本文主要是介绍【新技术_01】Eclipes使用,可变参数,高级For循环,基本数据自动装箱拆箱,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 选择Eclipes的版本
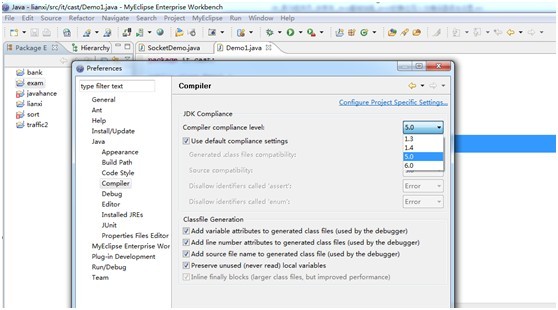
工具栏-Window-Perferences-Java-Complier下 如图选择版本
1.1 Eclipes快捷键配置方法
举例:(补充语句快捷键 Alt+\)
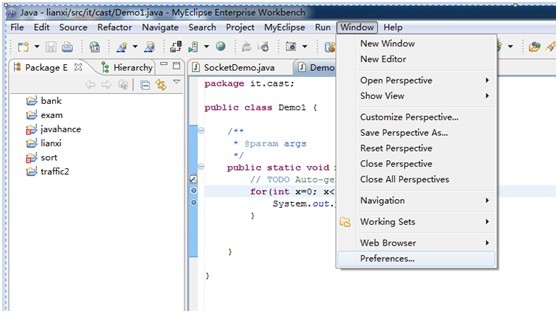
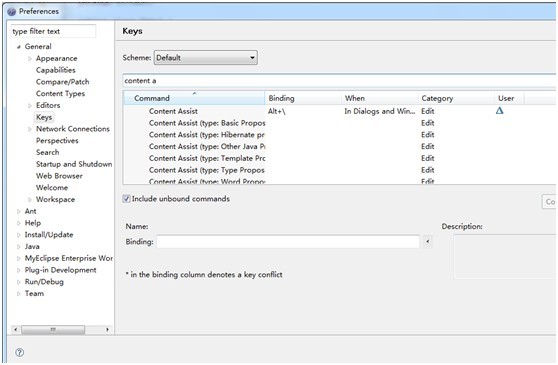
工具栏-Window-Perferences-General-Keys-输入 content assist
1.2 配置模板
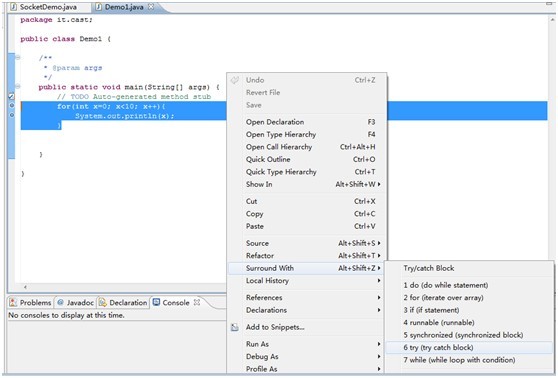
1.在Eclipes选中要创建模板的命令行,右键--Surround With—try这样就会自动的把选中命令加入到try{ } catch( ){ }模板中
2.如果右键--Surround With中没有需要的模板可以在
工具栏 Window—Perferences-Java-Editor-Templates-点击New-创建自己的模板命令
1.2.1
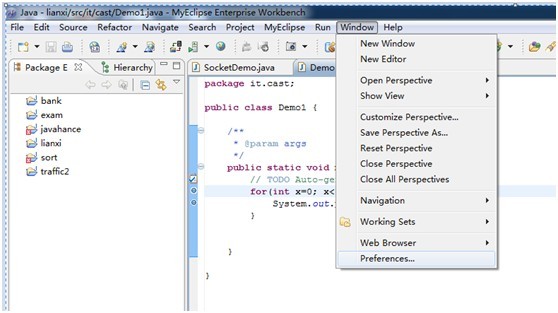
1.2.2
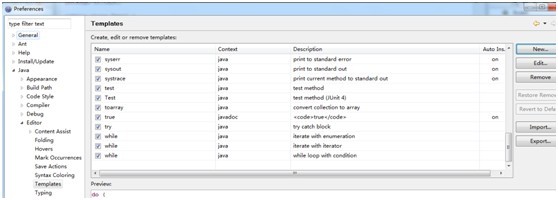
1.2.3 点击New,新建模板
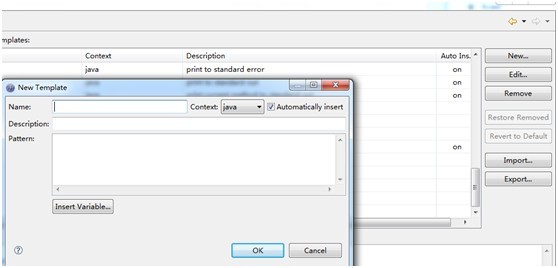
1.2.4添加自己的模板
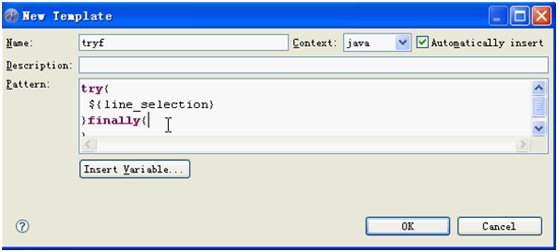
1.3 导入静态方法
import 语句可以导入一个类或某个包中的所有类
import static 语句导入一个类中的某个静态方法或所有静态方法
import static java.lang.Math.max;导入Math中的某一个类
imoort static java.lang.Math.*;导入Math中的所有静态方法
1.4可变参数:
问题:一个方法接受的参数个数不固定,例如:
System.out.println(countScore(2,3,5));
System.out.println(countScore(1,2,3,5));
1.4.1可变参数的特点:
只能出现在参数列表的最后;
...位于变量类型和变量名之间,前后有无空格都可以;
调用可变参数的方法时,编译器为该可变参数隐含创建一个数组,在方法体中以数组的形式访问可变参数。
练习一:可变参数的应用
public class VarableParameter {/*** @param args*/public static void main(String[] args) {// TODO Auto-generatedmethod stubSystem.out.println(add(2,3));System.out.println(add(2,3,5)); }public static int add(int x,int... args){int sum = x;for(int i=0;i<args.length;i++){sum += args[i];}return sum;}}1.5 高级For循环
高级For语法:
for ( type 变量名:集合变量名 ) { … }
注意事项:
迭代变量必须在( )中定义!
集合变量可以是数组或实现了Iterable接口的集合类
举例:
publicstatic int add(int x,int ...args) {intsum = x;for(intarg:args) {sum+= arg;}returnsum;}
练习二:高级For循环
public class VarableParameter {/*** @param args*/public static void main(String[] args) {// TODO Auto-generatedmethod stubSystem.out.println(add(2,3));System.out.println(add(2,3,5)); }public static int add(int x,int... args){int sum = x;for(int arg : args){sum += arg;}return sum;}}1.6 基本数据类型的自动拆箱与装箱
自动装箱:
Integer num1 = 12;
自动拆箱:
System.out.println(num1 + 12);
基本数据类型的对象缓存:
Integer num1 = 12;
Integer num2 = 12;
System.out.println(num1 == num2);
//输出true,在-128 – 127 之间的数可以存放在线程池里,属于一个地址,可重复调用
Integer num3 = 129;
Integer num4 = 129;
System.out.println(num3 == num4);
//输出false,在-128 – 127 之外的数,创建的是两个不同地址的对象
Integer num5 = Integer.valueOf(12);
Integer num6 = Integer.valueOf(12);
System.out.println(num5 == num6);
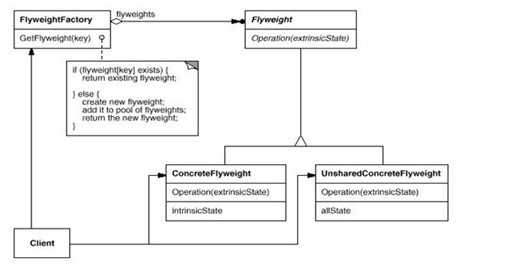
1.7享元模式:
英文:Flyweight
定义:设计模式中的享元模式,避免大量拥有相同内容的小类的开销(如耗费内存),使大家共享一个类(元类).
为什么使用?
面向对象语言的原则就是一切都是对象,但是如果真正使用起来,有时对象数可能显得很庞大,比如,字处理软件,如果以每个文字都作为一个对象,几千个字,对象数就是几千,无疑耗费内存,那么我们还是要"求同存异",找出这些对象群的共同点,设计一个元类,封装可以被共享的类,另外,还有一些特性是取决于应用(context),是不可共享的,这也是Flyweight中两个重要概念--内部状态intrinsic和外部状态extrinsic之分。
说白点,就是先捏一个的原始模型,然后随着不同场合和环境,再产生各具特征的具体模型,很显然,在这里需要产生不同的新对象,所以Flyweight模式中常出现Factory模式。Flyweight的内部状态是用来共享的,Flyweight factory负责维护一个Flyweight pool(模式池)来存放内部状态的对象。
Flyweight模式是一个提高程序效率和性能的模式,会大大加快程序的运行速度。应用场合很多:比如你要从一个数据库中读取一系列字符串,这些字符串中有许多是重复的,那么我们可以将这些字符串储存在Flyweight池(pool)中。
举例:
这里就以去餐馆吃饭为例详细的说明下享元模式的使用方式。去菜馆点菜吃饭的过程大家一定都是轻车熟路了,这里就不赘述。在例子中我使用了一个list来存放外蕴状态和内蕴状态的对应关系,而且提供了查询每个客人点菜情况的方法。内蕴状态在这里代表了菜肴的种类,而外蕴状态就是每盘菜肴的点菜人。
Flyweight模式一般由几个部分组成:
·Flyweight接口(抽象类) :定义了一个可共享的元类
·Flyweight实现类:实现了元类中的操作,而且可能会提供一个用于保存内部状态(共享属性)的空间
·Flyweight Factory:创建Flyweight的工厂类,创建后将其保存到Flyweight Pool中
·Flyweight Pool:缓冲Flyweight对象的池,通常包含在工厂类中
Flyweight模式的有效性很大程度上取决于如何使用它以及在何处使用它
当以下情况成立时使用Flyweight模式:
1 一个应用程序使用了大量的对象。
2 完全由于使用大量的对象,造成很大的存储开销。
3 对象的大多数状态都可以变为外部状态。
4 如果删除对象以外的状态那么可以用相对较少的共享对象取代很多组对象。
5 应用程序不依赖于对象标识。
其结构图如下所示:
这篇关于【新技术_01】Eclipes使用,可变参数,高级For循环,基本数据自动装箱拆箱的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


