本文主要是介绍精通推荐算法8:Embedding表征学习 -- 总体架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Embedding表征学习的总体架构
目前,推荐算法精排模型大多基于Embedding + MLP范式,模型底层是Embedding层,作用是将高维稀疏的输入特征转换为低维稠密的特征向量,并实现一定的模糊查找能力。模型上层是MLP层,作用是对特征向量进行交叉和融合,并提取高阶信息,得到最终输出。Embedding作为推荐模型的第一层,拥有绝大多数参数,意义重大。
Embedding表征学习分为向量构建和向量检索两部分。向量构建主要实现Embedding从无到有的过程,其主要方法有序列化建模、图模型构建和端到端学习。向量检索主要解决Top K近邻Embedding检索问题,其主要方法有哈希算法、基于树的算法、向量量化算法和近邻图算法等。
推荐算法Embedding表征学习的知识框架如图1所示。
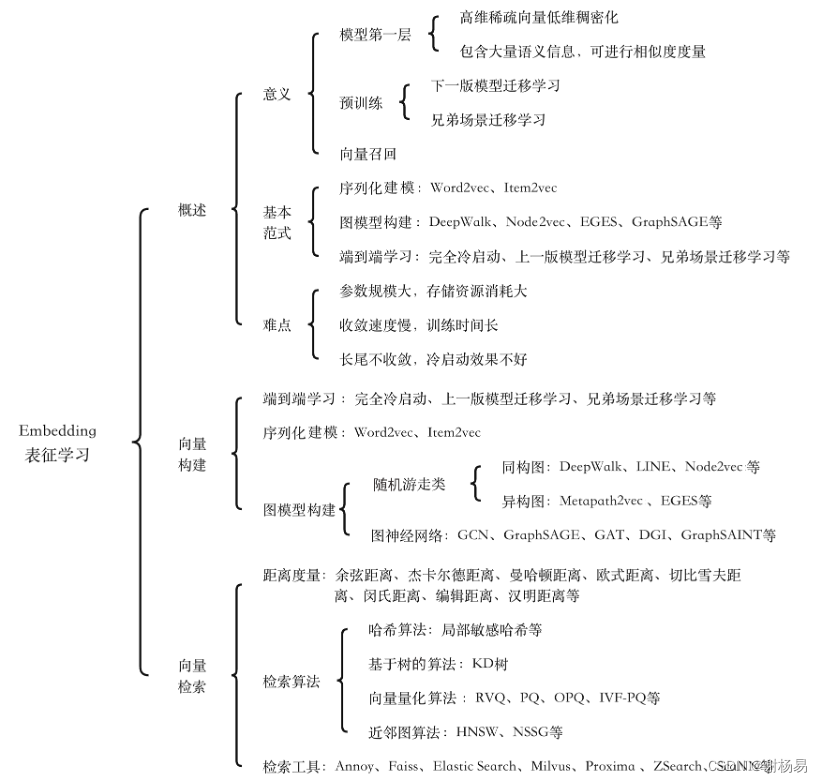
图1 Embedding表征学习的知识框架
2 Embedding概述
Embedding常被称为“嵌入”或“向量”,它可以将高维稀疏特征转换为低维稠密向量,实现降维,其最典型的应用是自然语言处理中的词向量(Word Embedding)。通过Embedding,我们可以将单词间的语义关系转换为向量间的距离关系。例如“书籍”和“书本”,两者语义很相似,词向量的余弦距离也很接近。
在推荐系统中,每个特征值都可以被向量化。例如用户ID、用户性别、物品ID和物品类目等。特征值的物理含义越接近,其Embedding向量距离越短。例如在电商场景中,“拖鞋”和“皮鞋”两个商品类目特征的向量距离,比“拖鞋”和“纸巾”要小,如图2所示。

图2 特征值物理含义越接近,Embedding向量距离越短
在深度学习中,Embedding可以通过一个全连接层实现。 原始输入数据通常是一个独热编码向量。由于输入数据一般是独热向量,因此全连接可以退化为一个查表操作。
3 Embedding表征学习的意义
Embedding是大多数推荐算法模型的第一层,其训练质量在很大程度上决定了模型的成败。Embedding表征学习已经在召回和排序等领域得到了广泛应用,意义重大,主要如下。
- Embedding是模型的第一层,可以将高维稀疏的输入特征转换为低维稠密的特征向量,输入上层全连接神经网络。同时,它包含大量语义信息,可以很好地度量特征间的相似度,并具备一定的模糊查找能力。一般来说,两个特征越相似,其Embedding向量距离越短。
- Embedding可以用于预训练。为了加快训练速度,可以将当前模型的Embedding作为下一版模型或者兄弟场景模型的预训练参数,从而实现热启动(Warm Start)。Embedding一般拥有推荐模型的绝大部分参数,因此模型训练速度往往取决于Embedding的收敛速度。预训练Embedding可以加快模型训练速度,并减少对样本量的依赖。另外,对于长尾特征Embedding难收敛的问题,预训练一般也能起到一定作用。
- Embedding可以应用在召回和排序等很多领域。利用Embedding向量可以计算任意用户和物品的相似度,从而为目标用户推荐与其距离最近的Top K物品,这就是典型的u2i召回。Embedding还可以计算物品和物品间的相似度,从而基于目标用户点击过或购买过的物品,推荐与之最相似的Top K物品,这就是典型的i2i召回。需要注意的是,不要直接把排序模型的Embedding用在召回任务上,二者的候选集和优化目标差别很大。
4 Embedding表征学习的基本范式
Embedding训练一直以来都是推荐算法中的难点,因为其参数规模很大,导致收敛速度慢。Embedding的训练方法主要有以下几种。
- 端到端学习。最简单的方法是将Embedding层参数随机初始化,然后和模型其他层一起训练。这种方法的一致性很好,可以保证Embedding与模型其他层的目标完全一致,但缺点也很明显,主要是整体训练速度受限于Embedding的收敛速度,且需要大量样本。除了随机初始化,还可以利用上一版模型或者兄弟场景模型对Embedding参数初始化,然后微调(Finetune),从而加快模型收敛速度。
- 序列化建模。类似于自然语言处理中的Word2vec,基于Skip-gram或CBOW算法对用户行为序列构建正负样本并训练模型,最终得到Embedding。Item2vec便采用了这种方法,6.2节会重点阐述。
- 图模型构建。先利用用户行为构建用户和物品关系图,然后训练模型并得到图节点的Embedding,主要有游走类和图神经网络两种方式。其中,游走类可以利用物品ID构建同构图,例如DeepWalk和Node2vec;也可以加入物品属性特征,构建异构图,例如Metapath2vec和EGES。图神经网络是一个很大的技术方向,也是目前推荐算法中比较前沿的技术,可以使用GraphSAGE、GAT、DGI、GraphSAINT和AdaGCN等经典模型,6.3、6.4、6.5节会重点阐述。

Skip-gram模型结构

DeepWalk的主要实现步骤

Metapath2vec和Metapath2vec++的Skip-gram网络结构图

EGES模型结构图

GraphSAGE应用流程图
5 Embedding表征学习的主要难点
Embedding表征学习的难点主要如下。
- 参数规模大,存储资源消耗大。特别是用户ID和物品ID等高维稀疏特征,其枚举值很多,必须使用维度较高的Embedding向量才能对其进行充分表征。Embedding的维度一般建议取特征枚举值个数的四次方根,枚举值多,向量维度高,会导致参数规模过大。Embedding通常会占据模型体积的80%以上,消耗极多的存储资源。
- 收敛速度慢,训练时间长。从梯度下降反向传播中可以看出,输入特征为0的Embedding向量无法更新。特征输入层往往比较稀疏,其他层则稠密得多,这导致Embedding层参数的训练机会比其他层少很多。另外,Embedding层需要训练的参数很多,这加剧了其收敛速度慢的问题。一般来说,模型整体训练时间取决于Embedding层的收敛速度,预训练Embedding对缓解这一问题有一定的作用。
- 长尾不收敛,冷启动效果不好。长尾特征值在样本中出现的概率低、数据稀疏,容易出现不收敛的问题,特别是对于用户ID和物品ID等高维特征,收敛难度更大,对冷启动造成了很大影响。近几年,Group Embedding方法的应用对缓解这一问题起到了一定的作用。
这篇关于精通推荐算法8:Embedding表征学习 -- 总体架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





