本文主要是介绍BiSeNet V2网络结构详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语义分割中微观(细节)信息和宏观信息都很重要,一般浅层网络能够提取微观信息,而宏观信息提取需要很深的网络。这两个需求是相反的,如果设计成同一个网络可能会相互影响,纠缠不清,于是提出了一种双边网络,各自独立提取特征。

Detail Branch : 提取微观特征。关注图像细节。
Semantic Branch : 提取宏观特征。相当于将图像大致分块。
通常语义分割都是encode-decode结构,encode主要就是特征提取,特征融合,decode主要就是将特征重新映射回原图大小,得到语义分割后的结果图。
decode网络细节
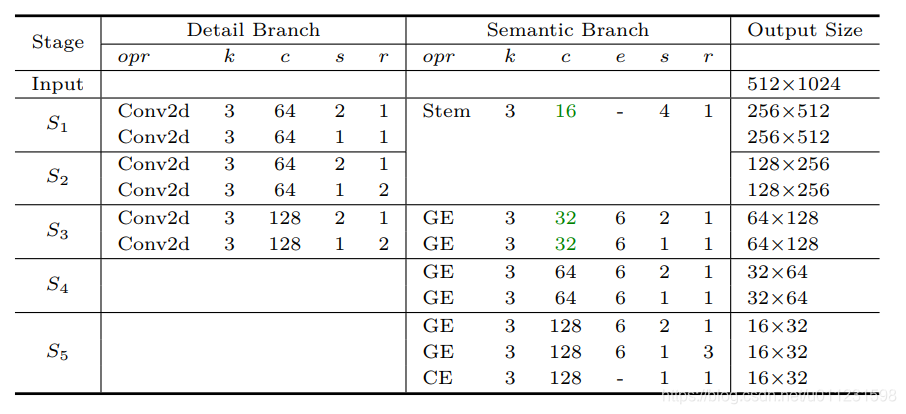
r:重复的次数
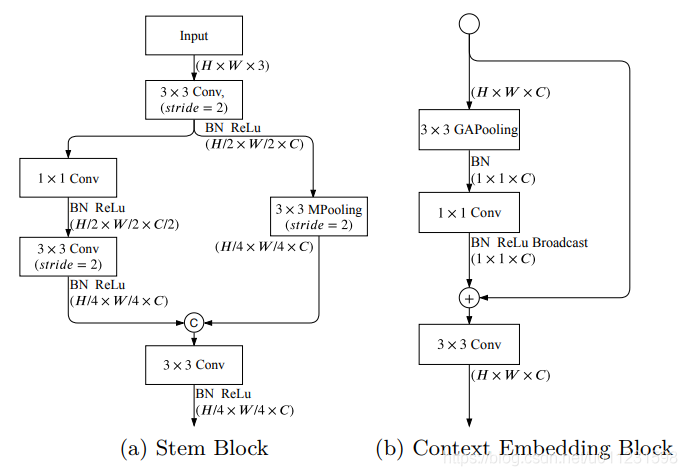
Stem Block:
卷积层设置stride=2也可以起到跟pooling类似的下采样的作用,但是卷积层下采样跟pooling下采样还是很不一样。
pooling操作可以起到平移不变性,比较粗暴,可能将有用的信息滤掉,但也可以大致保留输入feature-map的特征,比如如果是Max-pooling,它就会直接copy输入feature-map的最大像素值。pooling不占用额外参数。
卷积下采样可以降维,也可以提取一些特征,这些提取到的输出feature-map与输入feature-map像素值可能很不一样。
个人认为Stem Block合并这两种下采样的结果既可以保留部分原始图信息,又可以提取一些特征。
Context Embedding Block:
使用了全局平均池化核残差连接。GAPooling可以减少参数数量,减少计算量,减少过拟合。那里3X3 GAPooling应该是写错了,GAPooling为全局平均池化,每个feature-map只会生成一个值,GAPooling是没有核大小的。
BN ReLu Broadcast在pytorch或者python里面就是两个维度不同的数据相加就可以实现,比如上面1x1xC + HxWxC
Broadcast实现机制可以参考下图:

Gatherand-Expansion Layer:
姑且叫做聚集膨胀层吧,论文里面把下图中(b)和(c)都叫做Gather-and-Expansion Layer。
下图中(a)是MobileNet v2论文中提出的结构,即Inverted Bottleneck Conv。

这个GEBlock没有什么很复杂或者特殊的结构,主要就是卷积,深度可分离卷积以及Bottleneck结构。
这里顺便学习下Bottleneck结构,先看ResNet论文中的一张图:

上图中左边是不带Bottleneck的Block,右边就是带Bottleneck的Block。Bottleneck就是右图那里一开始接一个1x1的卷积层,把256的通道降为64的通道,然后再做卷积,再通过一个1x1的卷积层将64的通道升为256。通常1x1 filters 可以起到一个改变输出维数(channels)的作用。这里两个1x1的卷积层先降维后升维,就像两个瓶颈一样,先上宽下窄,然后再上窄下宽。这样做相对于左图那个没有Bottleneck的好处在于,第一个1x1的卷积层先对输入特征通道进行压缩,第二个1x1的卷积层对特征通道进行恢复,中间那个3x3就可以只用很少的数据量就能提取很关键的特征,bottleneck的motivation就是减小参数量和计算开支。如果上图右边不是Bottleneck,就是直接输入256通道,然后接3x3卷积,再输出256通道,如下图第一种:

上图第一种参数量为:256×3×3×256 = 589824。而第二种参数量为: 256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69632。可以明显看到采用Bottleneck参数量减少很多。
Bottleneck运算速度更快且不影响效果也可以这样理解,上图中第一种和第二种结构的对应的输入和输出信息流(可以把它想象成流过水管的水流)的量(可以想象成水流的体积)都是一样的,第二种结构相当于先缩小了信息流的长度,但是相应的横截面会增大(因为信息流的体积一直不变),这就像是同样体积的水,用粗的水管当然会传输的更快一些。
上面介绍的结构主要是特征提取模块,不含特征融合部分,下面要介绍的Aggregation Layer就包含特征融合和decode模块。
Aggregation Layer (聚合层)
Detail Branch和Semantic Branch是两个独立的网络分别提取的特征,一个是低级特征,一个是高级的特征,如果简单把Semantic Branch的特征图4 × 4 Upsample再与Detail Branch合并在一起,这样的组合就太简单了,于是论文提出了一种双边引导的聚合层(Bilateral Guided Aggregation Layer)来融合两个独立网络提取的特征。如下图所示,![]() 表示element-wise product,就是两个等大的矩阵对应元素分别相乘。
表示element-wise product,就是两个等大的矩阵对应元素分别相乘。
这个特征融合层也是本文的一个创新点,很多语义分割的特征融合只是简单的concat一下,可以以后设计新网络的时候模仿一下这种融合方式。此外,个人认为这种特征融合方式提供了丰富的特征组合方式,其中应该就包含直接concat融合。假如这个融合层里面所有的conv参数都为1的话,可能跟concat融合差不多吧。
另外下面这张图的右侧那个![]() 和Sum连接的这条路上应该还缺一个4 × 4 Upsample。不然的话经过右侧那个
和Sum连接的这条路上应该还缺一个4 × 4 Upsample。不然的话经过右侧那个![]() ,右侧特征图大小为𝐻/4 × 𝑊 /4 × C,左侧为𝐻 × 𝑊 × C,直接sum肯定会出问题,另外我在github上运行的pytorch版本的网络里面那里确实是有4 × 4 Upsample。
,右侧特征图大小为𝐻/4 × 𝑊 /4 × C,左侧为𝐻 × 𝑊 × C,直接sum肯定会出问题,另外我在github上运行的pytorch版本的网络里面那里确实是有4 × 4 Upsample。

Segmentation Head
再来看下这张彩图,里面有很多Seg Head,从不同Semantic Branch会接出Seg Head,最后的Aggregation Layer也会接出Seg Head。由Seg Head输出的图像都是跟网络输入图等大的分割图,然后它们分别去跟标label计算loss。其中Aggregation Layer后面的Seg Head输出的图像和label计算的loss为主loss,其它Seg Head输出的图像跟label计算的loss都是辅助loss。
Seg Head的结构如下:

这里主要需要注意Ct,N,S这三个参数。Ct的大小是可以设置的。Aggregation Layer后面的Seg Head会影响最后整个网络的复杂度进而影响推理的复杂度,其它Seg Head中的Ct只会影响训练时的复杂度,不会影响最终推理的复杂度。参数N就是语义分割的类别数,S就是要放大到跟原图一样大的倍数,比如上面彩图里面1/4那层Seg Head就是要放大4倍,1/8那层Seg Head就是要放大8倍,1/16那层Seg Head就是要放大16倍。
这种主loss+辅助loss的设计是一种增强训练策略。前人通过实验证实了在网络的中间部分添加损失函数进行训练对网络优化是有用的。至于为什么有用,个人认为这跟ResNet比较类似。
深度学习中特征的学习和传递可以理解成一种能量在传递,这种能量在网络输入口是一定的,也就是有限的,如果网络很深,那么通过一层一层传递和截留,就逐渐越来越少,到深层就是会出现信息能量太少,也就是对应深层网络的梯度消失无法学习到特征,ResNet就是就像是一条管道直达深层网络,把能量传递到后面,也就避免了深层网络信息量太少了。
就像是一幅画中的一条狗,一开始还可以看出是一条狗,然后抽象一次,变成一副卡通画里的狗,可以看到轮廓线条等等细节,但是毛发细节消失了,再抽象一次,就成了小孩子学画画时的简笔画,还是可以明确看出来是一条狗,再抽象一次,就成了类似于毕加索或者刚学画画的小孩子画的抽象画,已经不能一眼看出是一条狗,只能靠猜,如果再抽像一次,可能一条狗就变成了一条很粗的线条,已经完全无法认出是什么东西,深层网络到这里,肯定是无法再学到什么东西了,因为太抽象,信息太少了,这个也可以类似的理解深层网络梯度消失无法学习特征。
辅助loss就是类似于ResNet,它让浅层网络直接传递到后面去,然后参与部分loss计算。浅层一般关注细节,深层关注分块,或者说浅层关注小目标,深层关注大的目标,因为图像经过深层网络后大目标变小,而小目标可能已经缩小到更小,到了深层网络就学不到它的特征了。
这篇关于BiSeNet V2网络结构详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





