本文主要是介绍大模型部署框架 FastLLM 简要解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0x0. 前言
本文主要是对FastLLM做了一个简要介绍,展示了一下FastLLM的部署效果。然后以chatglm-6b为例,对FastLLM模型导出的流程进行了解析,接着解析了chatglm-6b模型部分的核心实现。最后还对FastLLM涉及到的优化技巧进行了简单的介绍。
0x1. 效果展示
按照 https://github.com/ztxz16/fastllm 中 README教程 编译fastllm之后,再按照教程导出一个 chatglm6b 模型参数文件(按照教程默认叫chatglm-6b-fp16.flm)。然后在编译时创建的 build 目录中执行./webui -p chatglm-6b-fp16.flm --port 1234 即可启动一个由FastLLM驱动的webui程序,效果如下:
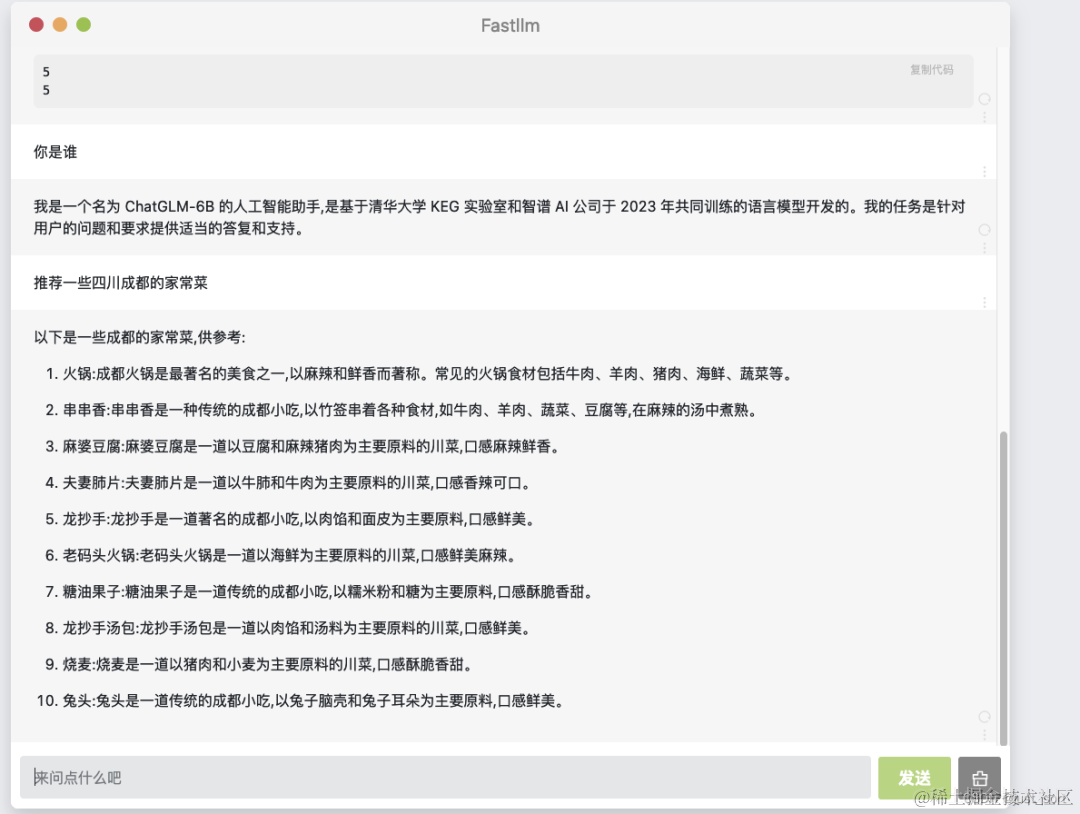
除了c++调用以外,FastLLM也基于PyBind导出了Python接口,支持简易python调用。并且FastLLM不仅支持Windows/Linux,还支持通过NDK将其编译到Android手机上进行使用。
另外在对话时,FastLLM支持了流式对话的效果,体验更好。并且FastLLM对批量推理进行了支持,也就是说如果有多个用户的请求进来,不管是否它们请求的长度是否相同都可以在FastLLM中组成一个batch来批量推理节约资源。
0x2. FastLLM chatglm-6b模型导出解析
首先解读一下FastLLM是如何导出huggingface的chatglm-6b模型的。
首先来看 fastllm/tools/fastllm_pytools/torch2flm.py 这个文件,这个文件实现了一个tofile函数用于将一个训练好的模型导出到一个文件中。具体来说,它包括以下几个步骤:
- 打开一个二进制文件,准备写入模型的数据。
- 写入一个版本号,用于后续的兼容性检查。
- 获取模型的配置信息,并将它们写入文件。如果提供了一些额外的配置参数,如 pre_prompt,user_role,bot_role,history_sep,也将它们添加到配置信息中。
- 如果提供了分词器(tokenizer),将分词器的词汇表写入文件。如果分词器是一个句子片段模型(sentence piece model),那么还会写入一些额外的信息。
- 获取模型的权重(包含在模型的状态字典中),并将它们写入文件。权重的名字和形状都会被写入文件,以便于后续正确地加载模型。
- 在每写入一个权重后,打印进度信息,以便于用户知道当前的进度。
- 最后,关闭文件。
更详细的解释可以请看:
代码语言:javascript
# struct 是Python的一个内置模块,提供了一些函数来解析打包的二进制数据。
# 在这个代码中,它被用于将整数和字符串转换为二进制格式。
import struct
import numpy as np# 定义一个函数 writeString,它接受两个参数:一个文件对象 fo 和一个字符串 s。
def writeString(fo, s):# struct.pack 函数将 len(s)(字符串 s 的长度)打包为一个二进制字符串,# 然后 fo.write 将这个二进制字符串写入文件。fo.write(struct.pack('i', len(s)));# s.encode() 将字符串 s 转换为二进制格式,然后 fo.write 将这个二进制字符串写入文件。fo.write(s.encode());# 定义一个函数 writeKeyValue,它接受三个参数:一个文件对象 fo,一个键 key 和一个值 value。
def writeKeyValue(fo, key, value):writeString(fo, key);writeString(fo, value);# 这段Python代码的主要作用是将模型的状态字典(state_dict)以及一些模型的配置信息保存到一个文件中。
# 定义了一个函数 tofile,它接受七个参数:一个文件路径 exportPath,一个模型对象 model,
# 和五个可选参数 tokenizer,pre_prompt,user_role,bot_role,history_sep。
def tofile(exportPath,model,tokenizer = None,pre_prompt = None,user_role = None,bot_role = None,history_sep = None):# 获取模型的状态字典。状态字典是一个Python字典,它保存了模型的所有权重和偏置。dict = model.state_dict();# 打开一个文件以写入二进制数据。fo = open(exportPath, "wb");# 0. version id# 写入一个版本号 2。fo.write(struct.pack('i', 2));# 0.1 model infomodelInfo = model.config.__dict__ # 获取模型配置的字典。if ("model_type" not in modelInfo):print("unknown model_type.");exit(0);# 如果提供了 pre_prompt,user_role,bot_role,history_sep,则将它们添加到 modelInfo 中。if (pre_prompt):modelInfo["pre_prompt"] = pre_prompt;if (user_role):modelInfo["user_role"] = user_role;if (bot_role):modelInfo["bot_role"] = bot_role;if (history_sep):modelInfo["history_sep"] = history_sep;# 如果模型是 "baichuan" 类型,并且模型有 "get_alibi_mask" 属性,# 则将一些额外的信息添加到 modelInfo 中。if (modelInfo["model_type"] == "baichuan" and hasattr(model, "model") and hasattr(model.model, "get_alibi_mask")):# Baichuan 2代modelInfo["use_alibi"] = "1";modelInfo["pre_prompt"] = "";modelInfo["user_role"] = tokenizer.decode([model.generation_config.user_token_id]);modelInfo["bot_role"] = tokenizer.decode([model.generation_config.assistant_token_id]);modelInfo["history_sep"] = "";# 写入 modelInfo 的长度。fo.write(struct.pack('i', len(modelInfo)));# 遍历 modelInfo 的每一个键值对,并使用 writeKeyValue 函数将它们写入文件。for it in modelInfo.keys():writeKeyValue(fo, str(it), str(modelInfo[it]));# 1. vocab# 判断是否提供了分词器 tokenizer。分词器是一个将文本分解为词或其他有意义的符号的工具。if (tokenizer):# 如果分词器有 "sp_model" 属性,这意味着分词器是# 一个句子片段模型(sentence piece model),这是一种特殊的分词方法。if (hasattr(tokenizer, "sp_model")):# 获取句子片段模型的大小(即词汇表的大小)。piece_size = tokenizer.sp_model.piece_size();fo.write(struct.pack('i', piece_size));# for i in range(piece_size): 遍历词汇表中的每一个词。for i in range(piece_size):# s = tokenizer.sp_model.id_to_piece(i).encode(); # 将词的ID转换为词本身,并将其编码为二进制字符串。s = tokenizer.sp_model.id_to_piece(i).encode();# 写入词的长度。fo.write(struct.pack('i', len(s)));# 遍历词的每一个字符,并将其写入文件。for c in s:fo.write(struct.pack('i', c));# 写入词的ID。fo.write(struct.pack('i', i));else:# 如果分词器没有 "sp_model" 属性,那么它就是一个普通的分词器。# 在这种情况下,它将获取词汇表,然后遍历词汇表中的每一个词,将词和对应的ID写入文件。vocab = tokenizer.get_vocab();fo.write(struct.pack('i', len(vocab)));for v in vocab.keys():s = v.encode();fo.write(struct.pack('i', len(s)));for c in s:fo.write(struct.pack('i', c));fo.write(struct.pack('i', vocab[v]));else:# 如果没有提供分词器,那么它将写入一个0,表示词汇表的大小为0。fo.write(struct.pack('i', 0));# 2. weight# 写入模型状态字典的长度,即模型的权重数量。fo.write(struct.pack('i', len(dict)));tot = 0;# 遍历模型状态字典中的每一个键值对。键通常是权重的名字,值是权重的值。for key in dict:# 将权重的值转换为NumPy数组,并确保其数据类型为float32。cur = dict[key].numpy().astype(np.float32);# 写入权重名字的长度。fo.write(struct.pack('i', len(key)));# 将权重名字编码为二进制字符串,然后写入文件。fo.write(key.encode());# 写入权重的维度数量。fo.write(struct.pack('i', len(cur.shape)));# 遍历权重的每一个维度,将其写入文件。for i in cur.shape:fo.write(struct.pack('i', i));# 写入一个0,可能是为了标记权重值的开始。fo.write(struct.pack('i', 0));# 将权重的值写入文件。fo.write(cur.data);# 记录已经写入的权重数量。tot += 1;# 打印进度信息。print("output (", tot, "/", len(dict), end = " )\r");print("\nfinish.");fo.close(); # 最后,关闭文件。
以ChatGLM为例,在模型导出时执行的命令如下:
代码语言:javascript
# 需要先安装ChatGLM-6B环境
# 如果使用自己finetune的模型需要修改chatglm_export.py文件中创建tokenizer, model的代码
# 如果使用量化模型,需要先编译好quant文件,这里假设已经存在build/quant文件
cd build
python3 tools/chatglm_export.py chatglm-6b-fp32.flm # 导出浮点模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-fp16.flm -b 16 #导出float16模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-int8.flm -b 8 #导出int8模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-int4.flm -b 4 #导出int4模型
所以我们接着解读一下chatglm_export.py。
代码语言:javascript
# 这段代码的主要功能是从预训练模型库中加载一个模型和对应的分词器,
# 并将它们导出为一个特定的文件格式(在这个例子中是 .flm 格式)。以下是代码的详细解析:
# 导入Python的sys模块,它提供了一些与Python解释器和环境交互的函数和变量。
# 在这段代码中,它被用于获取命令行参数。
import sys
# 从transformers库中导入AutoTokenizer和AutoModel。transformers库是一个提供大量预训练模型的库,
# AutoTokenizer和AutoModel是用于自动加载这些预训练模型的工具。
from transformers import AutoTokenizer, AutoModel
# 从fastllm_pytools库中导入torch2flm模块。
# 这个模块可能包含了一些将PyTorch模型转换为.flm格式的函数。
from fastllm_pytools import torch2flmif __name__ == "__main__":# 从预训练模型库中加载一个分词器。"THUDM/chatglm-6b"是模型的名字。tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)# 从预训练模型库中加载一个模型,并将它转换为浮点类型。model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()# 将模型设置为评估模式。这是一个常见的操作,用于关闭模型的某些特性,# 如dropout和batch normalization。model = model.eval()# 获取命令行参数作为导出文件的路径。如果没有提供命令行参数,# 那么默认的文件名是"chatglm-6b-fp32.flm"。exportPath = sys.argv[1] if (sys.argv[1] is not None) else "chatglm-6b-fp32.flm";# 使用torch2flm的tofile函数将模型和分词器导出为.flm文件。torch2flm.tofile(exportPath, model, tokenizer)
这里的torch2flm.tofile就是我们上面解析的函数。
0x3. FastLLM chatglm-6b模型支持流程解析
在FastLLM中要支持一个新的模型需要在fastllm/include/models这个目录下进行扩展,我们这里以chatgm6b为例简单解析一下流程。首先我们在fastllm/include/models下定义一个chatglm.h头文件:
代码语言:javascript
//
// Created by huangyuyang on 5/11/23.
//#ifndef FASTLLM_CHATGLM_H
#define FASTLLM_CHATGLM_H#include "basellm.h"
#include "cmath"#include <iostream>namespace fastllm {class ChatGLMModel: public basellm {public:ChatGLMModel (); // 构造函数// 推理virtual int Forward(const Data &inputIds,const Data &attentionMask,const Data &positionIds,std::vector <std::pair <Data, Data> > &pastKeyValues,const GenerationConfig &generationConfig = GenerationConfig(),const LastTokensManager &lastTokens = LastTokensManager());std::vector <int> ForwardBatch(int batch,const Data &inputIds,const Data &attentionMask,const Data &positionIds,std::vector <std::pair <Data, Data> > &pastKeyValues,const GenerationConfig &generationConfig = GenerationConfig(),const LastTokensManager &lastTokens = LastTokensManager());std::vector <int> ForwardBatch(int batch,const Data &inputIds,const std::vector <Data*> &attentionMask,const std::vector <Data*> &positionIds,const std::vector <int> &seqLens,std::vector <std::pair <Data*, Data*> > &pastKeyValues,const std::vector <GenerationConfig> &generationConfigs,const LastTokensManager &lastTokens = LastTokensManager());virtual std::string Response(const std::string& input,RuntimeResult retCb,const GenerationConfig &generationConfig = GenerationConfig()); // 根据给出的内容回复virtual void ResponseBatch(const std::vector <std::string> &inputs,std::vector <std::string> &outputs,RuntimeResultBatch retCb,const GenerationConfig &generationConfig = GenerationConfig());virtual int LaunchResponseTokens(const std::vector <int> &inputTokens,const GenerationConfig &generationConfig = GenerationConfig()); // 启动一个response任务,返回分配的handleIdvirtual int FetchResponseTokens(int handelId); // 获取指定handle的输出, -1代表输出结束了virtual void WarmUp(); // 预热virtual std::string MakeInput(const std::string &history, int round, const std::string &input); // 根据历史信息和当前输入生成promptvirtual std::string MakeHistory(const std::string &history, int round, const std::string &input, const std::string &output); // 根据当前回复更新historyint GetVersion();private:virtual void CausalMask(Data &data, int start) {}; // 因果mask?};
}#endif //FASTLLM_CHATGLM_H
这个ChatGLMModel类继承了basellm类并重写了它的几个成员函数来完成完整的功能。接下来对这里涉及到的一些函数进行解析:
ChatGLMModel::ChatGLMModel()构造函数
代码语言:javascript
ChatGLMModel::ChatGLMModel() {this->model_type = "chatglm"; //这行代码设置类的 model_type 成员变量为 "chatglm"。this 是一个指向当前对象的指针。this->bos_token_id = 130004; // 设置句子的开始标记this->eos_token_id = 130005; // 设置句子的结束标记// 这两行代码调整 sin 和 cos 向量的大小以匹配 max_positions。sin.resize(max_positions); cos.resize(max_positions);std::vector <float> invFreq;// // 这部分代码计算了一系列频率的倒数,并将结果存储在 invFreq 向量中。for (int i = 0; i < rotary_dim; i += 2) {invFreq.push_back(1.0 / pow(10000, (float)i / rotary_dim));}// 使用这些倒数 和 位置索引 i 来计算正弦和余弦值,并将这些值存储在 sin 和 cos 向量中。for (int i = 0; i < max_positions; i++) {sin[i].resize(rotary_dim);cos[i].resize(rotary_dim);for (int j = 0; j < invFreq.size(); j++) {sin[i][j] = ::sin((float)i * invFreq[j]);cos[i][j] = ::cos((float)i * invFreq[j]);}}std::vector <float> fsin, fcos;for (int i = 0; i < sin.size(); i++) {for (int j = 0; j < sin[0].size(); j++) {fsin.push_back(sin[i][j]);fcos.push_back(cos[i][j]);}}// 这两行代码将 sin 和 cos 向量中的数据复制到 sinData 和 cosData 对象中。sinData.CopyFrom(Data(DataType::FLOAT32, {(int)this->sin.size(), (int)this->sin[0].size()}, fsin));cosData.CopyFrom(Data(DataType::FLOAT32, {(int)this->cos.size(), (int)this->cos[0].size()}, fcos));// 这部分代码根据版本号设置 weight.embeddingNames 成员变量的值。if (GetVersion() == 1) {weight.embeddingNames.insert("transformer.word_embeddings.weight");} else if (GetVersion() == 2) {weight.embeddingNames.insert("transformer.embedding.word_embeddings.weight");}}
ChatGLMModel::ForwardBatch 函数解析
我在下面的代码里面逐步添加了一些注释,这里的c++代码都对应了huggingface上面的chatglm-6b和chatglm2-6b的模型定义和推理的代码。我不仅加了注释,还把中间tensor的维度变化也标注出来了,对KV Cache的实现也加了解释。我在这里发现了唯一一个和python代码对不上的问题是在self attention的softmax之前有一行Mul(attnProbs, i + 1, attnProbs);,这行代码我不是很确定作用,我猜测是让attnProbs更大一些来降低数值溢出的风险?在huggingface的实现中是不存在这一行代码的。
代码语言:javascript
// 这个函数是 ChatGLMModel 类的一个成员函数,名为 ForwardBatch。用于处理一批数据的前向传播。
std::vector <int> ChatGLMModel::ForwardBatch(int batch,const Data &inputIds,const Data &attentionMask,const Data &positionIds,std::vector <std::pair <Data, Data> > &pastKeyValues,const GenerationConfig &generationConfig,const LastTokensManager &lastTokens) {// 获取 inputIds 的第二个维度大小,存储在 maxLen 中,代表输入序列的最大长度。int maxLen = inputIds.dims[1];// 声明了一系列 Data 类型的变量,这些变量用于存储中间计算结果。Data inputEmbeddings;Data attenInput;Data qkv, q, k, v;Data attnProbs;Data attnOutput;Data contextLayer;Data mlpInput;Data middle, middle2;Data temp;// 定义一个整型向量,可能用于存储最后的返回结果。std::vector<int> lastRet;// ChatGLMBlock// 调用 GetVersion 函数获取模型的版本。int version = GetVersion();// 根据版本设置 weightPre 和 weightMiddle 的值,这两个变量会被用于构造权重的名称。std::string weightPre, weightMiddle;if (version == 1) {weightPre = "transformer.layers.";weightMiddle = ".attention";} else if (version == 2) {weightPre = "transformer.encoder.layers.";weightMiddle = ".self_attention";}// ChatGLM2// 定义一个 Data 类型的变量 inputIdsPermute,用于存储置换后的输入 ID。Data inputIdsPermute;// 对 inputIds 进行置换,将batch维度和序列长度维度交换。//【bs, seq_length, hidden_size】->【seq_length, bs, hidden_size】Permute(inputIds, {1, 0}, inputIdsPermute);// 调用 Embedding 函数,对输入的单词 ID 进行嵌入,生成 inputEmbeddings。Embedding(inputIdsPermute, this->weight["transformer" + std::string((version == 2 ? ".embedding" : "")) +".word_embeddings.weight"], inputEmbeddings);// 定义一个引用 hiddenStates,指向 inputEmbeddings,// 在后续的操作中,对 hiddenStates 的修改也会改变 inputEmbeddings。 Data &hiddenStates = inputEmbeddings;// 针对每个 Transformer 的 block 进行操作。在每个循环中:for (int i = 0; i < block_cnt; i++) {// 首先,使用 LayerNorm 或 RMSNorm 对 hiddenStates 进行归一化操作,得到 attenInput。if (version == 1) {std::string inputLNWeightName = "transformer.layers." + std::to_string(i) + ".input_layernorm.weight";std::string inputLNBiasName = "transformer.layers." + std::to_string(i) + ".input_layernorm.bias";LayerNorm(hiddenStates, weight[inputLNWeightName], weight[inputLNBiasName], -1, attenInput);} else if (version == 2) {std::string inputRMSWeightName ="transformer.encoder.layers." + std::to_string(i) + ".input_layernorm.weight";RMSNorm(hiddenStates, weight[inputRMSWeightName], 1e-5, attenInput);}// 使用 Linear 函数对 attenInput 进行线性变换,得到 qkv。std::string qkvWeightName = weightPre + std::to_string(i) + weightMiddle + ".query_key_value.weight";std::string qkvBiasName = weightPre + std::to_string(i) + weightMiddle + ".query_key_value.bias";Linear(attenInput, weight[qkvWeightName], weight[qkvBiasName], qkv);// 对 qkv 进行一些操作(如 Reshape、Split、RotatePosition2D // 或 NearlyRotatePosition2D),得到 Q、K、V。if (version == 1) {qkv.Reshape({qkv.dims[0], qkv.dims[1], num_attention_heads, -1});int per = qkv.dims.back() / 3;Split(qkv, -1, 0, per, q);Split(qkv, -1, per, per * 2, k);Split(qkv, -1, per * 2, per * 3, v);fastllm::RotatePosition2D(q, positionIds, sinData, cosData, rotary_dim);fastllm::RotatePosition2D(k, positionIds, sinData, cosData, rotary_dim);} else if (version == 2) {int qLen = embed_dim, kvLen = (qkv.dims.back() - embed_dim) / 2;Split(qkv, -1, 0, qLen, q);Split(qkv, -1, qLen, qLen + kvLen, k);Split(qkv, -1, qLen + kvLen, qLen + kvLen + kvLen, v);q.Reshape({q.dims[0], q.dims[1], -1, embed_dim / num_attention_heads});k.Reshape({k.dims[0], k.dims[1], -1, embed_dim / num_attention_heads});v.Reshape({v.dims[0], v.dims[1], -1, embed_dim / num_attention_heads});fastllm::NearlyRotatePosition2D(q, positionIds, sinData, cosData, rotary_dim);fastllm::NearlyRotatePosition2D(k, positionIds, sinData, cosData, rotary_dim);}// q, k, v, shape => 【seq_length, batch, num_attention_head, hidden_size / num_attention_head】// 从 pastKeyValues 中获取第 i 个元素,该元素是一个 pair,将其两个元素分别赋给 // pastKey 和 pastValue,注意这里使用了引用,所以对 pastKey 和 pastValue // 的修改会影响 pastKeyValues。Data &pastKey = pastKeyValues[i].first, &pastValue = pastKeyValues[i].second;// 如果 GetKVCacheInCPU() 返回 true,则将 pastKey 和 pastValue 的 lockInCPU // 属性设置为 true,这可能意味着这两个数据将被锁定在 CPU 上;// 否则,将 pastKey 和 pastValue 移动到 CUDA 设备上,// 这可能意味着这两个数据将被移动到 GPU 上进行计算。if (GetKVCacheInCPU()) {pastKey.lockInCPU = true;pastValue.lockInCPU = true;} else {pastKey.ToDevice(DataDevice::CUDA);pastValue.ToDevice(DataDevice::CUDA);};// 调整 K 和 V 的形状。k.Resize({k.dims[0], k.dims[1] * k.dims[2], k.dims[3]});v.Resize({v.dims[0], v.dims[1] * v.dims[2], v.dims[3]});// 对 K 和 V 进行置换,将batch维度和序列长度维度交换。// 【seq_length, batch * num_attention_head, hidden_size / num_attention_head】=>// 【batch * num_attention_head, seq_length, hidden_size / num_attention_head】PermuteSelf(k, {1, 0, 2});PermuteSelf(v, {1, 0, 2});// 定义一个变量 unitLen,并赋值为 64。#ifdef USE_CUDA 判断是否定义了 // USE_CUDA,如果定义了,则将 unitLen 设置为 128。这个变量可能与后面的内存扩展有关。int unitLen = 64;
#ifdef USE_CUDAunitLen = 128;
#endif// 接下来的两个 while 循环对 pastKey 和 pastValue 进行扩展。// 具体来说,如果 pastKey 或 pastValue 的大小小于 K 或 V 的大小,// 则将 pastKey 或 pastValue 的大小扩展到满足需要的最小值。// 这里的 unitLen 可能是为了保证扩展后的大小是 unitLen 的整数倍,以提高内存访问效率。// 这里扩展的原因是因为KV Cache会把pastKey,pastValue越concat越大,所以需要动态扩容while ((pastKey.dims.size() == 0 &&(pastKey.expansionDims.size() == 0 || k.dims[1] > pastKey.expansionDims[1]))|| (pastKey.dims.size() > 0 && (pastKey.expansionDims.size() == 0 ||pastKey.dims[1] + k.dims[1] > pastKey.expansionDims[1]))) {std::vector<int> newDims;if (pastKey.Count(0) == 0 || pastKey.dims.size() == 0) {newDims = std::vector<int>{k.dims[0], ((k.dims[1] - 1) / unitLen + 1) * unitLen, k.dims[2]};if (generationConfig.output_token_limit > 0) {newDims[1] = std::min(newDims[1], k.dims[1] + generationConfig.output_token_limit);}} else {newDims = pastKey.dims;newDims[1] += ((k.dims[1] - 1) / unitLen + 1) * unitLen;}pastKey.Expansion(newDims);}while ((pastValue.dims.size() == 0 &&(pastValue.expansionDims.size() == 0 || v.dims[1] > pastValue.expansionDims[1]))|| (pastValue.dims.size() > 0 && (pastValue.expansionDims.size() == 0 ||pastValue.dims[1] + v.dims[1] > pastValue.expansionDims[1]))) {std::vector<int> newDims;if (pastValue.Count(0) == 0 || pastValue.dims.size() == 0) {newDims = std::vector<int>{v.dims[0], ((v.dims[1] - 1) / unitLen + 1) * unitLen, v.dims[2]};if (generationConfig.output_token_limit > 0) {newDims[1] = std::min(newDims[1], k.dims[1] + generationConfig.output_token_limit);}} else {newDims = pastValue.dims;newDims[1] += ((v.dims[1] - 1) / unitLen + 1) * unitLen;}pastValue.Expansion(newDims);}// KV Cache的concat过程CatDirect(pastKey, k, 1);CatDirect(pastValue, v, 1);//q.shape 【seq_length, batch, num_attention_head, hidden_size / num_attention_head】// outputSize 【batch, num_attention_head, query seq_length, pastKey seq_length】std::vector<int> outputSize = {q.dims[1], q.dims[2], q.dims[0], pastKey.dims[1]};// q.shape 【seq_length, batch * num_attention_head, hidden_size / num_attention_head】q.Reshape({q.dims[0], q.dims[1] * q.dims[2], q.dims[3]});// q.shape 【batch * num_attention_head, seq_length, hidden_size / num_attention_head】PermuteSelf(q, {1, 0, 2});// 1.2 Attention// 1.2.0 q * k^T// q.shape 【batch * num_attention_head, query seq_length, hidden_size / num_attention_head】q.Reshape({pastKey.dims[0], -1, q.dims[2]});// pastKey.shape 【batch * num_attention_head, pastKey seq_length,hidden_size / num_attention_head】// pastKey^T.shape 【batch * num_attention_head,hidden_size / num_attention_head,pastKey seq_length】// attnProbs.shape 【batch * num_attention_head,query seq_length, pastKey seq_length】MatMulTransB(q, pastKey, attnProbs, 1.0 / (scale_attn * (i + 1)));attnProbs.Reshape(outputSize);// 1.2.1 Mask// 如果 attentionMask 的维度不为0,那么就对注意力概率(attnProbs)应用 attentionMask,// 这是注意力机制中的一个重要步骤,可以屏蔽掉一些不需要的信息。if (attentionMask.dims.size() != 0) {AttentionMask(attnProbs, attentionMask, -10000);}// 1.2.2 softmax// 将注意力概率与i + 1相乘,然后对结果应用 softmax 函数,使得所有的注意力概率之和为 1。Mul(attnProbs, i + 1, attnProbs);Softmax(attnProbs, attnProbs, -1);// 定义输出的大小,然后根据这个大小重新reshape attnProbs。// outputSize.shape [1, batch * num_attention_head, query seq_length, pastKey seq_length]outputSize = {1, pastValue.dims[0], q.dims[1], pastValue.dims[1]};attnProbs.Reshape({outputSize[0] * outputSize[1], outputSize[2], -1});// 1.2.3 prob * vattnProbs.Reshape({pastValue.dims[0], -1, attnProbs.dims[2]});MatMul(attnProbs, pastValue, contextLayer);contextLayer.Reshape({batch, num_attention_heads, maxLen, -1});PermuteSelf(contextLayer, {2, 0, 1, 3});contextLayer.Reshape({contextLayer.dims[0], contextLayer.dims[1], embed_dim});// 1.2.4 densestd::string denseWeightName = weightPre + std::to_string(i) + weightMiddle + ".dense.weight";std::string denseBiasName = weightPre + std::to_string(i) + weightMiddle + ".dense.bias";Linear(contextLayer, weight[denseWeightName], weight[denseBiasName], attnOutput);// 1.3if (GetVersion() == 1) {float alpha = sqrt(2 * block_cnt);Mul(attenInput, alpha, hiddenStates);AddTo(hiddenStates, attnOutput);std::string postLNWeightName ="transformer.layers." + std::to_string(i) + ".post_attention_layernorm.weight";std::string postLNBiasName ="transformer.layers." + std::to_string(i) + ".post_attention_layernorm.bias";LayerNorm(hiddenStates, weight[postLNWeightName], weight[postLNBiasName], -1, mlpInput);// 1.4 MLPstd::string fcInKeyName = "transformer.layers." + std::to_string(i) + ".mlp.dense_h_to_4h";std::string fcOutKeyName = "transformer.layers." + std::to_string(i) + ".mlp.dense_4h_to_h";Linear(mlpInput, weight[fcInKeyName + ".weight"], weight[fcInKeyName + ".bias"], middle);GeluNew(middle, middle);Linear(middle, weight[fcOutKeyName + ".weight"], weight[fcOutKeyName + ".bias"], hiddenStates);AddTo(hiddenStates, mlpInput, alpha);} else {AddTo(hiddenStates, attnOutput);std::string postRMSWeightName ="transformer.encoder.layers." + std::to_string(i) + ".post_attention_layernorm.weight";Mul(hiddenStates, 1.0, temp);RMSNorm(hiddenStates, weight[postRMSWeightName], 1e-5, mlpInput);// 1.4 MLPstd::string fcInKeyName = "transformer.encoder.layers." + std::to_string(i) + ".mlp.dense_h_to_4h";std::string fcOutKeyName = "transformer.encoder.layers." + std::to_string(i) + ".mlp.dense_4h_to_h";Linear(mlpInput, weight[fcInKeyName + ".weight"], weight[fcInKeyName + ".bias"], middle);Swiglu(middle, middle2);Linear(middle2, weight[fcOutKeyName + ".weight"], weight[fcOutKeyName + ".bias"], hiddenStates);AddTo(hiddenStates, temp);}}// 定义 logits 和 topk,这可能是为了保存模型的输出和最终的预测结果。Data logits, topk;// 接下来的代码块根据 version 的值进行不同的操作,主要包括应用层归一化和线性变换,// 得到模型的输出 logits。if (version == 1) {LayerNorm(hiddenStates, weight["transformer.final_layernorm.weight"],weight["transformer.final_layernorm.bias"], -1, hiddenStates);Linear(hiddenStates, weight["lm_head.weight"], Data(), logits);} else {RMSNorm(hiddenStates, weight["transformer.encoder.final_layernorm.weight"], 1e-5, hiddenStates);Linear(hiddenStates, weight["transformer.output_layer.weight"], Data(), logits);}// 如果生成配置指定了简单的贪心策略,那么就从 logits 中找出最大的值作为预测结果;// 否则,使用 LLMSampling 函数根据 logits 和生成配置来选择预测结果。if (generationConfig.IsSimpleGreedy()) {TopK(logits, topk, 1);topk.ToDevice(DataDevice::CPU);for (int b = 0; b < batch; b++) {int base = (maxLen - 1) * batch + b;lastRet.push_back((int) (((float *) topk.cpuData)[base * 2] + 1e-3));}} else {for (int b = 0; b < batch; b++) {int base = (maxLen - 1) * batch + b;lastRet.push_back(LLMSampling(logits, base, generationConfig, lastTokens.units[b]));}}return lastRet;}
还有一个同名的ForwardBatch函数,和上面这个函数的区别在于它支持对不同的seq_length组的batch进行推理,简单来说就是在上面的基础上对batch进行了一个loop。
ChatGLMModel::Response 函数解析
代码语言:javascript
std::string ChatGLMModel::Response(const std::string& input, RuntimeResult retCb,const GenerationConfig &generationConfig) {// 在模型的权重字典中查找“gmask_token_id”,如果找到了就将其值转化为整数,// 如果没找到就将其设为130001。int gmask_token_id = this->weight.dicts.find("gmask_token_id") != this->weight.dicts.end() ?atoi(this->weight.dicts["gmask_token_id"].c_str()) : 130001;
#ifdef USE_CUDA// 清理 CUDA 的大缓冲区。FastllmCudaClearBigBuffer();
#endif// 对输入的字符串进行编码,得到一个表示输入的整数数组 inputIds。Data inputIds = this->weight.tokenizer.Encode(input);std::vector <float> ids;// 将 inputIds 的值复制到 ids 中。for (int i = 0; i < inputIds.Count(0); i++) {ids.push_back(((float*)inputIds.cpuData)[i]);}// 根据版本号,在 ids 的末尾或开头插入特定的整数值。if (GetVersion() == 1) {ids.push_back(gmask_token_id);ids.push_back(bos_token_id);} else if (GetVersion() == 2) {ids.insert(ids.begin(), 64792);ids.insert(ids.begin(), 64790);}int seqLen = ids.size();// 根据 ids 创建一个新的 Data 对象,并将其复制给 inputIds。inputIds.CopyFrom(Data(DataType::FLOAT32, {1, seqLen}, ids));std::vector <float> vmask = std::vector <float> (seqLen * seqLen, 0);std::vector <float> vpids = std::vector <float> (seqLen * 2, 0);for (int i = 0; i < seqLen - 1; i++) {vmask[i * seqLen + seqLen - 1] = 1;vpids[i] = i;}// 为 vmask 和 vpids 初始化值。vpids[seqLen - 1] = seqLen - 2;vpids[seqLen * 2 - 1] = 1;// 如果版本号为 2,那么重新为 vmask 和 vpids 分配值。if (GetVersion() == 2) {for (int i = 0; i < seqLen; i++) {vpids[i] = i;for (int j = i + 1; j < seqLen; j++) {vmask[i * seqLen + j] = 1;}}}// 根据 vmask 和 vpids 创建 attentionMask 和 positionIds。Data attentionMask = Data(DataType::FLOAT32, {seqLen, seqLen}, vmask);Data positionIds = Data(DataType::FLOAT32, {2, seqLen}, vpids);// 创建一个包含 block_cnt 个空 Data 对象的向量 pastKeyValues。std::vector <std::pair <Data, Data> > pastKeyValues;for (int i = 0; i < block_cnt; i++) {pastKeyValues.push_back(std::make_pair(Data(DataType::FLOAT32),Data(DataType::FLOAT32)));}// 定义一个空的字符串 retString,它将用于存储生成的文本。std::string retString = "";// len 代表生成的文本长度,初始化为 1。// maskIds 用于在某些情况下标记生成的文本,初始化为 -1。int len = 1, maskIds = -1;// 定义一个浮点数向量 results,它将用于存储生成的单词或字符的编码。std::vector <float> results;// 定义一个整数变量 index,并初始化为 0。// 这个变量可能用于追踪生成过程中的步骤数或其他类似的目的。int index = 0;// 创建一个 LastTokensManager 类型的对象 tokens。该对象用于管理生成过程中的最后一个token。LastTokensManager tokens (1, generationConfig.last_n);// 这个循环用于生成文本,直到满足某个退出条件。while (true) {// 记录当前时间,可能用于后续计算生成文本所需的时间。auto st = std::chrono::system_clock::now();// 调用 Forward 函数生成下一个令牌,并将生成的token存储在 ret 中。int ret = Forward(inputIds, attentionMask, positionIds, pastKeyValues, generationConfig, tokens);// 将生成的token ret 添加到 tokens 对象的第一个单元中。tokens.units[0].Push(ret);// 如果生成的token ret 是结束token(eos_token_id),则跳出循环。if (ret == eos_token_id) {break;}// 将生成的token ret 添加到 results 向量中。results.push_back(ret);// 将 results 向量中的token解码为字符串 curString。std::string curString = weight.tokenizer.Decode(Data(DataType::FLOAT32, {(int)results.size()}, results)).c_str();// 将解码得到的字符串 curString 添加到 retString 中。retString += curString;if (retCb)
#ifdef PY_APIretCb(index, pybind11::bytes(retString));
#elseretCb(index, curString.c_str());
#endif// 增加生成进度 index。index++;// 刷新标准输出流,将所有未写入的数据写入。fflush(stdout);// 清空 results 向量,为生成下一个token做准备。results.clear();len++; // 增加生成的文本长度 len。if (maskIds == -1) {// 如果 maskIds 为 -1,说明这是第一次生成token,因此设置 maskIds 的值。maskIds = (int)ids.size() - (GetVersion() == 1 ? 2 : 0);}// 将 attentionMask 和 positionIds 移动到 CPU 设备上。attentionMask.ToDevice(DataDevice::CPU);positionIds.ToDevice(DataDevice::CPU);// 更新 inputIds 为最新生成的token ret。inputIds.CopyFrom(Data(DataType::FLOAT32, {1, 1}, {(float)ret}));// 更新 attentionMask 和 positionIds。attentionMask = Data();positionIds.CopyFrom(Data(DataType::FLOAT32, {2, 1}, {(float)maskIds, (float)(len)}));// 如果使用的模型版本是 2,增加 maskIds。if (GetVersion() == 2) {maskIds++;}// 如果生成的令牌数量 index 已经达到了设定的输出token限制,break if (index == generationConfig.output_token_limit) {break;}// printf("len = %d, spend %f s.\n", len, GetSpan(st, std::chrono::system_clock::now()));}if (retCb)
#ifdef PY_APIretCb(-1, pybind11::bytes(retString));
#elseretCb(-1, retString.c_str());
#endifreturn retString;}
这里需要注意的是对于postionIds的更新对应的huggingface代码链接在:https://huggingface.co/THUDM/chatglm2-6b/blob/main/modeling_chatglm.py#L881-L887 。
核心部分的实现就是这2个函数,其它函数读者感兴趣可以自行阅读这里的源码。要在FastLLM中自定义一个模型,需要实现的核心部分就是这个模型文件了,从目前FastLLM提供的组件来看,基于Transformer架构的开源大模型支持的难度和工作量会比较小,而对于新的架构比如RWKV支持起来就会比较麻烦,需要写大量算子,如果考虑到优化则工作量就会更大。
比较期待FastLLM推出ONNX的支持,这样就可以更方便的和各种类型的大模型对接起来。
0x4. FastLLM 优化技巧简介
FastLLM支持X86/Arm/CUDA 3种架构的硬件,也就是说它的算子分别考虑了这几个架构的优化。此外,FastLLM除了支持FP32/FP16/BF16之外还支持INT8/INT4量化计算。所以FastLLM的优化就是在不同的平台上为不同的Bit数的数据实现Kernel,并且使用硬件特有的指令集来进行加速比如AVX2,Neon Instrics。在CUDA实现上,FastLLM并没有采用kernel fuse的方式进行进一步加速,这里的优化空间还是比较大的。
介于篇幅原因,更多的系统和Kernel实现细节在后面的文章讨论。
0x5. 总结
本文主要是对FastLLM做了一个简要介绍,展示了一下FastLLM的部署效果。然后以chatglm-6b为例,对FastLLM模型导出的流程进行了解析,接着解析了chatglm-6b模型部分的核心实现,这部分代码基本是对huggingface的chatglm-6b代码进行了一对一翻译。最后还对FastLLM涉及到的优化技巧进行了简单的介绍。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

这篇关于大模型部署框架 FastLLM 简要解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







