本文主要是介绍手拉手springboot整合kafka发送消息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 环境介绍 | |
| 技术栈 | springboot+mybatis-plus+mysql+rocketmq |
| 软件 | 版本 |
| mysql | 8 |
| IDEA | IntelliJ IDEA 2022.2.1 |
| JDK | 17 |
| Spring Boot | 3.1.7 |
| kafka | 2.13-3.7.0 |

创建topic时,若不指定topic的分区(Partition主题分区数)数量使,则默认为1个分区(partition)
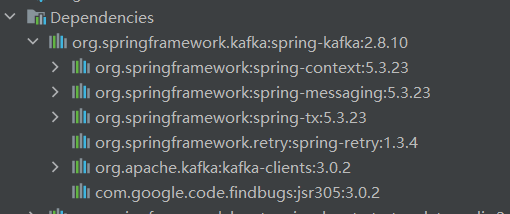
springboot加入依赖kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>加入spring-kafka依赖后,springboot自动装配好kafkaTemplate的Bean
application.yml配置连接kafka
spring:
kafka:
bootstrap-servers: 192.168.68.133:9092生产者
发送消息
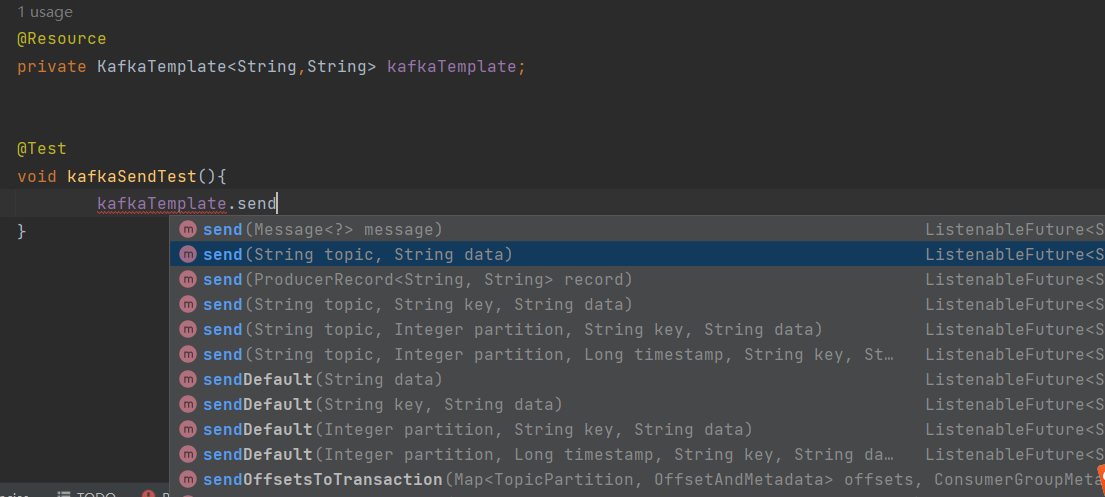
@Resource
private KafkaTemplate<String,String> kafkaTemplate;@Test
void kafkaSendTest(){
kafkaTemplate.send("kafkamsg01","hello kafka");
}
消费者
接收消息

@Component
public class KafkaConsumer {@KafkaListener(topics = {"kafkamsg01","test"},groupId = "123")
public void consume(String message){
System.out.println("接收到消息:"+message);
}}若没有配置groupid
Failed to start bean 'org.springframework.kafka.config.internalKafkaListenerEndpointRegistry'; nested exception is java.lang.IllegalStateException: No group.id found in consumer config, container properties, or @KafkaListener annotation; a group.id is required when group management is used.

@Component
public class KafkaConsumer {@KafkaListener(topics = {"kafkamsg01","test"},groupId = "123")
public void consume(String message){
System.out.println("接收到消息:"+message);
}}![]()
想从第一条消息开始读取(若同组的消费者已经消费过该主题,并且kafka已经保存了该消费者组的偏移量,则设置auto.offset.reset设置为earliest不生效,需要手动修改偏移量或使用新的消费者组)
application.yml需要将auto.offset.reset设置为earliest
spring:
kafka:
bootstrap-servers: 192.168.68.133:9092
consumer:
auto-offset-reset: earliest

Earliest:将偏移量重置为最早的偏移量
Latest: 将偏移量重置为最新的偏移量
None: 没有为消费者组找到以前的偏移量,向消费者抛出异常
Exception: 向消费者抛出异常
重置消费者组偏移量

./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group 123 --topic kafkamsg01 --reset-offsets --to-earliest –execute
重置完成

Spring-kafka生产者发送消息
.send与sendDefault()方法都返回CompletableFuture<String<k,v>>;
CompletableFuture类用于异步编程,表示异步计算结果。该特征使得调用者不必等待操作完成就可以继续执行其他任务,从而提高引用的响应速度和吞吐量
@Resource
private KafkaTemplate<String,String> kafkaTemplate;@Test
void kafkaSendTest(){
kafkaTemplate.send("kafkamsg01","hello kafka");
}发送Message
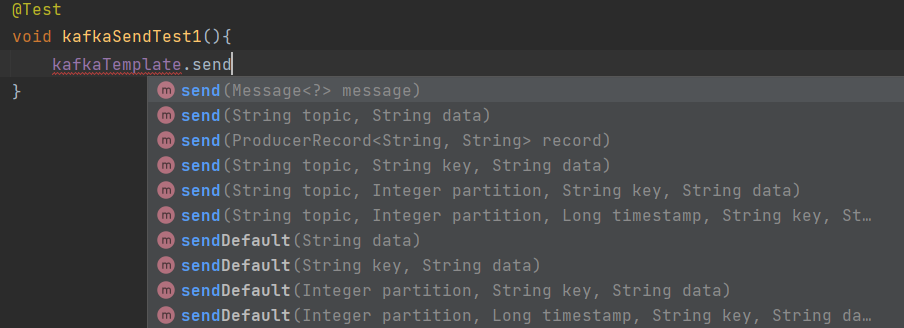
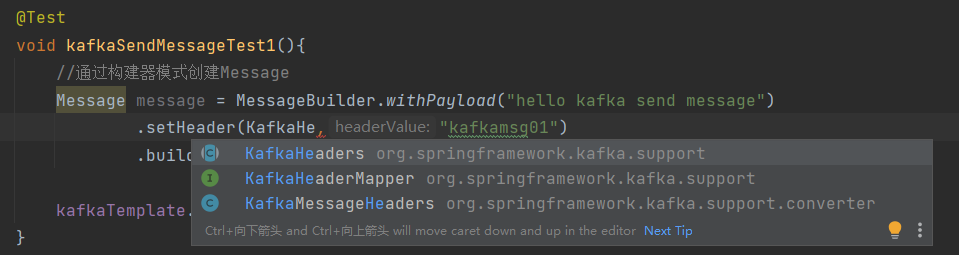
@Test
void kafkaSendMessageTest1(){
//通过构建器模式创建Message
Message<String> message = MessageBuilder.withPayload("hello kafka send message")
.setHeader(KafkaHeaders.TOPIC,"kafkamsg01")
.build();
kafkaTemplate.send(message);
}SendProducerRecord
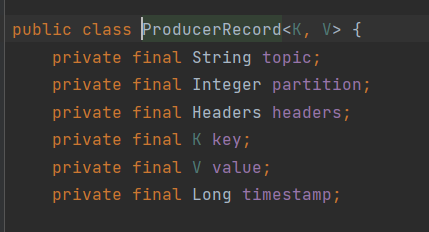

String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers
@Test
void kafkaSendProducerRecordTest1() {
//参数 String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers
Headers headers = new RecordHeaders();
headers.add("msg","123".getBytes(StandardCharsets.UTF_8));
ProducerRecord<String,String> record = new ProducerRecord(
"kafkaTopic01",
0,
System.currentTimeMillis(),
"key",
"hello kafka send message");
kafkaTemplate.send(record);
}
默认主题发送消息
yml配置默认主题
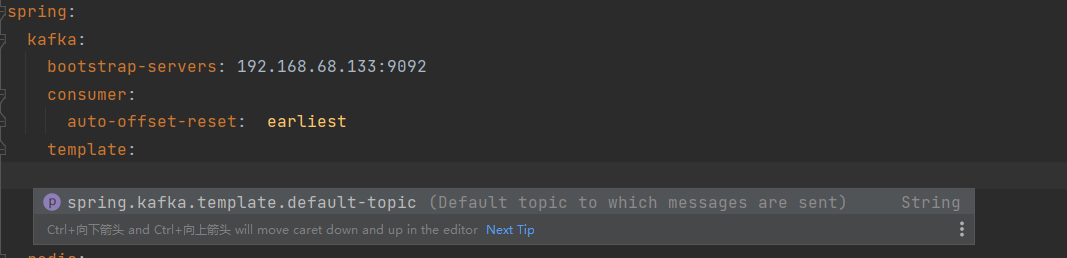
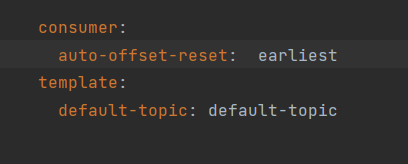
template:
default-topic: default-topic
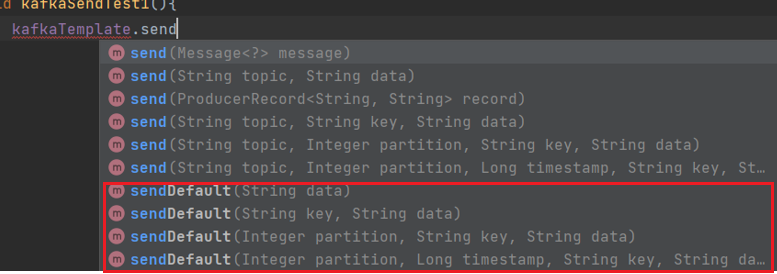
@Test
void kafkaSendDefaultTest01(){
kafkaTemplate.sendDefault(0,System.currentTimeMillis(),"key01","hello ");
}发送Object消息
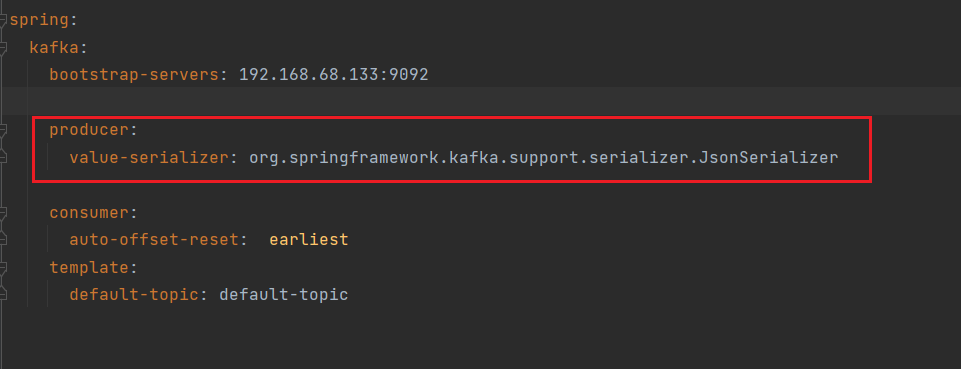
序列化默认为String
@Resource
private KafkaTemplate<String,Object> kafkaTemplate1;
@Test
void kafkaSendObject(){
MessageM messageM =MessageM.builder().userID(123).sn("xo1111").desc("测试").build();
//分区是null,kafka自行决定消息发送到哪个分区
kafkaTemplate1.sendDefault(null,System.currentTimeMillis(),"key01",messageM);
}Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
这篇关于手拉手springboot整合kafka发送消息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







