本文主要是介绍阿里云ECS服务器初始化数据盘(Linux),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:此方法适用于小于等于2 TiB的数据盘
操作步骤:
一、登录ECS实例并查看数据盘
1.远程连接ESC实例
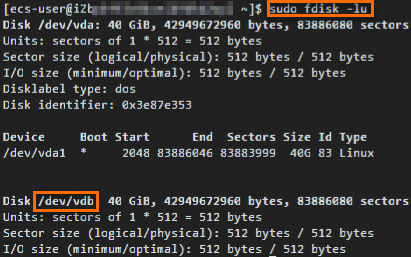
2.输入【sudo fdisk -l】获取数据盘设备名称
注:/dev/vda是系统盘,/dev/vdb是新增数据盘
二、为数据盘创建分区
1.运行【sudo yum install -y parted】安装Parted工具
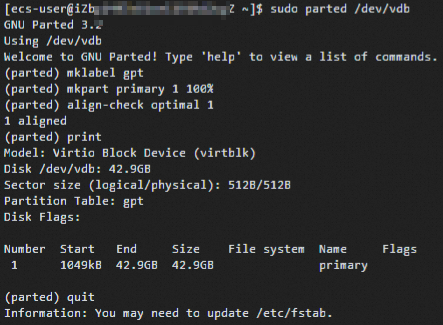
2.安装完成之后,输入【sudo parted /dev/vdb】开始分区 注:“/dev/vdb”为获取的数据盘名称
3.输入【mklabel gpt】设置GPT分区格式
4.输入【mkpart primary 1 100%】创建分区 注:"primary"是分区名,"1"是分区号,"100%"容量
如果要创建多个分区 例:【mkpart primary 1 60%】【mkpart Advanced 2 40%】
5.输入【align-check optimal 1】检查分区是否对齐
6.输入【print】查看分区表
7.输入【quit】退出Parted工具
8.输入【partprobe】让系统重读分区表
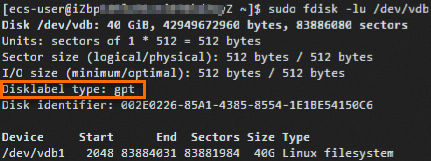
9.输入【sudo fdisk -lu /dev/vdb】查看新分区信息 注: /dev/vdb为数据盘名称
运行结果出现gpt的相关信息,表示新分区已创建完成
说明:
MBR分区不支持2 TiB以上容量。如果容量大于2 TiB或者后续扩容到2 TiB以上选择GPT分区格式,所以分区推荐选择【GPT分区格式】
Parted工具适用于MBR分区和GPT分区,fdisk分区工具只适用于MBR分区,所以工具推荐选择【Parted工具】
三、为分区创建文件系统
1.运行【sudo yum install -y e2fsprogs】安装e2fsprogs工具
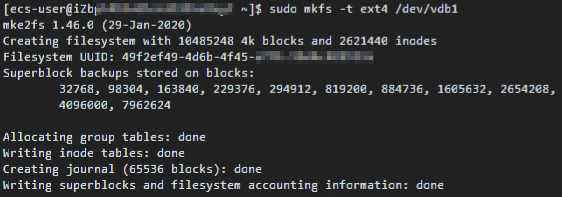
2.创建ext4文件系统,运行【sudo mkfs -t ext4 /dev/vdb1】
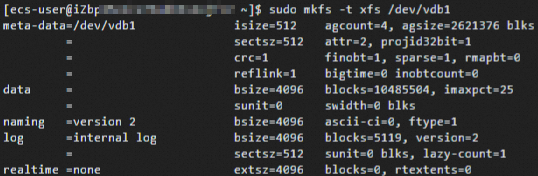
3.创建xfs文件系统,运行【sudo mkfs -t xfs /dev/vdb1】
说明:
1.当数据盘为16 TiB,创建ext4文件系统报错时,检查e2fsprogs工具包的版本是否高于1.42,并安装高版本的e2fsprogs工具包。
2.ext4文件系统的lazy init功能会影响数据盘的I/O性能,可以关闭ext4文件系统的lazy init功能
四、配置开机自动挂载分区
1.运行【sudo cp /etc/fstab /etc/fstab.bak】备份/etc/fstab文件
2.运行【echo `blkid /dev/vdb1` | awk'{print $2}' | sed 's/\"//g' /mnt exts4 defaults 0 0' >> /etc/dstab】修改/etc/fstab文件
注:
/dev/vdb1:数据盘的分区名称 /mnt:分区的挂载点
ext4:分区的文件系统类型 defaults:文件系统的挂载参数
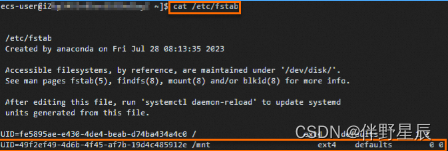
3.运行【cat /etc/fstab】,查看/etc/fstab中的新分区信息
4.运行【sudo mount -a】,挂载/etc/fstab配置的文件系统。
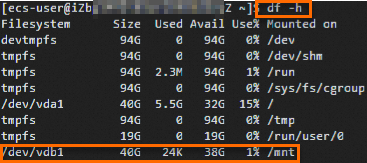
5.运行【df -h】,检查挂载结果是否成功
这篇关于阿里云ECS服务器初始化数据盘(Linux)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






