本文主要是介绍【传知代码】MonoCon解读与复现(论文复现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:在快速发展的计算机视觉领域,单目视觉(Monocular Vision)技术凭借其独特的优势和广泛的应用前景,逐渐成为了研究的热点。MonoCon作为单目视觉领域的一项重要技术,其独特的算法设计和高效的性能表现,为我们带来了许多新的启示和可能性,通过本文的解读和复现,希望能够为读者提供一个全面而深入的MonoCon技术理解,同时也希望能够激发更多人对单目视觉技术的兴趣和研究热情。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心逻辑
写在最后
概述
这篇文章描述了一种叫做MonoCon的技术,它主要用于辅助单目深度目标检测任务的学习过程。这种方法采用了训练数据中的丰富投影2D监督信号作为辅助工具,在训练过程中同时掌握了目标的3D边界框和辅助上下文信息。经过实验验证,这种方法在KITTI基准测试中展现出了卓越的性能,并且推理的速度也相当迅速。如下图所示:
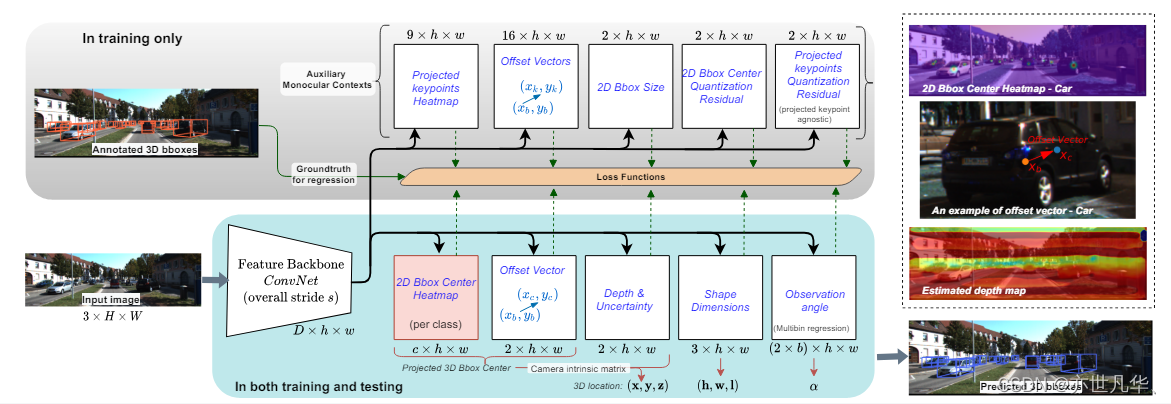
该论文提出了一种名为MonoCon的单目深度估计方法,用于预测3D物体的中心位置、形状尺寸和观察角度等参数,论文地址 在这,画面如下:
文中主要描述笔者对Kitti 3D目标检测基准所做的试验,并且和已有方法做对比。具体而言,笔者先介绍数据集及评估指标,再以MonoCon方法为对象进行训练与测试并详细分析说明。实验方面,笔者采用Kitti 3D目标检测基准下的数据集进行训练,共得到7481幅图片进行测试,7518幅图片进行对比。共对汽车,行人,自行车三大类产生兴趣。为了进行评估,作者使用了官方服务器提供的平均精度(AP)作为评价标准,这包括AP3D|R40和APBEV|R40两个评价指标。这两个指标都涉及到40个召回位置(R40),并且评估是在三个不同的难度级别下完成的。另外,笔者给出了训练验证子集划分模式。
关于实验的成果,作者首先把MonoCon与其他已有的技术手段做了对比。
在汽车分类方面,MonoCon在各种评价标准中都展现出了明显的优越性,与排名第二的GUPNet方法相比,其绝对增长率提高了1.44%。与此同时,MonoCon的运行速度要快于其他的方法。但就行人与自行车范畴而言,MonoCon并不像某些已有的方法那样具有良好性能。对于行人类,MonoCon相对于最佳模型GUPNet有1.35%的AP3D R40下降,但在所有方法中表现最好。对于自行车类别,MonoCon相对于最佳纯单目方法MonoDLE有1.29%的AP3D|R40下降,但仍然优于其他方法。笔者认为其原因可能是自行车类别3D边界框远小于汽车类别,且投影在特征图中的辅助语境通常很近,可能影响了辅助语境学习的效果。
最后笔者做了几个Ablation Study,对MonoCon结果做了更进一步的分析。在这些研究中,笔者发现学习辅助语境是改善MonoCon性能最重要的一个因素,注意力归一化效果比较差。另外,笔者对回归头进行类无关设置与训练设置效果进行了研究,并发现一定条件下能改善表现。
总体来说,本论文通过系列实验与分析来验证MonoCon完成3D目标检测任务的有效性并对其进行改进,如下图所示:

演示效果
训练模型的配置在config/monocon_configs.py:
需要修改数据集的路径。
模型训练保存的路径,比如./checkpoints_train,新建一个checkpoints_train文件夹。
如果GPU显存小于16G,要将_C.USE_BENCHMARK 设置为False;如果大约16G,设置为True。
设置BATCH_SIZE的大小,默认 _C.DATA.BATCH_SIZE = 8
设置CPU线程数,默认 _C.DATA.NUM_WORKERS = 4
设置验证模型和保存模型的间隔轮数,默认_C.PERIOD.EVAL_PERIOD = 10
from yacs.config import CfgNode as CN_C = CN()_C.VERSION = 'v1.0.3'
_C.DESCRIPTION = "MonoCon Default Configuration"_C.OUTPUT_DIR = "./checkpoints_train" # Output Directory
_C.SEED = -1 # -1: Random Seed Selection
_C.GPU_ID = 0 # Index of GPU to use_C.USE_BENCHMARK = False # Value of 'torch.backends.cudnn.benchmark' and 'torch.backends.cudnn.enabled'# Data
_C.DATA = CN()
_C.DATA.ROOT = r'./dataset' # KITTI Root
_C.DATA.BATCH_SIZE = 8
_C.DATA.NUM_WORKERS = 4
_C.DATA.TRAIN_SPLIT = 'train'
_C.DATA.TEST_SPLIT = 'val' _C.DATA.FILTER = CN()
_C.DATA.FILTER.MIN_HEIGHT = 25
_C.DATA.FILTER.MIN_DEPTH = 2
_C.DATA.FILTER.MAX_DEPTH = 65
_C.DATA.FILTER.MAX_TRUNCATION = 0.5
_C.DATA.FILTER.MAX_OCCLUSION = 2# Model
_C.MODEL = CN()_C.MODEL.BACKBONE = CN()
_C.MODEL.BACKBONE.NUM_LAYERS = 34
_C.MODEL.BACKBONE.IMAGENET_PRETRAINED = True_C.MODEL.HEAD = CN()
_C.MODEL.HEAD.NUM_CLASSES = 3
_C.MODEL.HEAD.MAX_OBJS = 30# Optimization
_C.SOLVER = CN()_C.SOLVER.OPTIM = CN()
_C.SOLVER.OPTIM.LR = 2.25E-04
_C.SOLVER.OPTIM.WEIGHT_DECAY = 1E-05
_C.SOLVER.OPTIM.NUM_EPOCHS = 20 # Max Training Epochs 200_C.SOLVER.SCHEDULER = CN()
_C.SOLVER.SCHEDULER.ENABLE = True_C.SOLVER.CLIP_GRAD = CN()
_C.SOLVER.CLIP_GRAD.ENABLE = True
_C.SOLVER.CLIP_GRAD.NORM_TYPE = 2.0
_C.SOLVER.CLIP_GRAD.MAX_NORM = 35 # Period
_C.PERIOD = CN()
_C.PERIOD.EVAL_PERIOD = 10 # In Epochs / Set -1 if you don't want validation 10
_C.PERIOD.LOG_PERIOD = 50 # In Steps 50模型推理的命令含义如下:
python test.py --config_file [FILL] # Config file (.yaml file)
–checkpoint_file [FILL] # Checkpoint file (.pth file)
–visualize # Perform visualization (Qualitative Results)
–gpu_id [Optional] # Index of GPU to use for testing (Default: 0)
–save_dir [FILL] # Path where visualization results will be saved to
使用刚才训练的权重,模型推理示例,命令如下:
python test.py --config_file checkpoints_train/config.yaml --checkpoint_file checkpoints_train/checkpoints/epoch_010.pth --visualize --save_dir save_output --gpu_id 0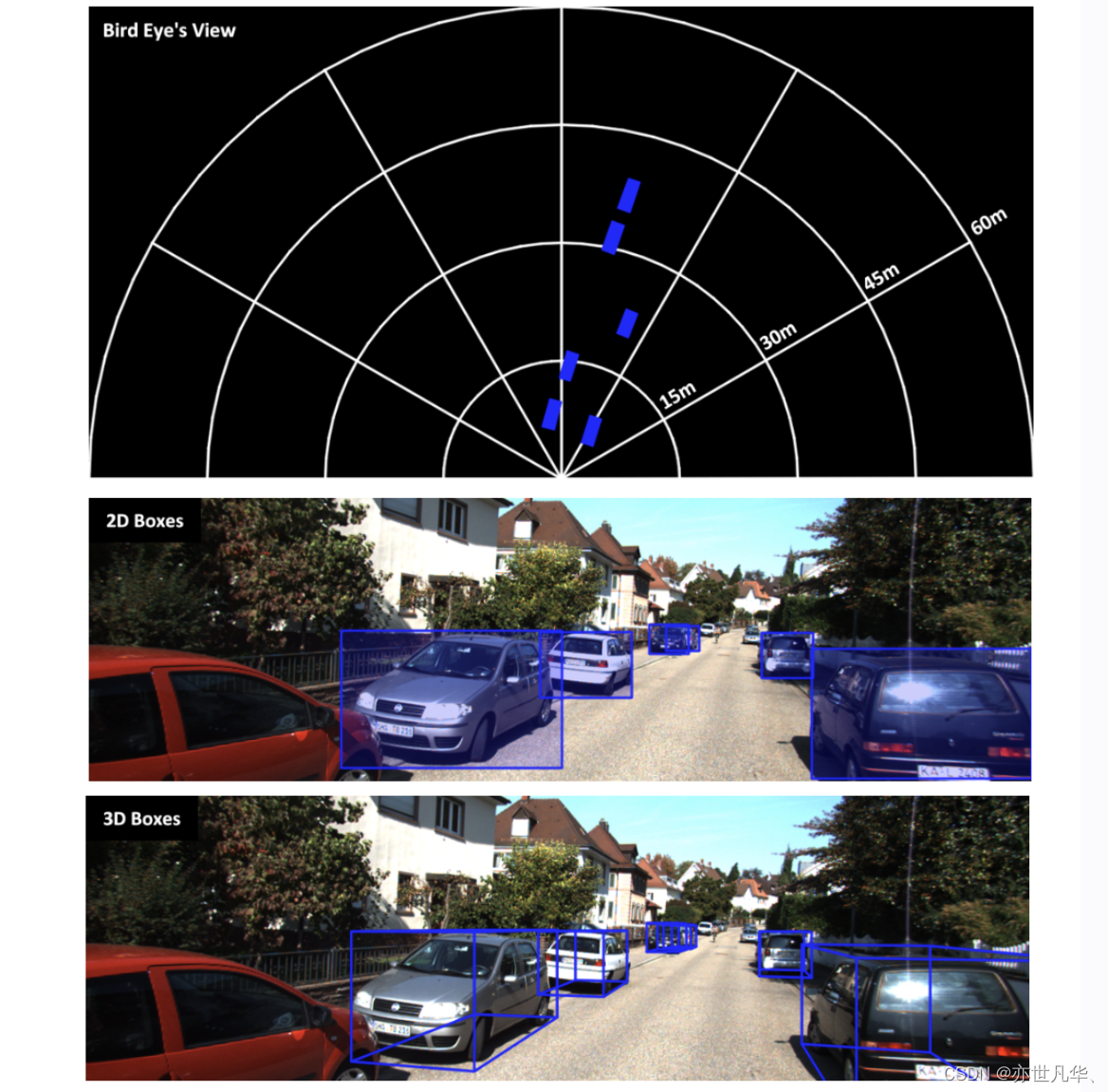
视频推理的代码如下:
python test_raw.py --data_dir [FILL] # Path where sequence images are saved--calib_file [FILL] # Calibration file ("calib_cam_to_cam.txt")--checkpoint_file [FILL] # Checkpoint file (.pth file)--gpu_id [Optional] # Index of GPU to use for testing (Default: 0)--fps [Optional] # FPS of the result video (Default: 25)--save_dir [FILL] # Path of the directory to save the result video核心逻辑
下面这段代码实现了一个名为 MonoConDetector 的单目目标检测模型,其作用主要有以下几个方面:
1)定义模型结构: 定义了一个基于 DLA 骨干网络的目标检测模型,包括了骨干网络、上采样模块以及头部模块的结构。
2)前向传播计算: 实现了模型的前向传播函数 forward,能够根据输入数据计算模型的输出结果,并在训练模式下返回损失值。
3)模型评估: 提供了批量评估函数 batch_eval,能够在推理模式下对输入数据进行评估,并生成评估格式的输出,用于模型性能评估和结果可视化。
4)模型参数加载: 提供了加载预训练模型参数的函数 load_checkpoint,能够加载预训练模型的权重参数,便于迁移学习或继续训练模型。
5)特征提取: 提供了从数据字典中提取特征的函数 _extract_feat_from_data_dict,用于将输入数据转换为模型可处理的特征表示。
总的来说,这段代码实现了一个完整的单目目标检测模型,并提供了训练、推理、评估等功能,可用于解决实际的目标检测问题。
import os
import sys
import torch
import torch.nn as nnfrom typing import Tuple, Dict, Anysys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from model import DLA, DLAUp, MonoConDenseHeadsdefault_head_config = {'num_classes': 3,'num_kpts': 9,'num_alpha_bins': 12,'max_objs': 30,
}default_test_config = {'topk': 30,'local_maximum_kernel': 3,'max_per_img': 30,'test_thres': 0.4,
}class MonoConDetector(nn.Module):def __init__(self,num_dla_layers: int = 34,pretrained_backbone: bool = True,head_config: Dict[str, Any] = None,test_config: Dict[str, Any] = None):super().__init__()self.backbone = DLA(num_dla_layers, pretrained=pretrained_backbone)self.neck = DLAUp(self.backbone.get_out_channels(start_level=2), start_level=2)if head_config is None:head_config = default_head_configif test_config is None:test_config = default_test_configif num_dla_layers in [34, 46]:head_in_ch = 64else:head_in_ch = 128self.head = MonoConDenseHeads(in_ch=head_in_ch, test_config=test_config, **head_config)def forward(self, data_dict: Dict[str, Any], return_loss: bool = True) -> Tuple[Dict[str, torch.Tensor]]:feat = self._extract_feat_from_data_dict(data_dict)if self.training:pred_dict, loss_dict = self.head.forward_train(feat, data_dict)if return_loss:return pred_dict, loss_dictreturn pred_dictelse:pred_dict = self.head.forward_test(feat)return pred_dictdef batch_eval(self, data_dict: Dict[str, Any], get_vis_format: bool = False) -> Dict[str, Any]:if self.training:raise Exception(f"Model is in training mode. Please use '.eval()' first.")pred_dict = self.forward(data_dict, return_loss=False)eval_format = self.head._get_eval_formats(data_dict, pred_dict, get_vis_format=get_vis_format)return eval_formatdef load_checkpoint(self, ckpt_file: str):model_dict = torch.load(ckpt_file)['state_dict']['model']self.load_state_dict(model_dict)def _extract_feat_from_data_dict(self, data_dict: Dict[str, Any]) -> torch.Tensor:img = data_dict['img']return self.neck(self.backbone(img))[0]当然需要对数据集划分:train训练集、val验证集,在dataset目录下新建一个文件to_train_val.py用于将training 带标签数据(7481帧),划分为train(3712帧)、val(3769帧),代码如下:
import os
import shutil# 【一】、读取train.txt文件
with open('./ImageSets/train.txt', 'r') as file:# 逐行读取train.txt文件中的文件名IDfile_ids = [line.strip() for line in file]# 【1】calib
# 指定路径A和路径B
path_A = './training/calib'
path_B = './train/calib'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.txt")destination_file = os.path.join(path_B, f"{file_id}.txt")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")# 【2】image_2
# 指定路径A和路径B
path_A = './training/image_2'
path_B = './train/image_2'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.png")destination_file = os.path.join(path_B, f"{file_id}.png")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")# 【3】label_2
# 指定路径A和路径B
path_A = './training/label_2'
path_B = './train/label_2'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.txt")destination_file = os.path.join(path_B, f"{file_id}.txt")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")# 【二】、读取valtxt文件
with open('./ImageSets/val.txt', 'r') as file:# 逐行读取val.txt文件中的文件名IDfile_ids = [line.strip() for line in file]# 【1】calib
# 指定路径A和路径B
path_A = './training/calib'
path_B = './val/calib'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.txt")destination_file = os.path.join(path_B, f"{file_id}.txt")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")# 【2】image_2
# 指定路径A和路径B
path_A = './training/image_2'
path_B = './val/image_2'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.png")destination_file = os.path.join(path_B, f"{file_id}.png")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")# 【3】label_2
# 指定路径A和路径B
path_A = './training/label_2'
path_B = './val/label_2'# 如果路径B不存在,创建它
if not os.path.exists(path_B):os.makedirs(path_B)# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:source_file = os.path.join(path_A, f"{file_id}.txt")destination_file = os.path.join(path_B, f"{file_id}.txt")if os.path.exists(source_file):shutil.copy(source_file, destination_file)else:print(f"文件未找到:{file_id}.txt")写在最后
这篇论文介绍了一种简洁且高效的单目3D目标检测技术,该技术无需依赖任何附加信息。该论文首先介绍了背景建模技术。作者所提出的MonoCon方法对辅助单目上下文进行了学习,这些上下文是基于训练过程中的3D边界框投影得出的。这种新方法能从大量数据集中自动地提取出足够数量的有用信息。这种方法使用了简洁的设计实现,它包括一个卷积神经网络特征背心和一组具有相同模块结构的回归头,用于提供必要的参数和辅助上下文。另外,为了提高网络性能,该算法将多个分类器集成到一起,以便于对不同种类物体或场景有更好地区分能力。在实验过程中,MonoCon在Kitti 3D目标检测基准测试上展现了卓越的性能,特别是在汽车类别上超越了最先进的技术,并且在行人和骑自行车的类别上也达到了相似的水平。除此之外,该技术还借助Cramer-Wold定理解来阐释其实用性,并已通过实验进行了有效的验证。
当然该论文提出的方法为单目3D目标检测提供了一个新的思路,但仍然存在一些挑战需要克服。例如,如何进一步提高模型的准确性和鲁棒性,以及如何将该方法扩展到其他应用场景中。因此,未来的研究方向可能包括改进模型的设计和优化算法,以提高模型的性能和效率。同时,还需要进一步探索单目上下文的潜力,以便更好地应用于实际场景中。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号

这篇关于【传知代码】MonoCon解读与复现(论文复现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







