本文主要是介绍Rust爬虫练手:获取B站“庆余年2“短视频地址,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 基本模板
这里的外链接指的所有是
<href>标签的值;
// 导入 error_chain 宏,用于定义错误处理宏
use error_chain::error_chain;
// 导入 select 库中的 Document 结构体,用于解析 HTML 文档
use select::document::Document;
// 导入 select 库中的 Name 谓词,用于选择指定标签
use select::predicate::Name;// 使用 error_chain 宏定义错误处理宏
error_chain! {// 定义外部错误链接foreign_links {// 将 reqwest 库中的 Error 错误类型映射为 ReqErrorReqError(reqwest::Error);// 将 std::io 库中的 Error 错误类型映射为 IoErrorIoError(std::io::Error);}
}// 异步 main 函数,使用 tokio::main 宏标记为异步函数
#[tokio::main]
async fn main() -> Result<()> {// 发起 GET 请求获取指定网址的响应let res = reqwest::get("https://www.qianlans.top").await? // 等待请求完成,处理可能出现的请求错误.text() // 将响应转换为文本.await?; // 等待文本转换完成,处理可能出现的 IO 错误// 从响应文本创建一个 Document 对象Document::from(res.as_str())// 查找所有符合条件的 <a> 标签.find(Name("a"))// 获取每个 <a> 标签的 href 属性值,过滤掉空值.filter_map(|n| n.attr("href"))// 遍历每个 href 属性值并打印.for_each(|x| println!("{}", x));// 返回 Ok 表示程序执行成功Ok(())
}
2. 案例实操:爬取B站搜索”庆余年2“的视频数据
2.1 第一爬:爬取当页所有链接
最近庆余年相关的内容都比较受欢迎,这里就以爬取B站以庆余年为关键词搜索出来的视频链接作为示例演示这段代码的功能:
爬取的目标地址:
https://search.bilibili.com/all?vt=27468598&keyword=%E5%BA%86%E4%BD%99%E5%B9%B42&from_source=webtop_search&spm_id_from=333.934&search_source=2
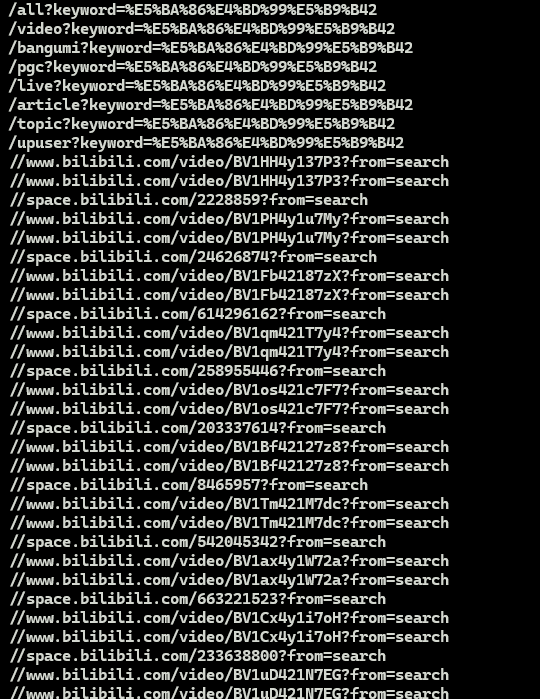
2.2 第二爬:过滤非法链接
从上面爬取得数据来看,爬取得链接地址并不全部符合我们得要求,我们需要是包含了
https开头得完可访问的视频url,但是这里却包含了一些奇奇怪怪的地址,比如开头那几行就没意义,后面这些地址也不是完整的URL,因此还需要进一步改进我们的代码;
use error_chain::error_chain;
use regex::Regex;
use select::document::Document;
use select::predicate::Name;
error_chain! {foreign_links {ReqError(reqwest::Error);IoError(std::io::Error);}
}#[tokio::main]
async fn main() -> Result<()> {let res = reqwest::get("https://search.bilibili.com/all?keyword=%E5%BA%86%E4%BD%99%E5%B9%B42&from_source=webtop_search&spm_id_from=333.934&search_source=2").await?.text().await?;let base_url = "https:";let re = Regex::new(r"//www\.bilibili\.com/video/[^?]*\?from=search").unwrap();let mut count = 0;Document::from(res.as_str()).find(Name("a")).filter_map(|n| n.attr("href")).filter(|href| re.is_match(href)).for_each(|href| {let full_url = if href.starts_with("//") {format!("{}{}", base_url, href)} else {href.to_string()};count += 1;println!("{}", full_url);});println!("==============================爬完了================================");println!("当页爬取视频条数:{}", count);Ok(())
}
这段代码在原基础上做了一下几点调整:
- 新增了一个
base_url,用来对获取到的相对地址进行追加https头,完善链接;- 新增了一个匹配规则,使用正则表达式过滤不满足条件的地址,我们需要的只是当页的可访问视频
URL。
2.3 第三爬:自动翻页,爬取所有数据
- 通过上面两次爬取,我们的程序已经可以正常爬取并过滤当前页的视频数据了,那么接下来如何实现自动爬取第二页、第三页到全部页码的总数据呢?
- 观察页面,总结规律
打开B站搜索结果地址,默认就是第一页的,我们看看这页的地址栏信息如下:
- 第一页:

- 第二页:

- 第三页

- 第四页

嗯~ o( ̄▽ ̄)o,差不多了,通过观察这几页的地址可以提取出来他们的公共部分:
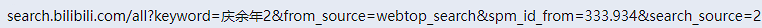
也就是说,这部分是固定不变的,不管你当前页码是多少页也不影响。真正动态变化的是后面这部分:
&page=n&o=108
一眼就看出来:
- page代表当前页的页码,比如
2,3,4,4,5...n; - o代表截至当前页的数据总条数,注意这是从第二页开始计算的
B站目前视频搜索结果的分页策略是每页36条数据,假设我们以第4页为例,那么截至第4页,当前的视频总数就是 ( 4 − 1 ) ∗ 36 = 108 (4-1)*36=108 (4−1)∗36=108;也就是 o = ( p a g e − 1 ) ∗ 36 o = (page-1) * 36 o=(page−1)∗36;
额,有点跑题了,其实不需要知道的如此准确。我们需要的就是每页的地址栏变化规律
use error_chain::error_chain;
use regex::Regex;
use select::document::Document;
use select::predicate::Name;error_chain! {foreign_links {ReqError(reqwest::Error);IoError(std::io::Error);}
}#[tokio::main]
async fn main() -> Result<()> {let base_url = "https://search.bilibili.com/all?keyword=%E5%BA%86%E4%BD%99%E5%B9%B42&from_source=webtop_search&spm_id_from=333.934&search_source=2&page=";let base_offset = "&o=";let re = Regex::new(r"//www\.bilibili\.com/video/[^?]*\?from=search").unwrap();let mut count = 0;let mut page = 1;loop {let url = format!("{}{}{}{}", base_url, page, base_offset, (page - 1) * 36);let res = reqwest::get(&url).await?.text().await?;let links_count = Document::from(res.as_str()).find(Name("a")).filter_map(|n| n.attr("href")).filter(|href| re.is_match(href)).map(|href| {let full_url = if href.starts_with("//") {format!("https:{}", href)} else {href.to_string()};count += 1;println!("Link {}: {}", count, full_url);}).count();if links_count == 0 {break; // No more links found on this page, exit the loop}page += 1;}println!("==============================爬完了================================");println!("总共爬取视频条数: {}", count);Ok(())
}下面是爬取页码数据之后的结果,符合条件的URL,随便点一条都是可以正常访问的。
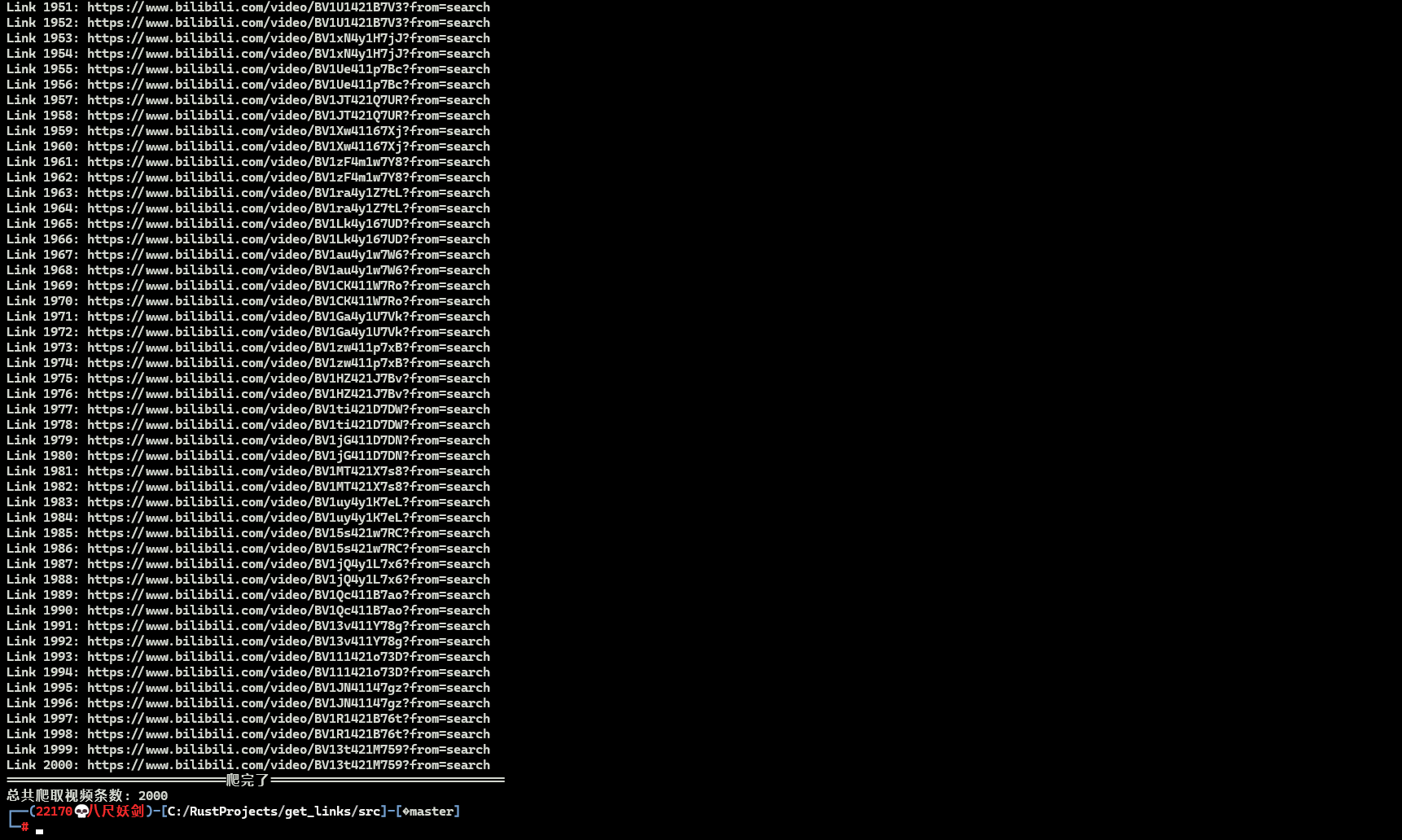
不过从数据来看,爬取的数据存在重复的情况,但是此时由于请求次数过多,已经触发了B站的风控策略,暂时没法继续调试了,剩下的去重工作就交给你了,年轻人!

B站风控结束,今天继续将后面部分补上吧!
2.4 第四爬:对数据进行去重
今天又可以继续请求数据了,所以就花几分钟时间把这部分补上。之前的数据是存在重复的,这就导致了爬取到的数据是原数据条数的两倍,这里简单做了个去重,原理比较简单,用
HashSet这个数据结构。
use std::collections::HashSet;use error_chain::error_chain;
use regex::Regex;
use select::document::Document;
use select::predicate::Name;error_chain! {foreign_links {ReqError(reqwest::Error);IoError(std::io::Error);}
}#[tokio::main]
async fn main() -> Result<()> {let base_url = "https://search.bilibili.com/all?keyword=%E5%BA%86%E4%BD%99%E5%B9%B42&from_source=webtop_search&spm_id_from=333.934&search_source=2&page=";let base_offset = "&o=";let re = Regex::new(r"//www\.bilibili\.com/video/[^?]*\?from=search").unwrap();let mut count = 0;let mut page = 1;let mut visited_links = HashSet::new();loop {let url = format!("{}{}{}{}", base_url, page, base_offset, (page - 1) * 36);let res = reqwest::get(&url).await?.text().await?;let links_count = Document::from(res.as_str()).find(Name("a")).filter_map(|n| n.attr("href")).filter(|href| re.is_match(href)).map(|href| {let full_url = if href.starts_with("//") {format!("https:{}", href)} else {href.to_string()};// count += 1;if !visited_links.contains(&full_url) {visited_links.insert(full_url.clone());count+=1;println!("Link {}: {}", count, full_url);}}).count();if links_count == 0 {break; // No more links found on this page, exit the loop}page += 1;}println!("==============================爬完了================================");println!("总共爬取视频条数: {}", count);Ok(())
}

在上面的代码示例中,使用了
visited_links.insert(full_url.clone())来将链接添加到HashSet中。这里的clone()操作会复制full_url的所有内容,可能会对性能产生一定影响,特别是在处理大量数据时。
2.5 第五爬:将数据写入文件
在终端打印爬取得数据显然不是一种很可取得方法,现在我们通过修改代码,将爬取得数据写入到指定得文件中进行持久化。
use error_chain::error_chain;
use regex::Regex;
use select::document::Document;
use select::predicate::Name;
use std::collections::HashSet;
use std::fs::File;
use std::io::prelude::*;error_chain! {foreign_links {ReqError(reqwest::Error);IoError(std::io::Error);}
}#[tokio::main]
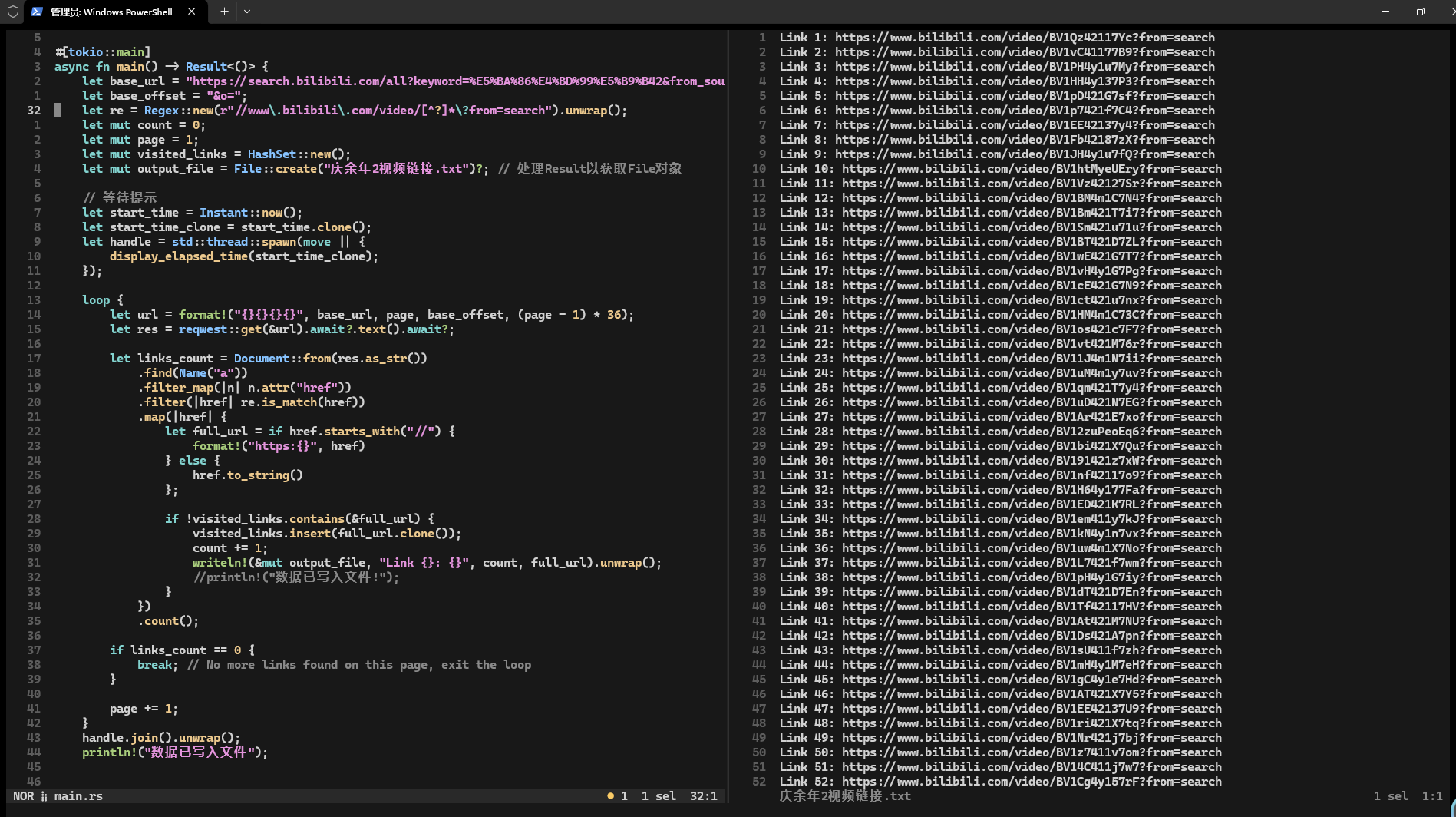
async fn main() -> Result<()> {let base_url = "https://search.bilibili.com/all?keyword=%E5%BA%86%E4%BD%99%E5%B9%B42&from_source=webtop_search&spm_id_from=333.934&search_source=2&page=";let base_offset = "&o=";let re = Regex::new(r"//www\.bilibili\.com/video/[^?]*\?from=search").unwrap();let mut count = 0;let mut page = 1;let mut visited_links = HashSet::new();let mut output_file = File::create("庆余年2视频链接.txt")?; // 处理Result以获取File对象loop {let url = format!("{}{}{}{}", base_url, page, base_offset, (page - 1) * 36);let res = reqwest::get(&url).await?.text().await?;let links_count = Document::from(res.as_str()).find(Name("a")).filter_map(|n| n.attr("href")).filter(|href| re.is_match(href)).map(|href| {let full_url = if href.starts_with("//") {format!("https:{}", href)} else {href.to_string()};if !visited_links.contains(&full_url) {visited_links.insert(full_url.clone());count += 1;writeln!(&mut output_file, "Link {}: {}", count, full_url).unwrap();//println!("数据已写入文件!");}}).count();if links_count == 0 {break; // No more links found on this page, exit the loop}page += 1;}println!("数据已写入文件");Ok(())
}
项目地址:GiHub
这篇关于Rust爬虫练手:获取B站“庆余年2“短视频地址的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





