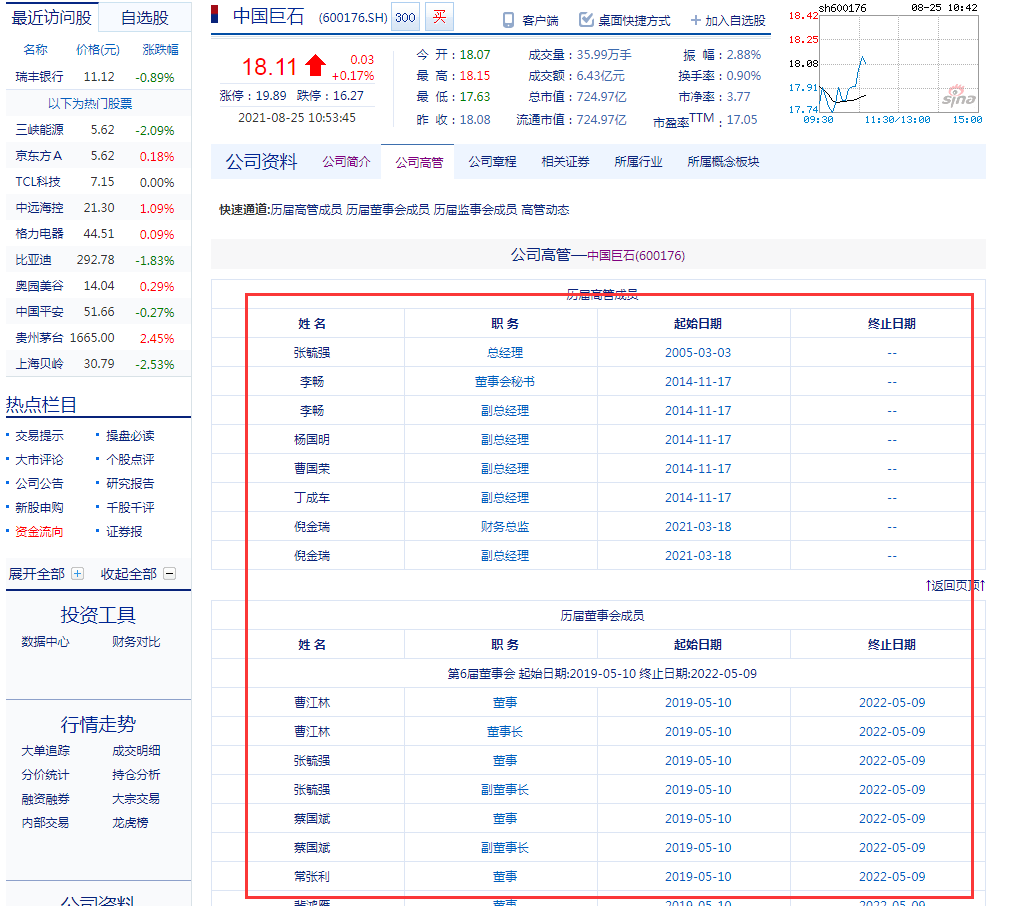
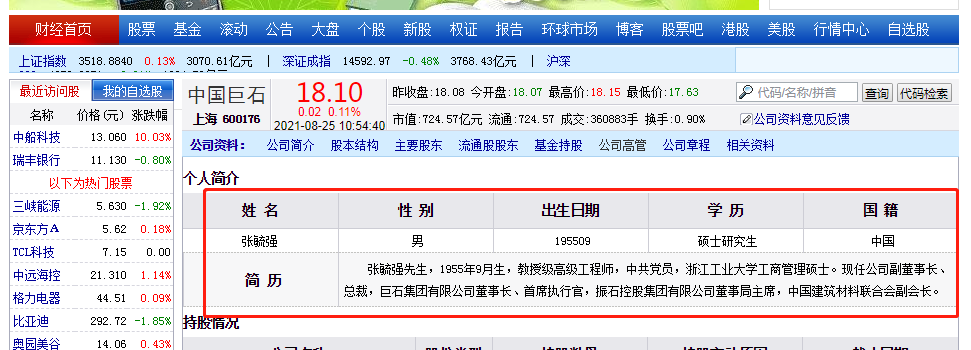
【采集效果】如下图所示:

l 思路分析
配置思路概览:

l 配置步骤
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
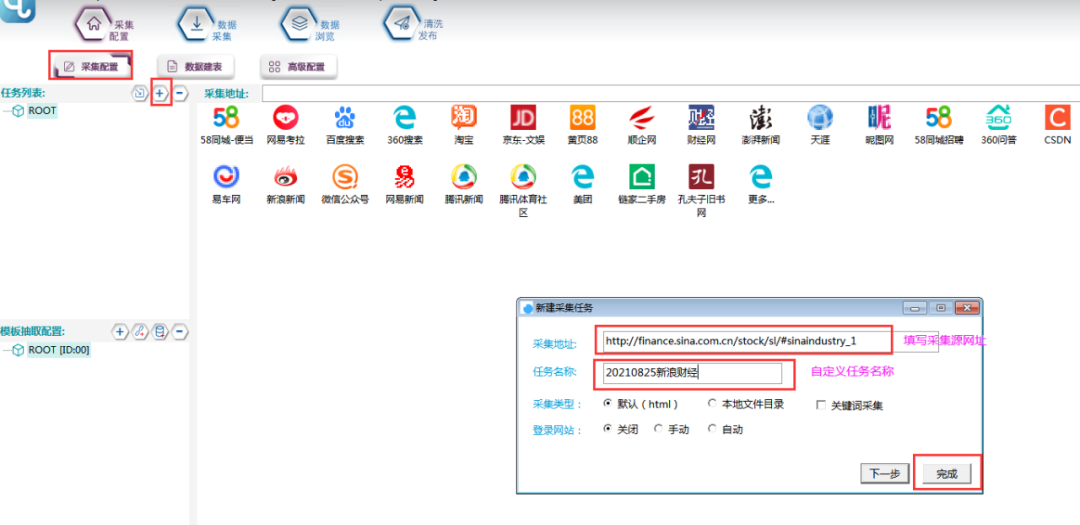
选择列表链接,点击完成按钮,即创建任务完成。
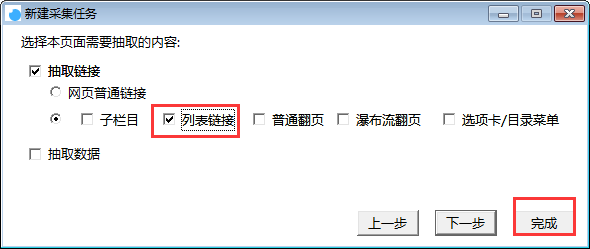
2.获取行业链接
①用浏览器打开该网页,查看各行业的链接规律,发现行业链接规律为:http://vip.stock.finance.sina.com.cn/mkt/#new_+行业名称首字母
比如:
http://vip.stock.finance.sina.com.cn/mkt/#new_cbzz (船舶制造)
http://vip.stock.finance.sina.com.cn/mkt/#new_tchy (陶瓷行业)
②所以获取行业链接的方法为:将各行业关键词的首字母设置为关键词,用脚本拼接行业链接。
③设置关键词,具体步骤如下所示:
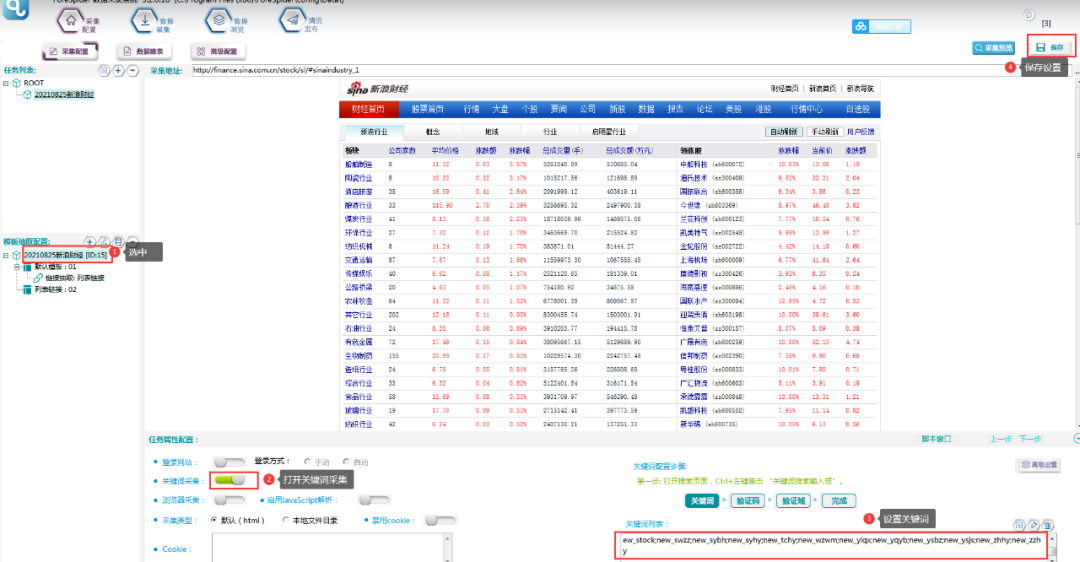
关键词文本如下:
new_blhy;new_cbzz;new_cmyl;new_dlhy;new_dqhy;new_dzqj;new_dzxx;new_fdc;new_fdsb;new_fjzz;new_fzhy;new_fzjx;new_fzxl;new_glql;new_gsgq;new_gthy;new_hbhy;new_hghy;new_hqhy;new_jdhy;new_jdly;new_jjhy;new_jrhy;new_jtys;new_jxhy;new_jzjc;new_kfq;new_ljhy;new_mtc;new_mthy;new_nlmy;new_nyhf;new_qczz;new_qtxy;new_slzp;new_snhy;new_sphy;new_stock;new_swzz;new_sybh;new_syhy;new_tchy;new_wzwm;new_ylqx;new_yqyb;new_ysbz;new_ysjs;new_zhhy;new_zzhy
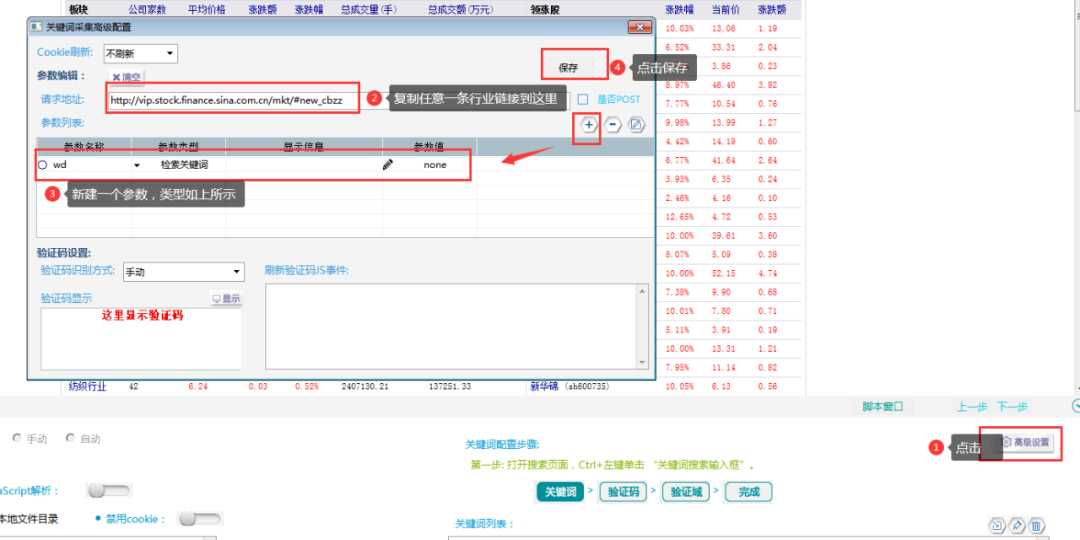
④高级设置,设置一个关键词参数,具体操作如下图所示:
⑤编写关键词拼写链接的脚本:
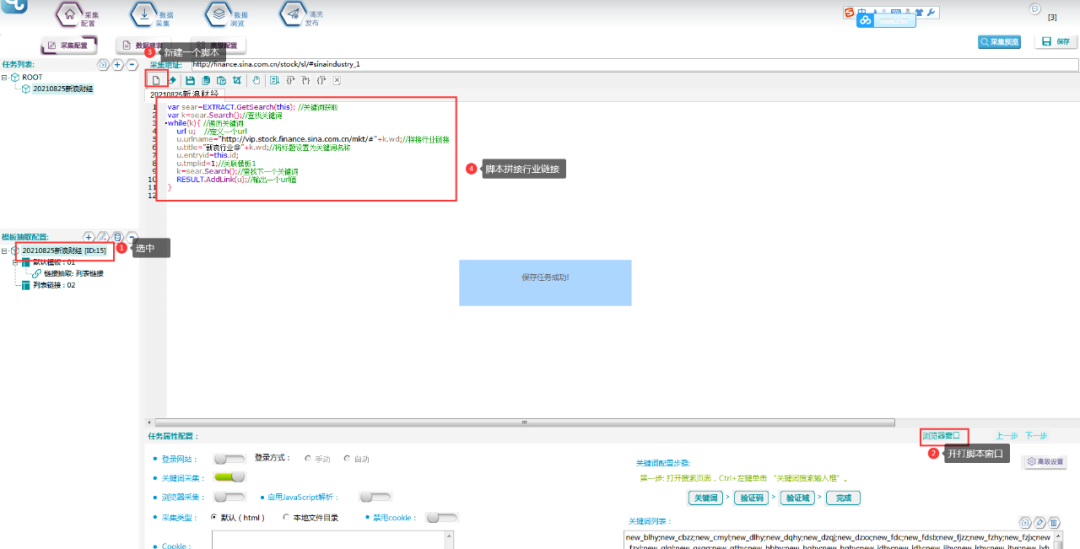
具体脚本文本如下:
var sear=EXTRACT.GetSearch(this); //关键词获取
var k=sear.Search();//查找关键词
while(k){ //遍历关键词
url u;//定义一个url
u.urlname="http://vip.stock.finance.sina.com.cn/mkt/#"+k.wd;//拼接行业链接
u.title="新浪行业@"+k.wd;//将标题设置为关键词名称
u.entryid=this.id;
u.tmplid=1;//关联模板1
k=sear.Search();//查找下一个关键词
RESULT.AddLink(u);//输出一个url值
}
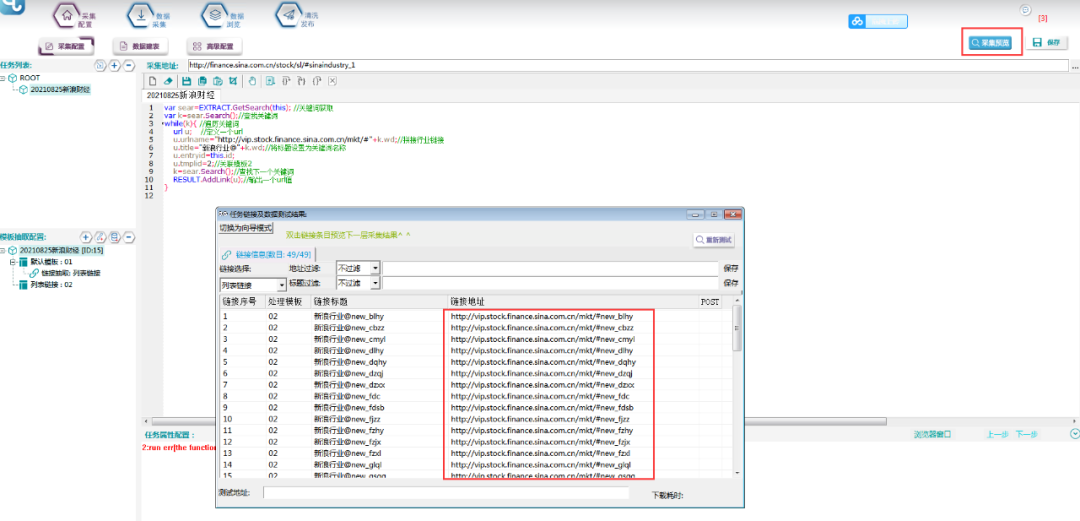
⑥采集预览,查看行业链接是否正确。
3. 获取翻页链接
①观察发现,有部分行业数据量比较大,有多页数据,需要翻页。
打开【其他行业】板块,发现4页数据,点击F12,右侧出现请求,点击第二页,观察发现请求:是翻页请求链接。如下图所示
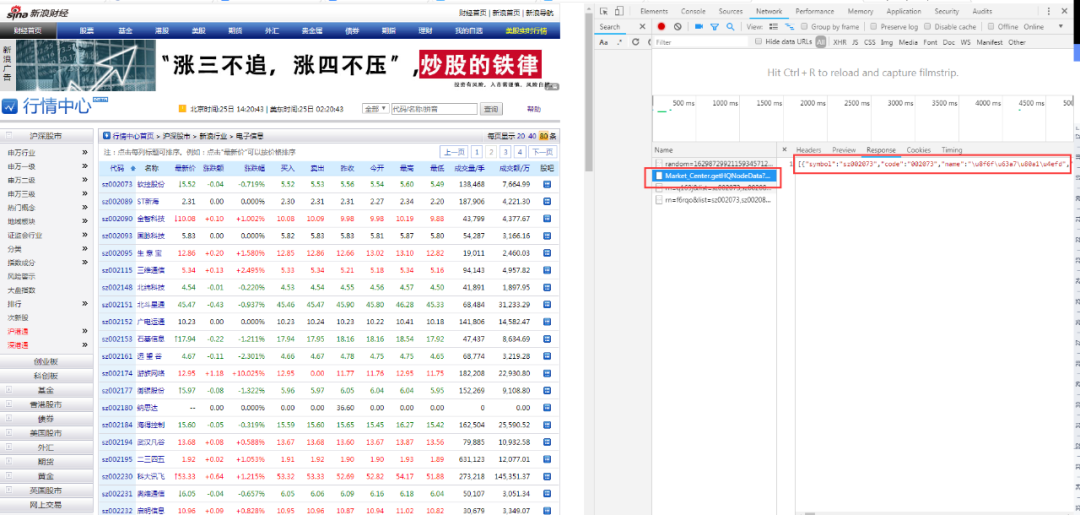
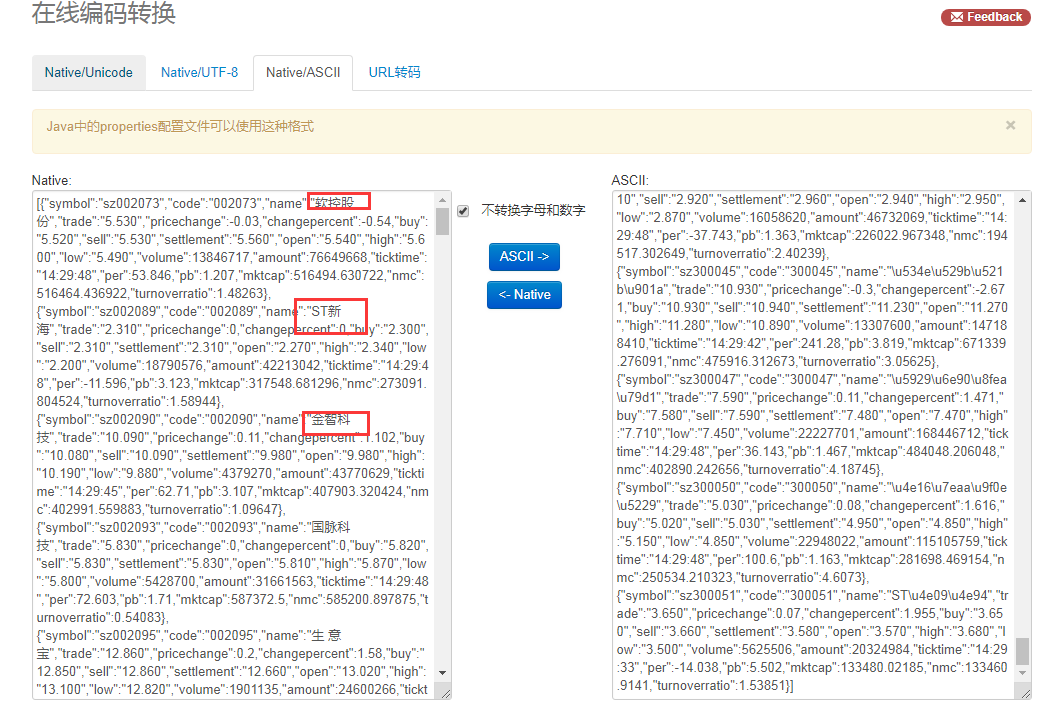
补充:下图为请求response转译后内容,可看出其中有第二页中的内容,故确定此链接为翻页请求链接。
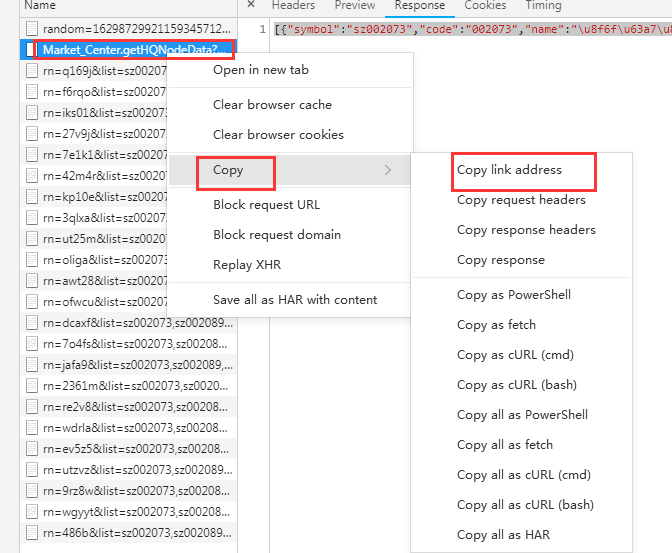
②复制翻页请求链接:
③同样方法,找到第三页和第四页请求链接,并复制出来。
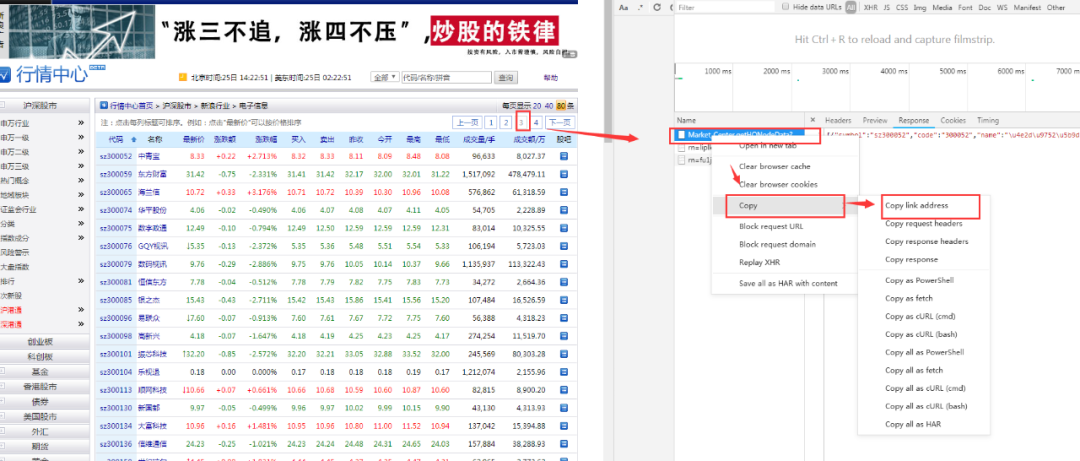
④观察链接,发现规律如下图所示:

⑤写翻页链接脚本,具体操作如下所示:
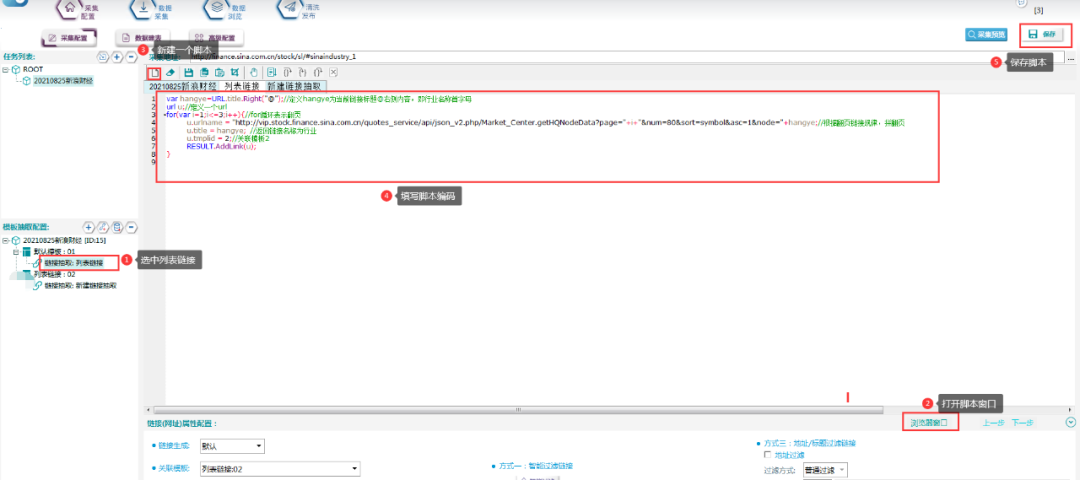
脚本文本:
var hangye=URL.title.Right("@");//定义hangye为当前链接标题@右侧内容,即行业名称首字母
url u;//定义一个url
for(var i=1;i<=3;i++){//for循环表示翻页
u.urlname = "http://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page="+i+"&num=80&sort=symbol&asc=1&node="+hangye;//根据翻页链接规律,拼翻页
u.title = hangye; //返回链接名称为行业
u.tmplid = 2;//关联模板2
RESULT.AddLink(u);
}
⑥采集预览,如下图所示,表示翻页链接已生成。
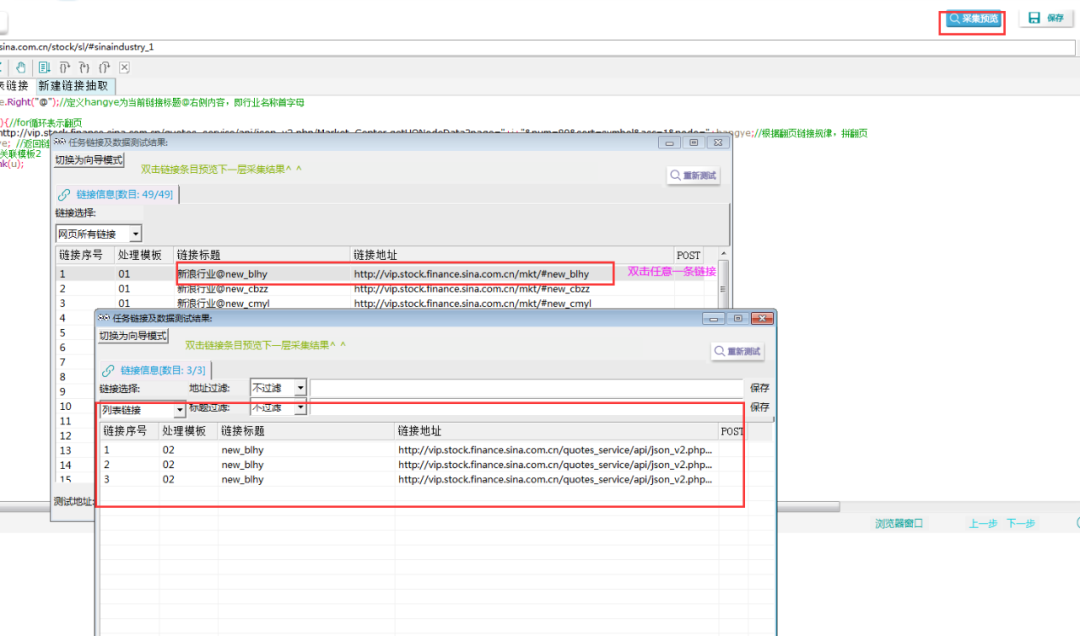
4. 采集公司链接
①在浏览器中打开几个公司链接,可发现规律为:

②而公司id则在模板01获取到的翻页链接请求中,采集预览,在浏览器中打开任意一个翻页请求,经观察发现,这是一个json,公司id为每个对象的symbol值。

③新建模板02,并在其下新建一个链接抽取
④脚本如下所示:
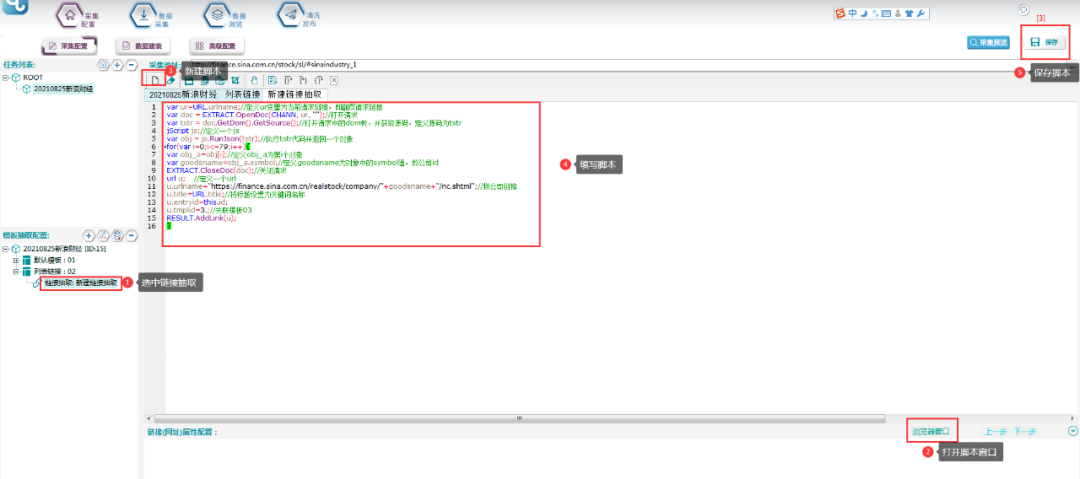
脚本文本:
var ur=URL.urlname;//定义ur变量为当前请求链接,即翻页请求链接
var doc = EXTRACT.OpenDoc(CHANN, ur, "");//打开请求
var tstr = doc.GetDom().GetSource();//打开请求中的dom树,并获取源码,定义源码为tstr
jScript js;//定义一个js
var obj = js.RunJson(tstr);//执行tstr代码并返回一个对象
for(var i=0;i<=79;i++){
var obj_a=obj[i];//定义obj_a为第i个对象
var goodsname=obj_a.symbol;
EXTRACT.CloseDoc(doc);//关闭请求
url u;
u.urlname="https://finance.sina.com.cn/realstock/company/"+goodsname+"/nc.shtml";//拼公司链接
u.title=URL.title;//将标题设置为关键词名称
u.entryid=this.id;//定义goodsname为对象中的symbol值,即公司id
u.tmplid=3;//关联模板03
RESULT.AddLink(u);
}
⑤点击采集预览,如下所示:
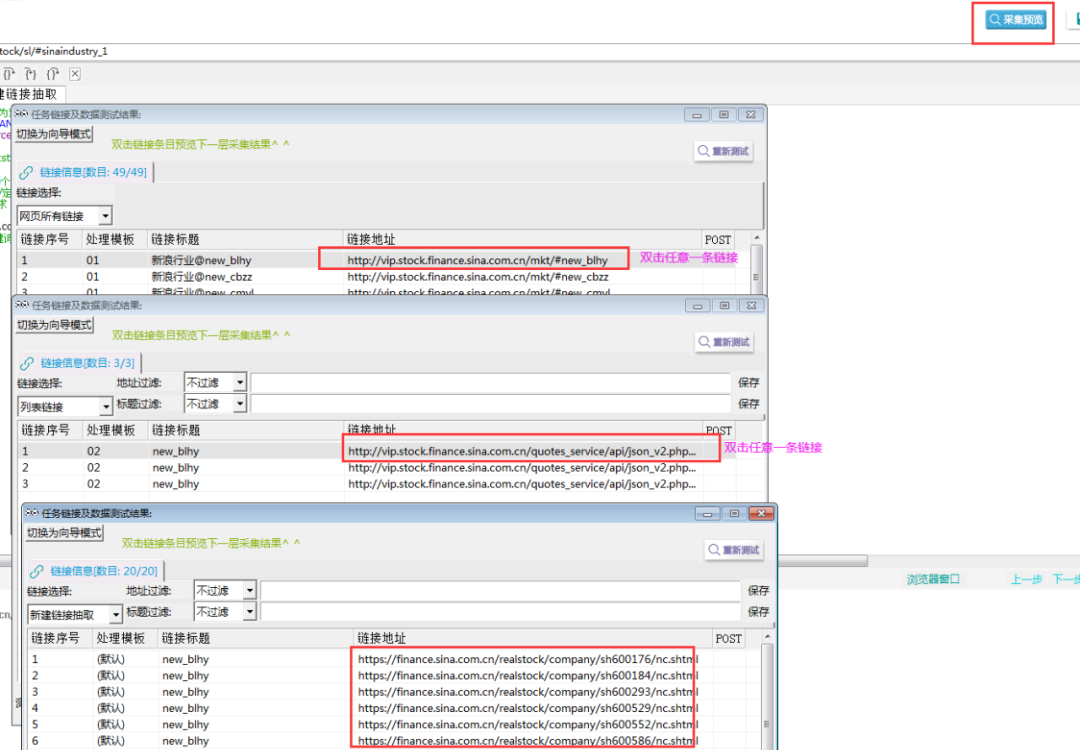
5. 抽取公司高管链接
①新建一层模板03,并新建一个链接抽取。
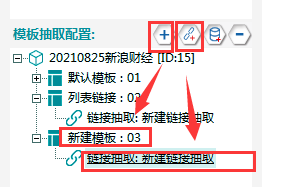
②在浏览其中打开任意一个公司的链接,并再打开企业高管页面链接。
观察发现,企业高管页面链接规律为:
http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/+公司id+.phtml
③填写脚本如下:
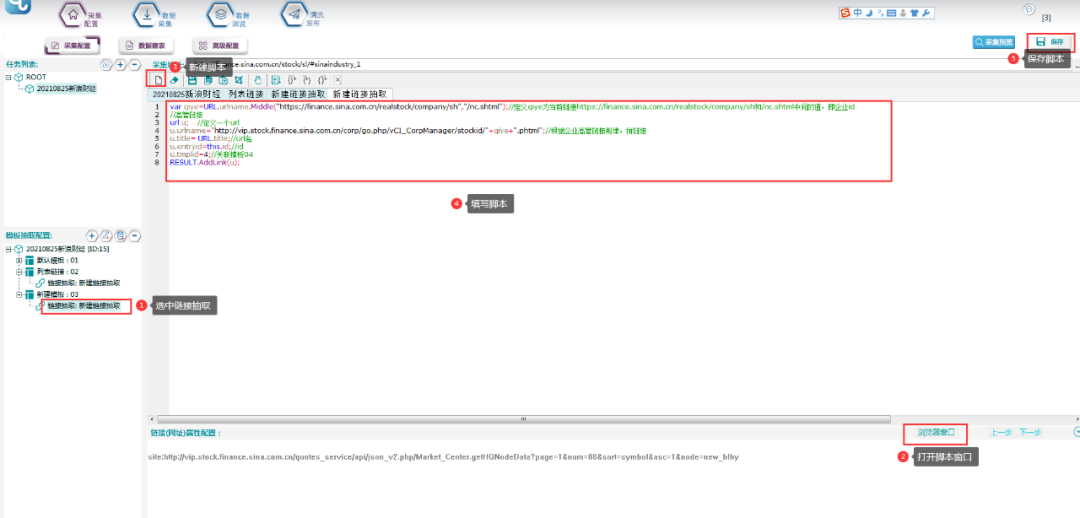
④采集预览,如下所示:
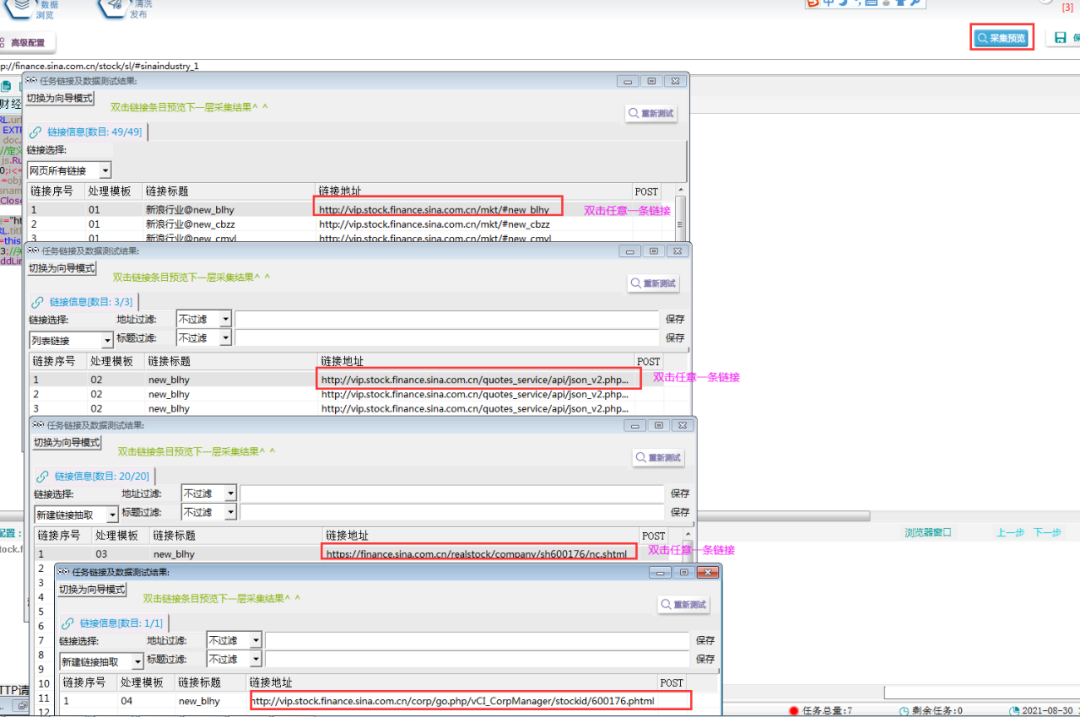
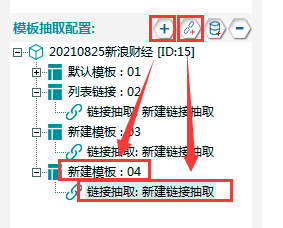
6.抽取高管链接
①新建模板04,在其下新建一个数据抽取,具体操作如下所示:
②填写示例地址,复制任意一个企业高管链接,在下图所示位置:
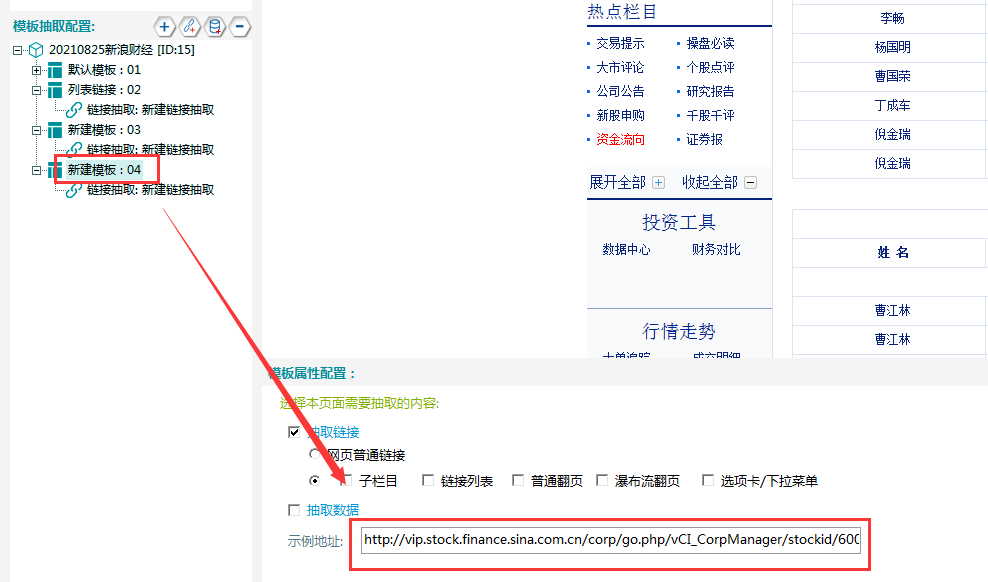
点击右上角保存后,双击模拟浏览器空白处,模拟浏览器加载出该页面。
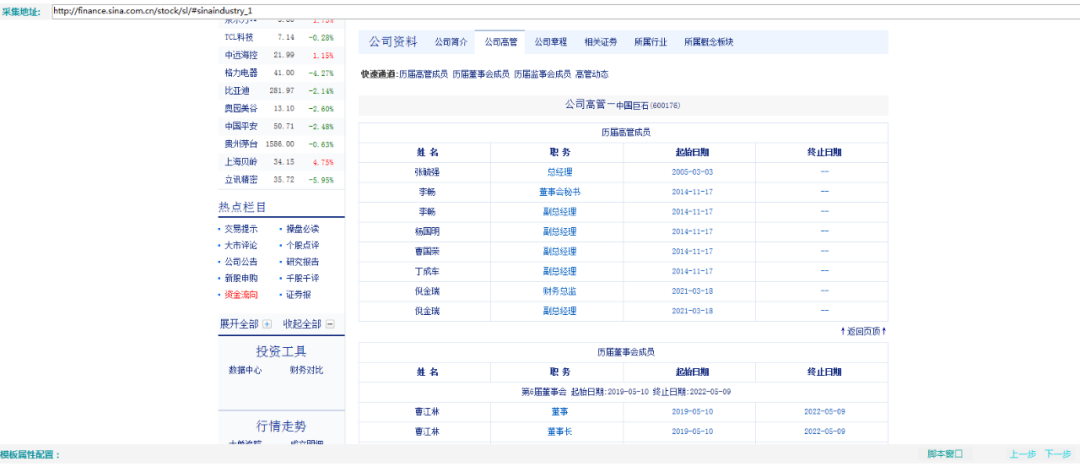
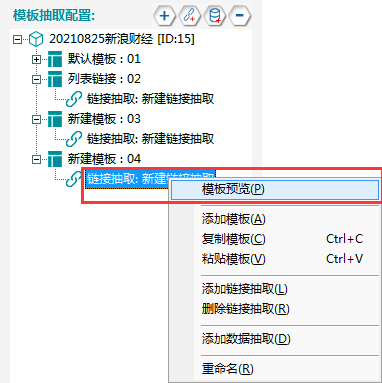
③点击模板预览
④经观察发现,高管链接规律为,都包含:http://vip.stock.finance.sina.com.cn/corp/view/vCI_CorpManagerInfo.php?stockid=
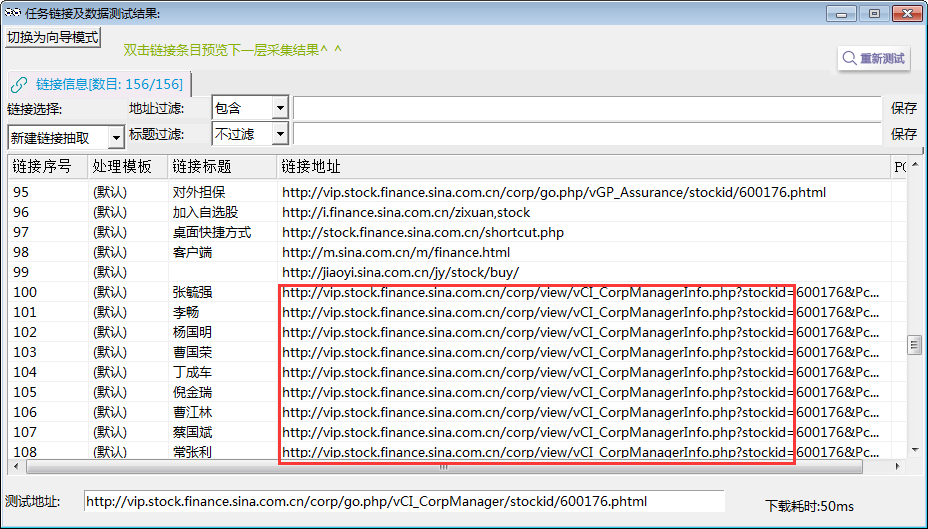
⑤地址过滤,将地址中含有http://vip.stock.finance.sina.com.cn/corp/view/vCI_CorpManagerInfo.php?stockid=的链接都过滤出来。
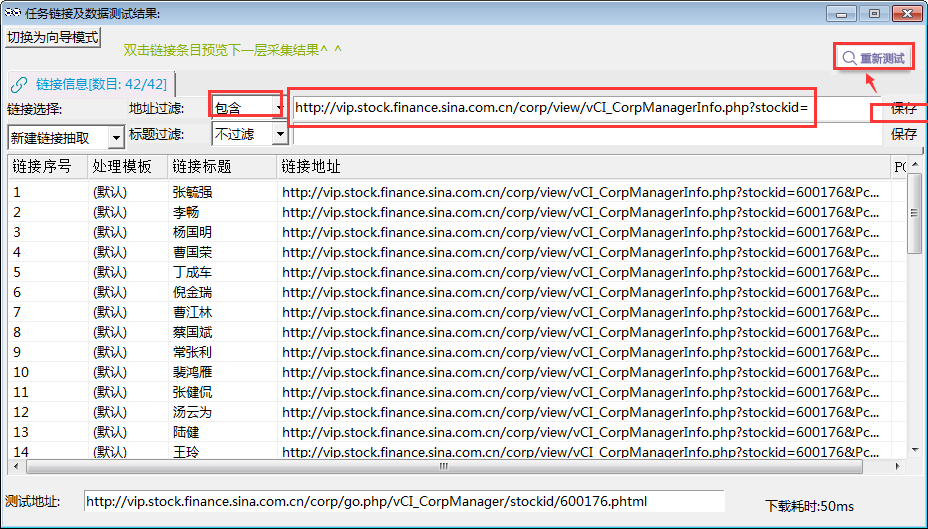
7.抽取高管数据
①新建模板05,在其下新建一个数据抽取。
②关联模板,将模板04关联至模板05。
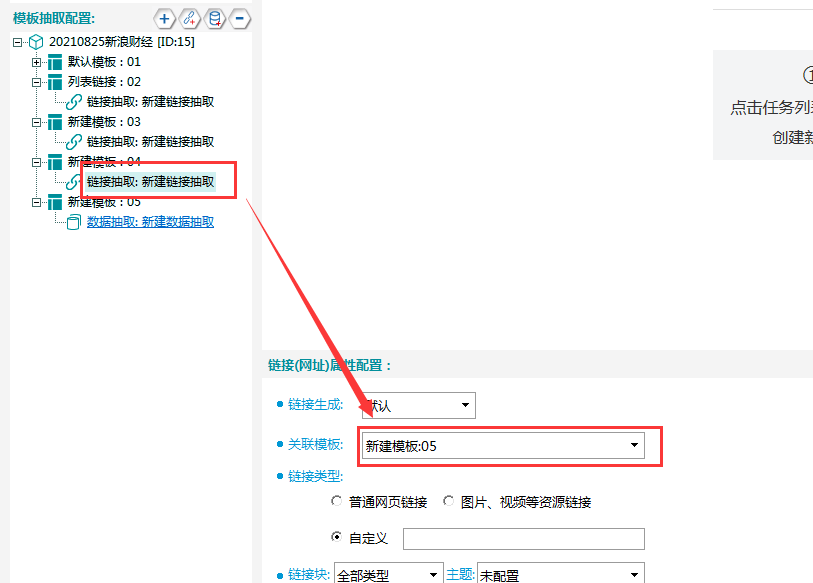
填写示例地址,将任意一个高管链接填写至如下位置:
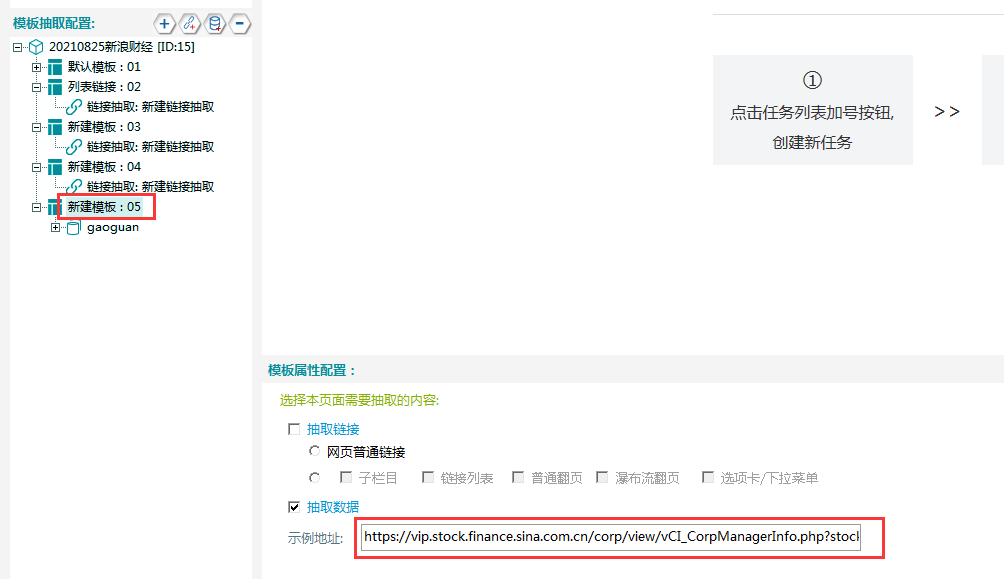
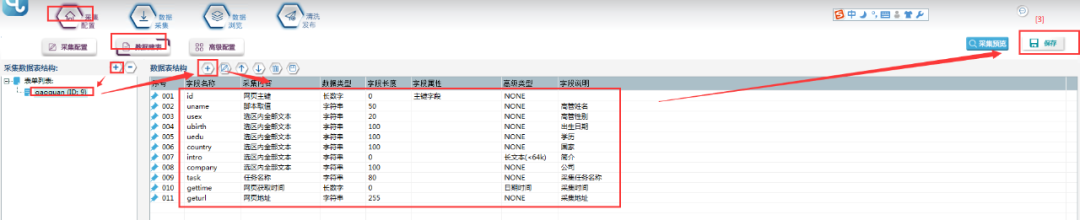
③新建一个数据表单,具体步骤和字段属性如下所示:
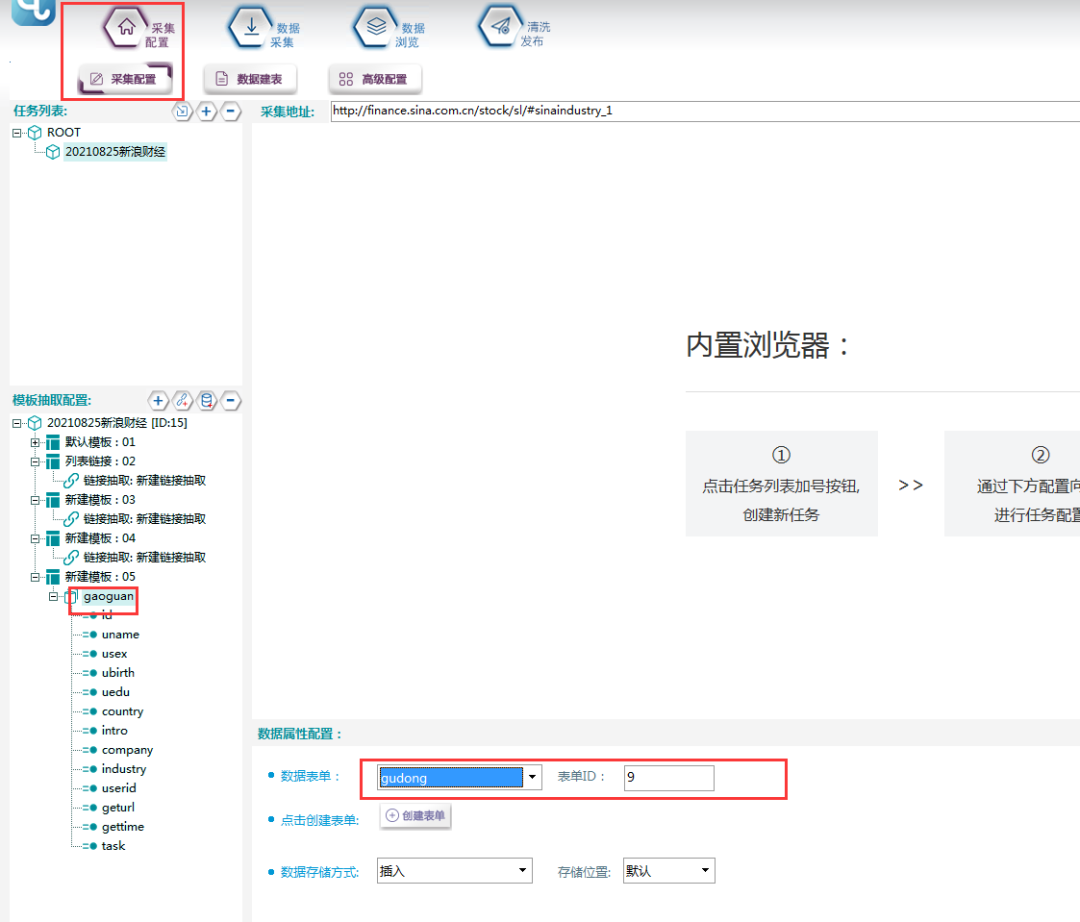
④关联数据表单,如下图所示:
⑤数据取值
A. uname:打开浏览器,F12,查看高管名称,发现其在源码中,如下图所示。
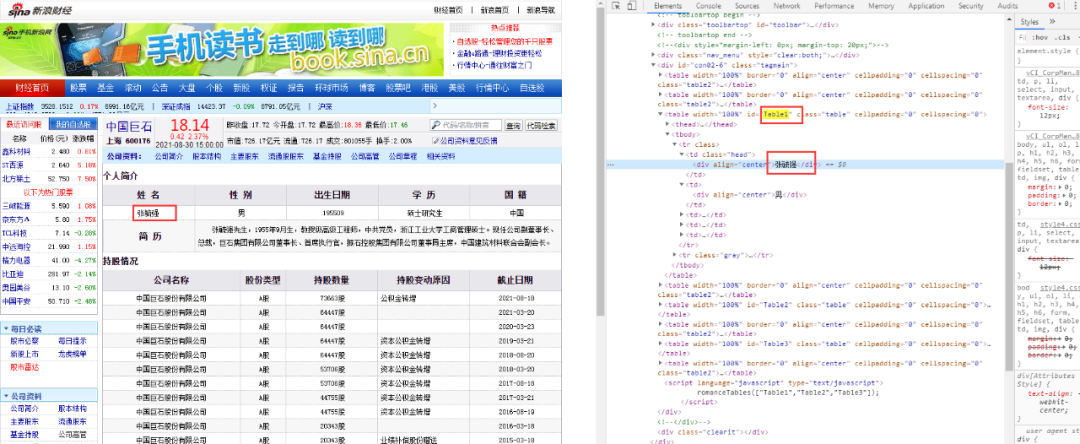
使用脚本取值,具体如下图所示:
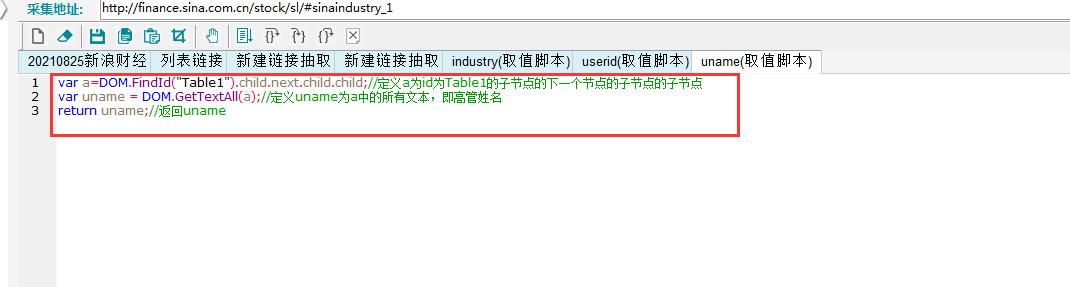
B. usex:使用定位取值的方法,进行取值。
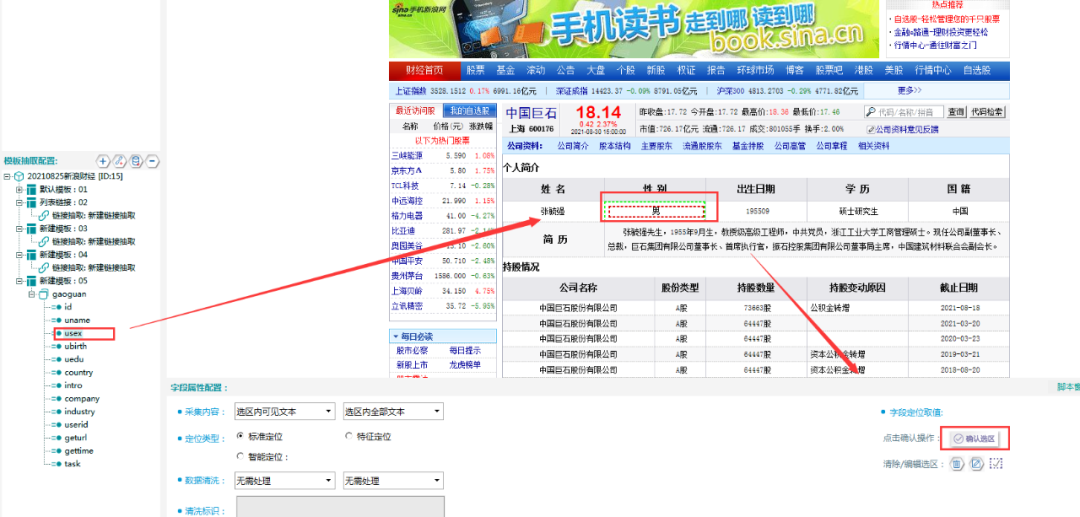
C. ubirth:定位取值(同上)
D. Uedu:定位取值(同上)
E. Country:定位取值(同上)
F. Intro:定位取值(同上)
G. Company:定位取值(同上)
⑥采集预览
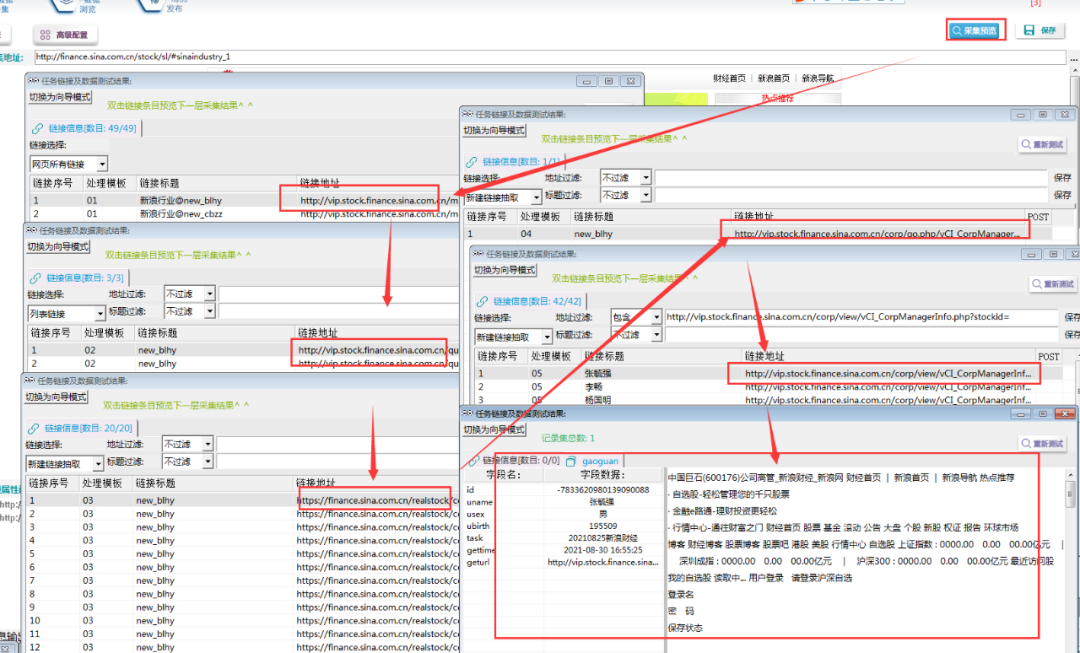
l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
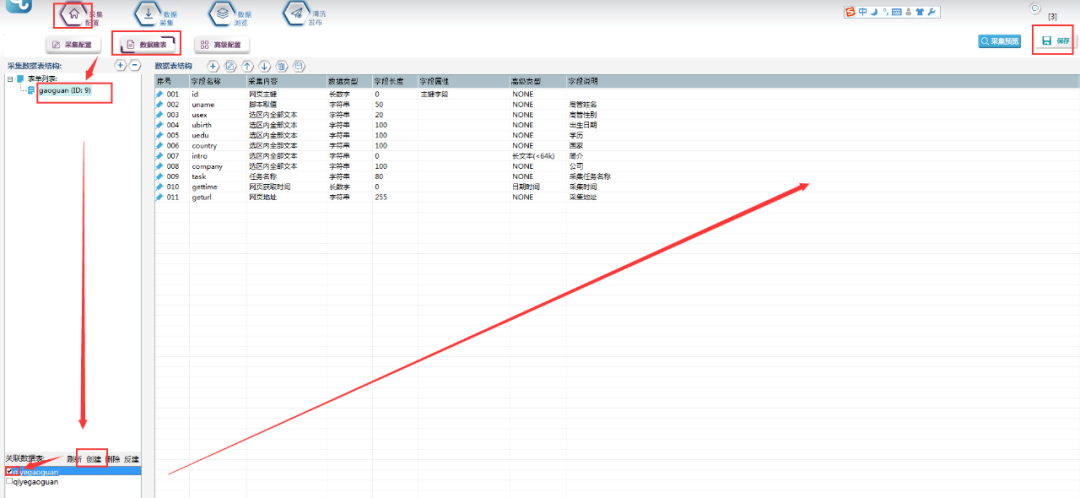
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【qiyegaoguan】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。
②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
③采集中:
④采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
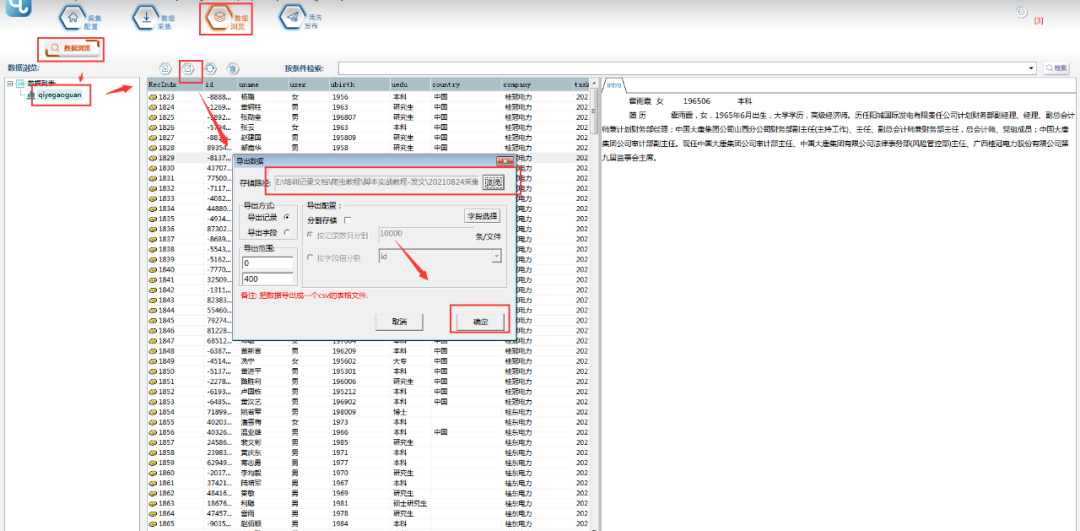
⑤导出的文件打开如下图所示:
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!
这篇关于【从零开始学爬虫】通过新浪财经采集上市公司高管信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






