本文主要是介绍python上位机串行通信接收字节数据的校验处理-以crc16-modbus为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在串行通信中,接收到的数据是否正确,一般用CRC校码的方式来完成。上位机向下位机发送数据时,需要加上校验码,同理,下位机向上位机上报数据时,也需要加上校验码。
校验码的计算方法有很多,比较简单的是奇偶校验,相对来说容易计算,且数据传输的可靠度也还不错。比较可靠的方法用CRC校验,CRC的原理在此不详述,有需要的自行在CSDN上找答案。
这里需要说的是,接收到数据后,如何对该数据是否正确进行校验。
一、从串口接收到原始数据的不同表现形式
作为上位机,从串口收到的数据是这样的:
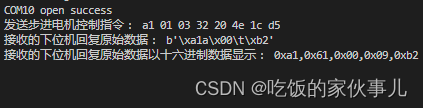
注意看图片的第3行和第4行。第3行是显示的字节码,第4行是转为16进制数显示,两者是不同的。
寻么在做校验时,是以哪个为准呢。
我们打开 字节数据校验码计算器,可以参考CRC(循环冗余校验)在线计算_ip33.com,看计算的结果
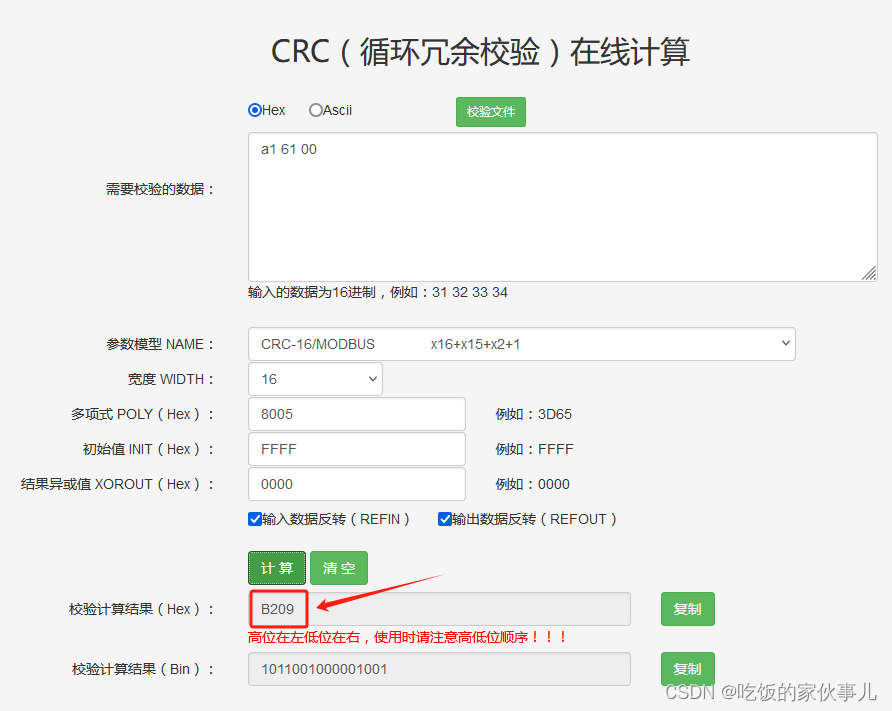
貌似是以第4行显示的结果进行的计算,我们收到的原始数据不是这个样子,似乎这种方法不可行。
其实有这个困惑的主要原因,是对字节码数据与16进制数据理解不深不透造成的。我们通过串口助手来重新看一下这个过程。首先我以十六进制的形式进行收发。
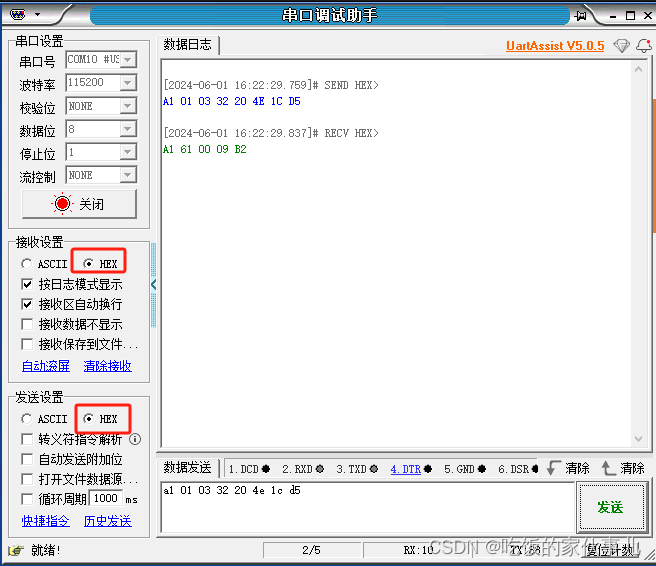
可以看到这个数据和程序收到的数据是一致的,对应的16进制数据就是A1 61 00 09 B2,转换成二进制再看一下:
data = b'\xa1a\x00\t\xb2'
binary_str1 = ' '.join(f'{byte:08b}' for byte in data)
display(binary_str1)得到的结果是:'10100001 01100001 00000000 00001001 10110010'
![]()
我们看到他和16进制数据是一一对应的。
以上说了半天,只是为了说明我们接收到的数据的表现形式,以加深我们对校验处理的理解。
二、校验
校验涉及两个问题,一是将接收到的原始数据截取成信息数据和校验码的形式;二是将信息数据用校验码生成工具重新计算生成校验码;三是对比两个校验码,看其是否一致。
def CRC16_Modbus_verification(self, rx_buf: bytes)->bool:"""使用CRC16_Modbus校验接收到的数据是否正确Args:rx_buf (bytes): 从串口接收到的数据,最后两个字节,高字节为crc_l,低字节为crc_hReturns:bool: 0,校验失败,1校验成功"""crc_h,crc_l = self.CRC16_Modbus(rx_buf[:-2]) # 校验#print('rx_buf[-2:-1]:',rx_buf[-2:-1])if crc_l == rx_buf[-2:-1] and crc_h == rx_buf[-1:]:return 1else:return 0使用上述函数,直接可以将接收到的字节码输入,自动出来计算结果,以决定数据是否采用。
以上简要描述了接收原始数据的表现形式与校验方法,当然处理这种校验的方法有很多,实际项目中,上位机开发与下位机开发要进行充分的沟通,使用相同的校验算法,这样才能通过串口进行有效通信。
这篇关于python上位机串行通信接收字节数据的校验处理-以crc16-modbus为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




