本文主要是介绍C语言数据结构排序、插入排序、希尔排序等的介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 打印数组函数
- 一、插入排序
- 二、希尔排序
- 总结
前言
C语言数据结构排序、插入排序、希尔排序等的介绍
打印数组函数
打印数组函数定义
// 打印数组
void PrintArray(int* a, int n)
{int i = 0;for (i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}
一、插入排序
插入排序定义
// 插入排序------升序
void InsertSort(int* a, int n)
{int i = 0;for (i = 1; i < n; i++){int end = i - 1;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
插入排序测试
void TestInsertSort()
{int a[] = { 9, 6, 5, 7, 3, 1, 4, 2, 8, 0 };int sz = sizeof(a) / sizeof(a[0]);PrintArray(a, sz);InsertSort(a, sz);PrintArray(a, sz);
}
效果如下:
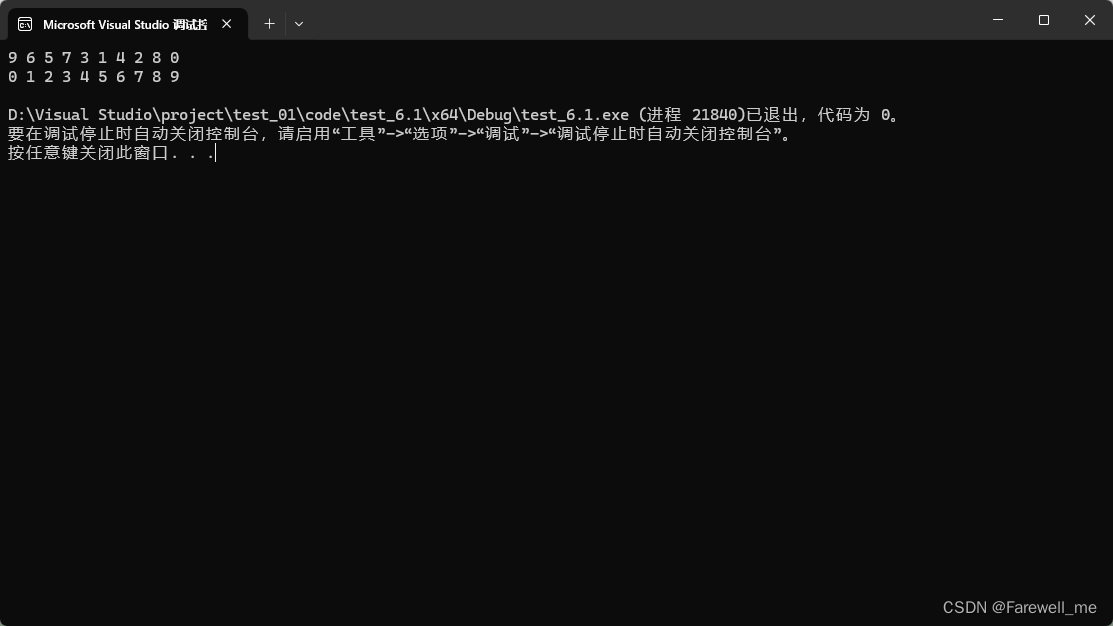
二、希尔排序
-
希尔排序的思想是先分组,进行预排序,使数组趋向于有序。
-
然后进行逐步减小分组的跨度,直至分组跨度为1,变为有序排序。
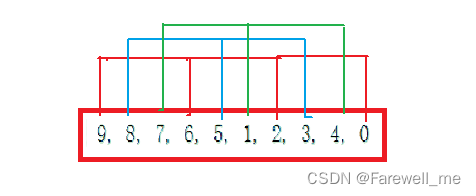
-
如上图所示,先进行分组,在组内进行排序。
希尔排序定义
// 希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap >= 1){gap /= 2;int j = 0;for (j = 0; j < gap; j++){int i = 0;for (i = gap + j; i < n; i++){int end = i - gap;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}
希尔排序测试
void TestShellSort()
{int a[] = { 9, 8, 7, 6, 5, 1, 2, 3, 4, 0, -9, -26, -65, 100, 1000, 10000 };int sz = sizeof(a) / sizeof(a[0]);PrintArray(a, sz);ShellSort(a, sz);PrintArray(a, sz);
}
效果如下:
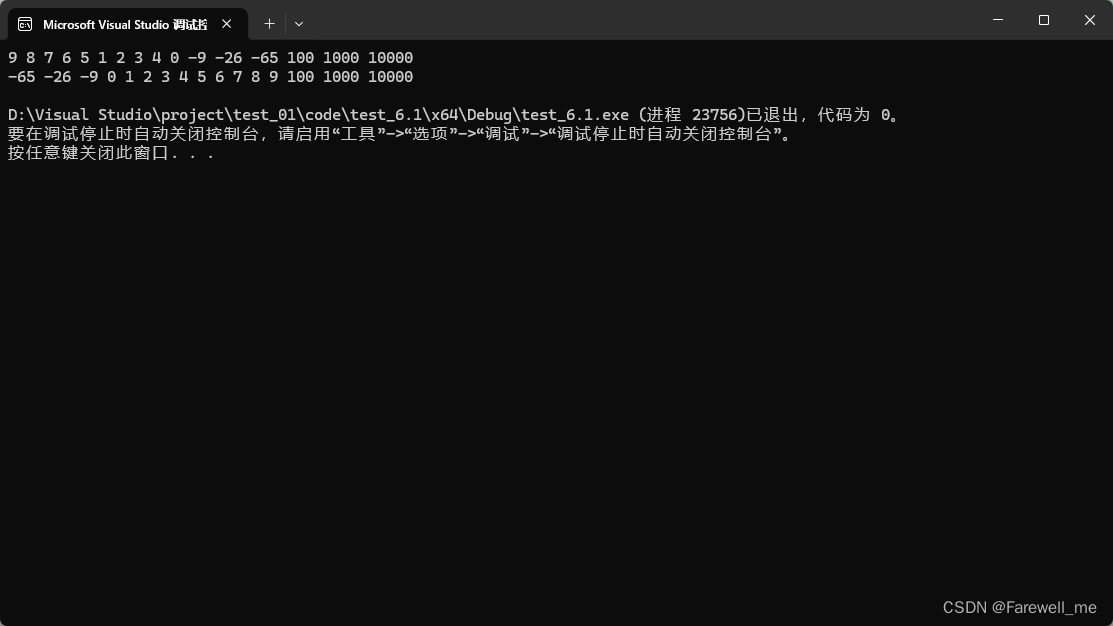
总结
C语言数据结构排序、插入排序、希尔排序等的介绍
这篇关于C语言数据结构排序、插入排序、希尔排序等的介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









