本文主要是介绍第 5 章. Vulkan 中的命令缓冲区以及内存管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第 5 章. Vulkan 中的命令缓冲区以及内存管理
命令缓冲区是若干命令的集合,它会被提交给适当的硬件队列供 GPU 进行处理。 然后,在真正的 GPU 处理开始之前,驱动程序会提取命令缓冲区并对其进行验证和编译。
本章将介绍命令缓冲区的概念。 我们将学习命令池的创建,命令缓冲区的分配、释放以及命令的记录。 我们会实现命令缓冲区并在下一章中使用它们驱动交换链。 交换链抽象了与平台界面交互的机制,并提供一组可用于执行渲染的图像。 一旦完成渲染,图像就会显示到本地的窗口系统。
在本章的后半部分,我们会了解 Vulkan 中的内存管理。 我们会讨论主机内存和设备内存的概念。 我们会研究内存分配器来管理主机内存的分配。 在本章的最后,我们将深入研究设备内存,并学习分配、释放以及通过映射使用它的方式。
本章将介绍有关命令缓冲区和内存分配的如下主题:
- 命令缓冲区入门
- 了解命令池和命令缓冲区 API
- 录制命令缓冲区
- 实现命令缓冲区包装类
- 管理 Vulkan 中的内存
命令缓冲区入门
顾名思义,命令缓冲区是一个缓冲区或者一个单元中若干命令的集合。 命令缓冲区记录了应用程序预计执行的各种 Vulkan API 命令。 一旦命令缓冲区经过了烘焙,就可以一遍又一遍地重复使用。 他们按照应用程序指定的顺序记录这些命令。 这些命令用于执行不同类型的作业;这其中包括绑定顶点缓冲区,管线绑定,记录 Render Pass 命令,设置视口和裁剪,指定绘图命令,控制图像和缓冲区内容的复制操作等。
有两种类型的命令缓冲区:主命令缓冲区和辅助命令缓冲区:
- 主命令缓冲区:这些是辅助命令缓冲区的所有者并负责它们的执行;主命令缓冲区被直接提交给队列 。
- 辅助命令缓冲区:它们通过主命令缓冲区执行,不能被直接提交给队列。
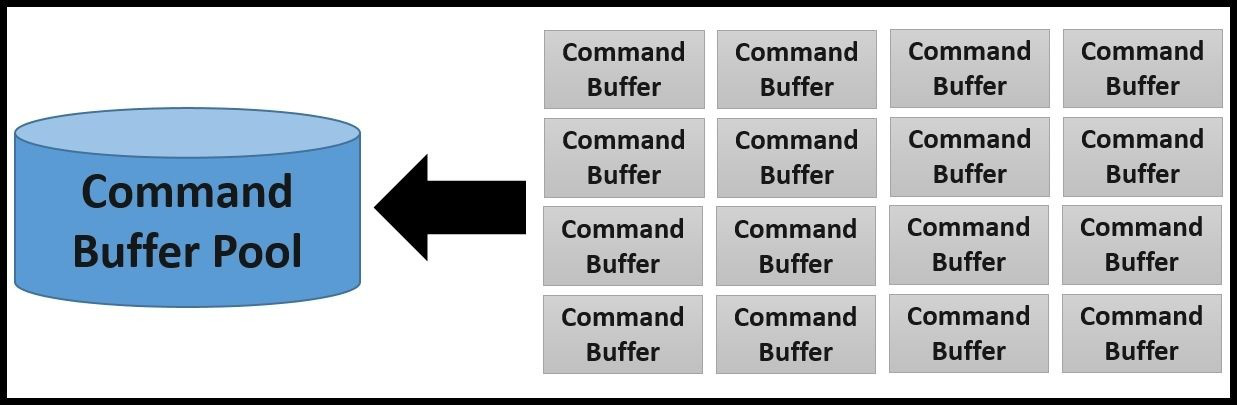
应用程序中的命令缓冲区的数量可以从几百到几千不等。 Vulkan API 旨在提供最大的性能;因此,命令缓冲区是从命令池中进行分配的,以分摊跨多个命令缓冲区创建资源的成本(在多线程环境中使用时(请参阅本章中的“显式同步”部分))。 不能直接创建命令缓冲区, 相反,它是从命令池分配的:

命令缓冲区是持久的;它们会被创建一次并且可以连续重用。 此外,如果一个命令缓冲区不再有用,可以用一个简单的重置命令来更新,并准备好进行另一次记录。 与销毁并为同一个目的创建新的缓冲区相比,这是一种很有效的方法。
显式同步
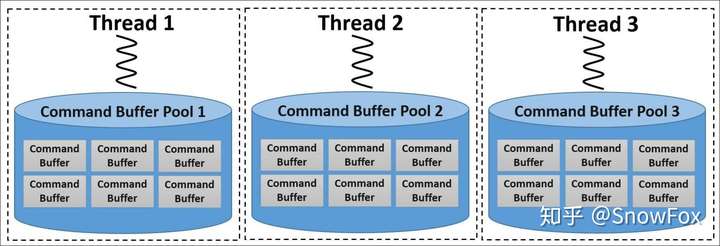
在多线程环境中创建多个命令缓冲区时,建议通过为每个线程引入单独的命令池来分隔多个同步域。 这使命令缓冲区分配的代价更加高效,因为应用程序不需要在不同线程中进行显式同步。
然而,管理在多个线程之间共享的若干命令缓冲区之间的同步,是应用程序的责任。
与此相反,OpenGL 是一个隐式的同步模型。 在 OpenGL 中,很多事情都是自动完成的,这是以大量的资源跟踪、缓存刷新以及依赖链的构造为代价得来的。 所有这些都是在幕后完成的,这确实是 CPU 的开销。 Vulkan 在这方面就相当简单;显式同步保证了没有隐藏的机制,也没有意外的因素。
应用程序可以更好地了解其资源,并因此了解其使用情况和依赖性。 驱动程序不太可能准确地查明依赖关系。 因此,OpenGL 实现最终会带来意想不到的着色器重新编译、缓存刷新等问题。
Vulkan 的显式同步使其不受这些限制,从而使硬件更具生产力。
另一个区别是在 OpenGL 中命令缓冲区的提交:命令缓冲区在幕后 push,并且不受应用程序的控制。 提交命令的应用程序无法保证何时执行这些作业。 这是因为 OpenGL 批量执行命令缓冲区,它等待大量的命令来构建批处理,然后 OpenGL 将它们分配到一起。 另一方面,Vulkan 对命令缓冲区提供了显式的控制,以便允许进行预先的处理 ------ 通过将命令缓冲区提交给所需的队列。
命令缓冲区中命令的类型
命令缓冲区由一个或多个命令组成。 这些命令可以分为三类:
- 动作:该类命令执行诸如绘图、调度、清除、复制、查询、时间戳操作以及开始、结束子通道 subpass 等操作。
- 状态管理:这其中包括描述符集、绑定管线和缓冲区,它用于设置动态的状态,push 常量和 Render Pass / subpass 状态。
- 同步:这些命令用于同步:管线屏障、设置事件、等待事件以及渲染通道 Render Pass/ 子通道 subpass 的依赖关系。
命令缓冲区和队列
命令缓冲区被提交到一个硬件队列,在那里会对它们进行异步处理。 通过对命令缓冲区批处理化操作并对它们执行一次,队列的提交可以变得更加高效。 Vulkan 有一个延迟命令模式,其中命令缓冲区的若干绘制调用的集合以及多个提交操作是分开完成的,并认为它们是两种不同的操作。 从应用程序的角度来看这很有帮助, 这是因为它能够事先了解大部分场景,这可以作为一个契机来给提交操作增加适当的优化,这在 OpenGL 中是很难实现的。
Vulkan 提供了硬件队列的逻辑视图,其中每个逻辑视图紧密地连接到一个硬件队列。 一个 Vulkan 硬件队列可以由多个逻辑队列表示,其中每个队列都是基于该队列的属性创建的。 例如,用于渲染的交换链图像的呈现可能需要命令缓冲区将它们提交给图形队列,这种图形队列也能够呈现内容。
执行顺序
可以把命令缓冲区提交给单个队列或多个队列:
- 单个队列的提交:提交给单个队列的多个命令缓冲区可能会被执行或重叠(overlapped)。 在单个队列的提交中,命令缓冲区必须遵守操作执行的顺序(按照命令的顺序和 API 的顺序规范)。 本书仅涵盖了用于 vkQueueSubmit 的提交命令;其中不包括稀疏内存绑定命令缓冲区(通过 vkQueueBindSparse)。
- 多个队列的提交:提交给多个队列的命令缓冲区可以按任意顺序执行,除非通过同步机制(比如信号量和栏栅)显式地应用了排序约束。
理解命令池和缓冲区 API
本节将介绍可用于管理命令池和命令缓冲区的不同 API。 在这里,我们将了解创建命令缓冲池的过程,这个池子会用于命令缓冲区的分配。 我们还会看到重置和销毁 API 的过程。
本章的下一部分将根据现有的包装类在其中实现这些 API。 在本书的其余章节中,包装器实现会非常有用,因为我们会使用大量的命令缓冲区。
提示
作为后续章节的先决条件,在 Vulkan 章节中“实现命令池和命令缓冲区”,“记录命令缓冲区”以及“管理内存” 的内容都是非常重要的。
创建命令池
使用 vkCreateCommandPool()API 创建命令池。 它接受一个 VkCommandPoolCreateInfo 控制结构,该结构会指导从这个缓冲池中要分配的命令缓冲区的特性相关的实现信息,同时 它还指示这个命令缓冲区应该属于哪个队列族。 预先提供的这个信息对分配兼容的命令池非常有用;这些池可用来优化(用于典型队列提交的)命令缓冲区的分配过程。下面是其语法:
typedef struct VkCommandPoolCreateInfo {
VkStructureType sType;
const void* next;
VkCommandPoolCreateFlags flags;
uint32_t queueFamilyIndex;
} VkCommandPoolCreateInfo;下表描述了 VkCommandPoolCreateInfo 结构的各个字段:
type:这是这个控制结构的类型信息。 必须将其指定为 VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO。
next : 这可能是一个指向特定于扩展结构的有效指针或 NULL。
flag | 这表示一个按位枚举标志,用于指示命令池的使用情况以及从中分配的命令缓冲区的行为。 此枚举标志的类型为 VkCommandPoolFlag,并且可以将 VK_COMMAND_POOL_CREATE_TRANSIENT_BIT 和 VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT 作为可能的输入值。 有关这些标志值的更多信息,请参阅以下提示。
queueFamilyIndex :这表示要把命令缓冲区提交到其中的队列族。
提示
VK_COMMAND_POOL_CREATE_TRANSIENT_BIT 枚举标志表示从该池分配的命令缓冲区会被经常更改并且寿命较短。 这意味着缓冲区会在相对较短的时间内被重置或释放。 该标志告知了实现有关命令缓冲区的性质,并且这可以用来控制池内的内存分配行为。
当设置 VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT 标志时,它表示从池中分配的命令缓冲区可以通过两种方式分别重置:显式调用 vkResetCommandBuffer 或通过调用 vkBeginCommandBuffer 隐式重置。
如果未设置此标志,则不能对从池中分配的可执行命令缓冲区调用这两个 API。 这表明只能通过调用 vkResetCommandPool 对它们进行批量重置。
Vulkan 中的命令池由 VkCommandPool 对象表示, 它是使用 vkCreateCommandPool()API 创建的。 以下是该 API 的语法以及描述:
VkResult vkCreateCommandPool(
VkDevice device,
const VkCommandPoolCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkCommandPool* pCommandPool
);
下表介绍了此 API 的各个参数:
device :这是要创建命令池的、设备的句柄。
pCreateInfo :该参数引用 VkCommandPoolCreateInfo 对象,该对象指示了命令池中命令缓冲区的性质。
pAllocator:这个用来控制主机的内存分配。
pCommandPool :这代表 API 返回的 VkCommandPool 对象。
注意
有关如何使用 VkAllocationCallbacks * allocator 控制主机内存分配的更多信息,请参阅本章最后一节中的“主机内存”主题,即“管理 Vulkan 中的内存”。
重置命令池
命令池(VkCommandPool)可以使用 vkResetCommandPool()API 重置。 这是该 API 的语法:
VkResult vkResetCommandPool (
VkDevice device,
VkCommandPool commandPool,
VkCommandPoolResetFlags flags
);以下是此 API 的参数:
device :这是拥有命令池的设备的句柄。
commandPool :这指的是需要重置的 VkCommandPool 句柄。
flags :该标志控制重置池的行为。
销毁命令池
命令池可以使用 vkDestroyCommandPool()API 销毁。 这是它的语法:
VkResult vkDestroyCommandPool(
VkDevice device,
VkCommandPool commandPool,
const VkAllocationCallbacks* allocator
);以下是此 API 的参数:
device :这是要销毁命令池的设备的句柄。
commandPool :这是指需要销毁的 VkCommandPool 句柄。
allocator :这个参数控制主机内存的分配。 有关更多信息,请参阅第 5 章中的“主机内存”部分,“Vulkan 中的命令缓冲区以及内存管理”。
命令缓冲区的分配
命令缓冲区是使用 vkAllocateCommandBuffers()API 从命令缓冲池(VkCommandPool)分配的。 该 API 需要 VkCommandBufferAllocateInfo 控制结构对象,该结构对象指定了在分配过程中有用的各种参数。 成功执行 API 后,它会返回 VkCommandBuffer 对象。 以下是此 API 的语法:
VkResult vkAllocateCommandBuffers(
VkDevice device,
const VkCommandBufferAllocateInfo* pAllocateInfo,
VkCommandBuffer* pCommandBuffers
);我们来看看 API 的各个参数:
device :这是拥有命令池的逻辑设备对象的句柄。 pAllocateInfo | 这是一个指针,指向描述分配参数的 VkCommandBufferAllocateInfo 结构;请参阅下表了解更多信息。 pCommandBuffers :该参数引用了分配的、命令缓冲区对象的数组。
VkCommandBufferAllocateInfo 结构具有以下字段:
sType : 这个字段指的是类型信息,告诉 Vulkan 它是一个 VkCommandBufferAllocate 结构,它必须是 VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO 的类型:
pNext :这个字段为 NULL 或引用一个扩展特定的结构。
commandPool :这是命令池的句柄,需要从该命令缓冲池中为请求的命令缓冲区分配内存。
level :这是 VkCommandBufferLevel 类型的按位枚举标志,指示命令缓冲区是处于主级还是次级。 以下是 VkCommandBufferLevel 的语法:
typedef enum VkCommandBufferLevel {
VK_COMMAND_BUFFER_LEVEL_PRIMARY=0,
VK_COMMAND_BUFFER_LEVEL_SECONDARY=1,
} VkCommandBufferLevel;commandBufferCount: 这是指需要分配的命令缓冲区的数量。
重置命令缓冲区
分配的命令缓冲区可以使用 vkResetCommandBuffer()API 重置。 该 API 接受需要重置的 VkCommandBuffer 对象作为第一个参数。 第二个参数是位掩码 VkCommandBufferResetFlag,它控制重置操作的行为。 该结构具有一个枚举值,即 VK_COMMAND_BUFFER_RESET_RELEASE_RESOURCES_BIT。 当这个值被设置时,这意味着命令缓冲区保存的内存会被返回到父级命令池。
以下是 API 的语法:
VkResult vkResetCommandBuffer( VkCommandBuffer commandBuffer, VkCommandBufferResetFlags flags);释放命令缓冲区
使用 vkFreeCommandBuffer()API 可以释放一个或多个命令缓冲区。 以下是此 API 的语法:
void vkFreeCommandBuffers(
VkDevice device,
VkCommandPool commandPool,
uint32_t commandBufferCount,
const VkCommandBuffer* pCommandBuffers);以下是 vkFreeCommandBuffers()API 的参数及其各自的描述:
device : 这引用的是保存命令池的逻辑设备。
commandPool : 这引用的是必须从中进行内存释放的、关联的命令池。
commandBufferCount :这是指需要释放的命令缓冲区的数量。
pCommandBuffers :这是需要释放的命令缓冲区句柄的一个数组。
记录命令缓冲区
使用 vkBeginCommandBuffer()和 vkEndCommandBuffer()API 记录命令缓冲区。 这些 API 定义了一个范围,该范围中所有指定的 Vulkan 命令都会被记录起来。 以下示例显示了这两个 API 之间 Render Pass 实例创建的记录过程,这两个 API 用作开始和结束范围。 有关创建渲染通道的更多信息,请参阅第 7 章“缓冲区资源,渲染通道,帧缓冲区以及使用 SPIR-V 的着色器”中的“了解渲染通道”部分。

记录的开始是使用 vkBeginCommandBuffer()API 执行的。 该 API 定义了开始范围,在此范围之后,指定的任何调用都被视为需要记录的内容,直到到达结束范围(vkEndCommandBuffer())。
以下是此 API 的语法,然后是必要参数的说明:
VkResult vkBeginCommandBuffer(
VkCommandBuffer commandBuffer,
const VkCommandBufferBeginInfo* pBeginInfo);这个 API 接受两个参数。 第一个是命令缓冲区的句柄,其中是要记录的所有调用。 第二个参数是一个 VkCommandBufferBeginInfo 结构对象,它定义了附加信息,告诉你如何开始命令缓冲区的记录过程。
以下是 VkCommandBufferBeginInfo 结构的 API 语法:
typedef struct VkCommandBufferBeginInfo {
VkStructureType sType;
const void* pNext;
VkCommandBufferUsageFlags flags;
const VkCommandBufferInheritanceInfo* pInheritanceInfo;
} VkCommandBufferBeginInfo;这个结构中接受的字段描述如下:
sType : 这是这个控制结构的类型信息。 必须将其指定为 VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO。
pNext : 该字段可以是一个指向特定于扩展结构的有效指针或 NULL。
flags : 这是 VkC :如果该字段不为 NULL,则在命令缓冲区是辅助命令缓冲区时使用该字段。 它包含 VkCommandBufferInheritanceInfo 结构。
pInheritanceInfo | 如果该字段不为 NULL,则在命令缓冲区是辅助命令缓冲区时使用该字段。 它包含 VkCommandBufferInheritanceInfo 结构。
命令缓冲区记录是使用 vkEndCommandBuffer()API 执行的。 它接受一个参数,该参数指定了要对其进行停止记录操作的命令缓冲区对象。 这是它的语法:
VkResult vkEndCommandBuffer(VkCommandBuffer commandBuffer);队列提交
一旦记录了命令缓冲区(VkCommandBuffer),就可以将其提交到队列中。 vkQueueSubmit()API 有助于把作业提交到一个适当的队列中。 让我们来看看这个函数的语法:
VkResult vkQueueSubmit(
VkQueue queue,
uint32_t submitCount,
const VkSubmitInfo* pSubmitInfo,
VkFence fence);接受的参数如下所示:
queue :这是要提交到命令缓冲区的队列句柄。
submitCount :这指的是 submitInfo 对象的数量。
submitInfo :这指的是 VkSubmitInfo 指针。 它包含有关每个工作提交的重要信息,工作提交的数量(由 submitCount 表示)。 后面会谈到它的 API 规范。
fence : 这被用作一种信号机制,用来指示命令缓冲区执行的完成情况。 如果 fence 为非 null 并且 submitCount 为非 0,那么当执行了 submitInfo 的 VkSubmitInfo :: pCommandBuffers 成员中指定的所有命令缓冲区时,fence 会获得信号通知(fence gets signaled)。 如果 fence 不为 null,但 submitCount 为 0,有信号的 fence (the signaled fence)则表明以前提交到队列的所有工作都已完成。
我们来看看 VkSubmitInfo。 这个结构将多个信息嵌入到自身当中。 提交过程使用此信息来处理单个 VkSubmitInfo 对象,其中包含了一个或者多个命令缓冲区。 以下是它的语法:
typedef struct VkSubmitInfo { VkStructureType type;
const void* pNext;
uint32_t waitSemaphoreCount;
const VkSemaphore* pWaitSemaphores;
const VkPipelineStageFlags* pWaitDstStageMask; uint32_t commandBufferCount;
const VkCommandBuffer* pCommandBuffers; uint32_t signalSemaphoreCount;
const VkSemaphore* pSignalSemaphores;
} VkSubmitInfo;接受的字段描述如下所示:
sType :这是 VkSumbitInfo 结构的类型,它必须是 VK_STRUCTURE_TYPE_SUBMIT_INFO。
pNext :这是一个指向特定于扩展的结构的指针或 NULL。
waitSemaphoreCount :指的是在执行命令缓冲区之前被迫等待的信号量数量。
pWaitSemaphores :这是一个指向在命令缓冲区被批处理执行之前被迫等待的信号量的数组的指针。
pWaitDstStageMask :这是一个指向管线阶段的数组的指针,在这些阶段中,每个相应的信号量的等待情况将会发生。
commandBufferCount:这是指批处理中要执行的命令缓冲区的数量。
pCommandBuffers :这是一个指向批处理中要执行的命令缓冲区数组的指针。
signalSemaphoreCount :这指的是一旦 commandBuffers 中指定的命令完成执行,将被发送信号的信号量的数量。
pSignalSemaphores :这是一个指向信号量数组的指针,当给定的批处理的命令缓冲区执行时,这些信号量将被发送信号。
队列等待
一旦提交到队列中,应用程序必须等待队列完成提交的作业并准备好下一个批处理操作。 等待队列的过程可以使用 vkQueueWaitIdle()API 完成。 该 API 会阻塞,直到队列中的所有命令缓冲区和稀疏绑定操作完成。 此 API 接受一个参数,该参数指定要等待完成操作的队列的句柄。 以下是此 API 的语法:
VkResult vkQueueWaitIdle(VkQueue queue);实现命令缓冲区的包装类
本节实现名为 CommandBufferMgr 的命令缓冲区的包装类。 这个类包含静态函数,可以像工具函数一样直接使用而不需要类对象。 该类在一个名为 wrapper.h / .cpp 的新文件中实现;文件中会包含多个实用方法。
该类中大部分实现的函数都提供了默认实现。 这意味着每个函数都为用户提供了从函数调用外部更改控制结构参数的灵活性,并将它们作为参数传递。 函数参数有固有的默认值,所以如果你没有指定任何自定义的参数,函数会为你完成所有默认的工作。
以下是 CommandBufferMgr 类的头文件实现,声明了四个静态函数,负责分配内存、记录命令缓冲区以及将命令缓冲区提交给命令队列:
/**************** Wrapper.h ******************/
class CommandBufferMgr{ public:
// Allocate memory for command buffers from the command pool
static void allocCommandBuffer(const VkDevice* device, const VkCommandPool cmdPool, VkCommandBuffer* cmdBuf, const VkCommandBufferAllocateInfo* commandBufferInfo);
// Start the command buffer recording
static void beginCommandBuffer(VkCommandBuffer cmdBuf, VkCommandBufferBeginInfo* inCmdBufInfo = NULL);
// End the command buffer recording
static void endCommandBuffer(VkCommandBuffer cmdBuf);
// Submit the command buffer for execution
static void submitCommandBuffer(const VkQueue& queue, const VkCommandBuffer* cmdBufList, const VkSubmitInfo* submit- Info = NULL, const VkFence& fence = VK_NULL_HANDLE);
};实现命令缓冲区的分配过程
allocCommandBuffer()函数从指定的命令池(cmdPool)分配命令缓冲区(cmdBuf)。 分配行为可以使用 VkCommandBufferAllocateInfo 指针参数进行控制。 当此函数的最后一个参数具有其默认参数值(NULL)时,则 VkCommandBufferAllocateInfo 在内部进行实现,如以下代码所示,并用于命令缓冲区的分配:
void CommandBufferMgr::allocCommandBuffer(const VkDevice* device, const VkCommandPool cmdPool, VkCommandBuffer* cmdBuf, const VkCommandBufferAllocateInfo* commandBufferInfo){
VkResult result;
这篇关于第 5 章. Vulkan 中的命令缓冲区以及内存管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



