本文主要是介绍python 基础知识梳理——GIL(全局解释器锁),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python 基础知识梳理——GIL(全局解释器锁)
1. 引言
之前的博文中,整理了关于Python中的多进程、多线程,还有协程的基本使用,当时我们就讨论过,Python中的多线程其实并不是"真正"的多线程,为什么呢?这就和GIL离不开关系了,下面我们通过几个列子来看一看Python中的GIL是如何影响Python中多线程的使用的。
1.1 为什么变慢了?
import time
def Countnumber(n):while n > 0:n -= 1
start = time.time()
Countnumber(100000000)
end = time.time()
print('运行时间为:{}秒'.format(end-start))
# 输出
运行时间为:6.358428239822388秒
在我这台2015 early MacBook Pro13单线程的情况下,运行时间为6.3秒,下面我们使用多线程来加速:
import time
import threading
N = 100000000
def Countnumber(n):while n > 0:n -= 1start = time.time()
t1 = threading.Thread(target=Countnumber,args=[N // 2 ])
t2 = threading.Thread(target=Countnumber,args=[N // 2 ])
t3 = threading.Thread(target=Countnumber,args=[N // 2 ])
t4 = threading.Thread(target=Countnumber,args=[N // 2 ])
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
end = time.time()
print('运行时间为:{}秒'.format(end-start))
# 输出
运行时间为:12.465165138244629秒
我们用了4个线程,没想到时间居然变成了之前的2倍,足足12秒?
2. GIL
其实,我们增加了多线程而速度却变慢的原因是由于GIL,导致Python线程的性能并不能达到我们所期待的那样。
GIL是Python自带解释器,也是最流行的Python解释器CPython中的一个技术,它的中文名为:全局解释器锁,每个Python线程,在CPython解释器中执行的时候,都会先锁住自己的线程,阻止别的线程执行。
而且,CPython会假装轮流执行Python线程,让我们看起来以为Python中的线程是在交错执行。
那为什么CPython为什么要使用GIL呢?其实这涉及到Python中的垃圾回收机制的引用计数。
Python的垃圾回收机制是以引用计数为主,标记-清除和分代回收为辅的策略。
import sys
a = []
b = a
print(sys.getrefcount(a))
# 输出
3
输出为a的引用计数 3 ,因为a、b和作为参数传递的getrefcount这三个地方都引用了一个空列表。回到刚刚我们使用的多线程,如果两个Python线程同时引用了a,那么就会造成引用计数的race condition(竞争),引用计数可能只会增加1,当第一个线程访问结束后,会把引用计数减少1,这时可能会达到条件释放内存,当第二个线程再想访问a时,就找不到有效的内存了(引用计数为0会被回收)。
所以说,CPython引用GIl其实主要是两个原因:
- 为了规避内存管理的
race condition(竞争)问题 - 顾名思义,CPython就是使用C解释Python语言,而大部分C语言库都不是原生线程安全的
3. GIl是如何工作的?

如图,当Thread1、2、3轮流执行的时候,每一个线程会在开始执行时,锁住GIL,以阻止别的线程执行;当该线程执行完成后会释放GIL,以便其他线程可以开始执行。
CPython中的check_interval机制会轮训检查线程GIL的锁情况,每隔一段时间,Python解释器就会强制当前的线程去释放GIL,这样别的线程才能有机会去执行。
Python3中,CPython会在一个“合理”的范围内释放GIL(以Python3为例,
interval的时间大概是15毫秒)
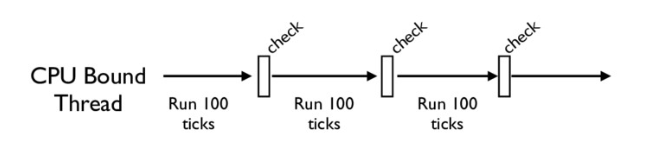
从底层代码中,我们可以一探究竟,基本上每一个Python都是类似于这样的循环封装:
for (;;) {if (--ticker < 0) {ticker = check_interval;/* Give another thread a chance */PyThread_release_lock(interpreter_lock);/* Other threads may run now */PyThread_acquire_lock(interpreter_lock, 1);}bytecode = *next_instr++;switch (bytecode) {/* execute the next instruction ... */ }
}
很显然,Python的每个线程都会检查ticker计数,只有ticker计数大于0的情况下,线程才会去执行自己的byetecode。
4. Python的线程安全
之前我们谈论到多线程的时候,经常会说,要使用threading.lock()先锁住一个共享变量,当修改完成后再给其他线程使用?
这是因为,GIL仅允许一个Python线程执行,不意味着Python的线程就是完全安全的。
下面我们参考一段代码:
import threadingn = 0
def foo():global nn += 1threads = []
for i in range(1000):t = threading.Thread(target=foo)threads.append(t)
for t in threads:t.start()
for t in threads:t.join()
print(n)
import dis
print(dis.dis(foo))
# 输出6 0 LOAD_GLOBAL 0 (n)2 LOAD_CONST 1 (1)4 INPLACE_ADD6 STORE_GLOBAL 0 (n)8 LOAD_CONST 0 (None)10 RETURN_VALUE
None
大部分情况下,输出结果都是1000,但是也有可能是999、998,这是因为n += 1这一行代码让线程并不安全。
当我们通过dis.dis()打印foo()这个函数的bytecode的时候,就会发现这6行的bytecode中间都是可能被打断的。
所以,我们可以使用
threading.Lock()来确保线程安全
n = 0
lock = threading.Lock()
def foo():global nwith lock:n += 1
5. 如何绕过GIL?
加入你曾经看过我之前的博文,一定会对%time魔术方法印象深刻,这是我常用的一款基于iPython解释器的jupyter notebook上的一种输出函数运行时间的方法,它的解释器就并不是CPython,那么就不受GIL的影响了。
事实上,如果你是深度学习或者机器学习乃至数据分析,人工智能相关专业的同学,那么你一定不会对NumPy陌生,这样的矩阵运算库底层也是用C实现的,且不受GIL的影响。
说了那么多,你会不会感觉我在说废话?其实,绕过GIL的大致思路就是两种:
- 绕过CPython,使用IPython或者JPython(Java实现的Python解释器)等解释器实现;
- 把对于性能要求高的代码,放到别的语言中实现;
6.奇怪的想法
import time
import multiprocessing
N = 100000000
def Countnumber(n):while n > 0:n -= 1start = time.time()
t1 = multiprocessing.Process(target=Countnumber,args=[N // 2])
t2 = multiprocessing.Process(target=Countnumber,args=[N // 2])t1.start()
t2.start()t1.join()
t2.join()end = time.time()
print('运行时间为:{}秒'.format(end-start))
# 输出
运行时间为:3.4095828533172607秒
居然使用多进程,速度就快了一倍?
博文的后续更新,请关注我的个人博客:星尘博客
这篇关于python 基础知识梳理——GIL(全局解释器锁)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




