本文主要是介绍redis数据类型之Hash,Bitmaps,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
华子目录
- `Hash`
- 结构图
- 相关命令
- `hexists key field`
- `hmset key field1 value1 [field2 value2...]`
- `hscan key cursor [MATCH pattern] [COUNT count]`
- `Bitmaps`位图
- 相关命令
- `setbit`
- 1. **命令描述**
- 2. **语法**
- 3. **参数限制**
- 4. **内存分配与性能**
- 5. **应用实例**
- 6. **其他相关命令**
- 7. **总结**
- 例子
- `getbit`
- 1. 命令描述
- 2. 语法
- 3. 返回值说明
- 4. 参数限制
- 5. 内存分配与性能
- 6. 应用实例
- 7. 注意事项
- 8. 关联命令
- 9. 总结
- 示例
- `bitcount`
- 1. 命令描述
- 2. 语法
- 3. 返回值说明
- 4. 参数限制
- 5. 内存分配与性能
- 6. 应用实例
- 7. 注意事项
- 8. 关联命令
- 9. 总结
- 示例
- `bitop`
- 1. 语法
- 2. 参数说明
- 3. 返回值
- 4. 注意事项
- 5. 示例
- 6. 性能考虑
- 7. 总结
Hash
Redis hash是一个string 类型的field 和 value的映射表,hash特别适合用于存储对象。Redis中每个hash可以存储2^32^ - 1 键值对(40多亿)。Hash类型一般用于存储用户信息、用户主页访问量、组合查询等。
结构图
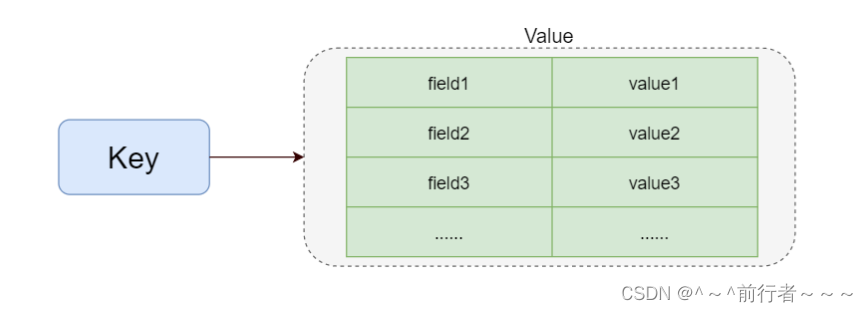
相关命令
| 命令 | 说明 |
|---|---|
hset key field1 value1 [field2 value2...] | 将哈希表 key 中的字段 field 的值设为 value |
hget key field | 获取存储在哈希表中指定字段的值 |
hgetall key | 获取在哈希表中指定 key 的所有字段和值 |
hexists key field | 查看哈希表 key 中,指定的字段是否存在,存在返回1,不存在返回0 |
hsetnx key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
hkeys key | 获取所有哈希表中的字段 |
hvals key | 获取哈希表中所有值 |
hlen key | 获取哈希表中字段的数量 |
hmget key field1 [field2...] | 获取所有给定字段的值 |
hmset key field1 value1 [field2 value2...] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
hincrby key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
hincrbyfloat key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment |
hdel key field1 [field2...] | 删除一个或多个哈希表字段 |
hscan key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
hexists key field
HEXISTS命令是Redis数据库中用于检查哈希表(Hash)中指定字段(field)是否存在的命令。以下是关于HEXISTS命令的详细解释:
-
命令语法:
HEXISTS key field- 其中,
key是哈希表的键名,field是哈希表中的字段名。
-
返回值:
- 如果哈希表含有给定的字段,则返回整数
1。 - 如果哈希表不含有给定的字段,或者键不存在,则返回整数
0。
- 如果哈希表含有给定的字段,则返回整数
hmset key field1 value1 [field2 value2...]
HMSET是Redis中的一个命令,用于在哈希表中设置多个字段和对应的值。这个命令在Redis 2.6.0版本及以后的版本中可用,但在Redis 4.0.0版本之后,它已经被HSET命令的多字段/多值语法所取代。尽管HMSET仍然存在于许多 Redis 环境中,但推荐使用HSET的新语法。
以下是 HMSET 的用法:
HMSET key field1 value1 field2 value2 ... fieldN valueN
这里是一个例子:
HMSET user:1000 username alice password secret123 email alice@example.com
在这个例子中,我们在哈希表 user:1000 中设置了三个字段:username、password 和 email,以及它们对应的值。
然而,从 Redis 4.0.0 开始,你可以使用 HSET 命令的扩展语法来达到相同的效果:
HSET key field1 value1 field2 value2 ... fieldN valueN
所以,上面的 HMSET 例子可以用 HSET 写成:
HSET user:1000 username alice password secret123 email alice@example.com
在大多数情况下,你应该使用 HSET 的新语法,因为它更加通用和灵活。但是,如果你正在维护一个使用 HMSET 的旧系统,那么了解 HMSET 的用法仍然是有用的。
hscan key cursor [MATCH pattern] [COUNT count]
HSCAN是Redis中用于迭代哈希表(Hash)键的命令。当哈希表非常大,无法一次性加载到客户端时,你可以使用HSCAN命令来逐步迭代哈希表中的数据。
以下是 HSCAN 命令的基本语法和参数说明:
HSCAN key cursor [MATCH pattern] [COUNT count]
参数说明:
key:哈希表的键名。cursor:游标,初始值通常为0,表示开始迭代。在后续的迭代中,你将使用上一次迭代返回的游标作为参数。MATCH pattern(可选):一个可选的模式字符串,用于过滤返回的字段。只有匹配该模式的字段才会被返回。COUNT count(可选):一个可选的数字,表示每次迭代返回的字段的最大数量。这个值只是一个提示,Redis 可能会返回更多或更少的字段。
HSCAN 命令会返回一个包含两个元素的数组:
- 新的游标值:用于下一次迭代。
- 一个包含字段-值对的数组。
当所有字段都被迭代后,新的游标值将是 0。
以下是一个使用 HSCAN 命令的示例:
# 第一次迭代,游标为 0
127.0.0.1:6379> HSCAN myhash 0
1) "0" # 新的游标值
2) 1) "field1"2) "value1"3) "field2"4) "value2"# 假设我们只对以 "field" 开头的字段感兴趣,并希望每次迭代返回 1 个字段
127.0.0.1:6379> HSCAN myhash 0 MATCH field* COUNT 1
1) "0" # 注意:新的游标值可能是 0,也可能是其他值,取决于哈希表的结构和 COUNT 参数
2) 1) "field1"2) "value1"# 使用新的游标值继续迭代
127.0.0.1:6379> HSCAN myhash <new_cursor_value> MATCH field* COUNT 1
...
请注意,HSCAN 命令是非阻塞的,并且可以在迭代过程中修改哈希表。但是,在迭代过程中添加的新字段可能不会被立即返回,因为它们可能出现在当前游标的“后面”。同样,在迭代过程中删除的字段也可能仍然被返回,因为它们是在游标指向它们之前存在的。
Bitmaps位图
-
现代计算机用
二进制(位)作为信息的基础单位,1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、01100010和01100011,如下图: -

-
合理地使用操作位能够有效地提高内存使用率和开发效率。
-
Redis 6中提供了Bitmaps这个“数据类型”可以实现对位的操作:Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
相关命令
setbit
SETBIT是Redis数据库中的一个命令,用于设置指定key所储存的字符串值中,指定偏移量上的位(bit)。以下是对SETBIT命令的详细解释:
1. 命令描述
- 功能:对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
- 节省空间:由于 8 个 bit 可以组成一个 Byte,使用 bitmap 可以极大地节省存储空间。
2. 语法
SETBIT key offset value
- key:要操作的
字符串键。 - offset:要设置的位的位置。
位的位置从 0 开始计数。 - value:要设置的值,
只能是 0 或 1。
3. 参数限制
- offset 的限制:
offset参数必须大于或等于 0,小于 2^32(bit 映射被限制在 512 MB 之内)。 - Redis 字符串大小限制:Redis 字符串的大小被限制在 512 兆(megabytes)以内,所以用户能够使用的最大偏移量为 2^29-1(536870911)。如果需要更大的空间,请使用多个 key。
4. 内存分配与性能
- 当生成一个很长的字符串时,Redis 需要分配内存空间,该操作有时候可能会造成服务器阻塞。例如,在 2010 年出产的 Macbook Pro 上,设置偏移量为 536870911(512MB 内存分配)将耗费约 300 毫秒。
5. 应用实例
- 如果键
mykey的初始值是字符串 “foobar”,使用SETBIT mykey 2 1命令后,键mykey的值将变为 “oba1r”(因为字符串的索引是从 0 开始的,所以第 2 个位置对应的是字符 ‘o’ 的第二个 bit)。
6. 其他相关命令
- GETBIT:用于获取指定 key 的字符串值中,指定偏移量上的位的值(0 或 1)。
7. 总结
SETBIT 命令提供了一种在 Redis 中进行精确位操作的方式,可以在节省存储空间的同时,进行高效的位设置和清除操作。这在一些需要频繁进行位操作的场景中,如实时统计、状态标记等,具有非常重要的应用价值。
例子
- 例如,把每个独立用户是否访问过网站存放在
Bitmaps中, 将访问的用户记做1,没有访问的用户记做0,用户的id作为偏移量。 - 设置键的第
offset个位的值(从0算起) , 假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图: 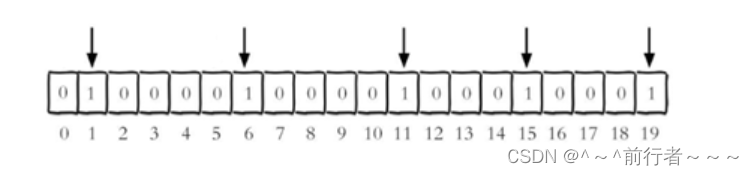
- 下面示例是代表 2022-07-18 这天的独立访问用户的Bitmaps:
127.0.0.1:6379> setbit unique:users:20220718 1 1127.0.0.1:6379> setbit unique:users:20220718 6 1127.0.0.1:6379> setbit unique:users:20220718 11 1127.0.0.1:6379> setbit unique:users:20220718 15 1127.0.0.1:6379> setbit unique:users:20220718 19 1
注意:
- 很多应用的用户
id以一个指定数字(例如10000)开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。 - 在第一次初始化
Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
getbit
GETBIT是Redis数据库中的一个命令,用于获取指定key所储存的字符串值中,指定偏移量上的位(bit)的值。以下是关于GETBIT命令的详细解释:
1. 命令描述
- 功能:对
key所储存的字符串值,获取指定偏移量上的位(bit)的值。 - 返回值:
返回指定偏移量上的位的值,该值只能是 0 或 1。
2. 语法
GETBIT key offset
- key:要操作的字符串键。
- offset:要获取的位的位置。位的位置从
0开始计数。
3. 返回值说明
- 如果
key不存在,或者offset超出了字符串值的长度,GETBIT命令将返回 0。 - 否则,返回指定偏移量上的位的值,该值
只能是 0 或 1。
4. 参数限制
- offset 的限制:
offset参数必须大于或等于0,小于2^32(因为 Redis 的字符串最大长度为 512 MB,所以位映射被限制在这个范围内)。
5. 内存分配与性能
- 由于
GETBIT只是简单地读取字符串中指定位置的位,所以其性能通常非常高,不需要额外的内存分配。
6. 应用实例
- 假设有一个 key 名为
flags,其存储的字符串值为二进制表示 “10101”(对应十进制中的 21)。执行GETBIT flags 1将返回 0,因为从右往左数(即从低位到高位),第二个位是 0。
7. 注意事项
- 当使用
GETBIT时,需要注意 offset 是否在有效范围内,以避免获取到错误的值。 - 如果想要设置或修改指定偏移量上的位的值,应该使用
SETBIT命令。
8. 关联命令
- SETBIT:用于设置指定 key 所储存的字符串值中,指定偏移量上的位的值。
9. 总结
GETBIT 是一个高效且灵活的 Redis 命令,它允许开发者在不牺牲太多存储空间的前提下,实现精细的位级操作。这种能力在需要记录大量二进制状态信息或进行实时统计等场景中特别有用。
示例
获取键的第offset位的值(从0开始算)。例如获取id=6的用户是否在2022-07-18这天访问过, 返回0说明没有访问过:
127.0.0.1:6379> getbit unique:users:20220718 6
127.0.0.1:6379> getbit unique:users:20220718 7
bitcount
BITCOUNT是Redis数据库中的一个命令,用于计算给定字符串中设置为1的位的数量。这个命令在处理位图(bitmap)或二进制数据时特别有用,因为它提供了一种快速计算二进制数据中特定位模式数量的方法。
1. 命令描述
- 功能:计算指定 key 所储存的字符串值中,设置为 1 的位的数量。
- 返回值:返回字符串中设置为 1 的位的数量。
2. 语法
BITCOUNT key [start] [end]
- key:要操作的字符串键。
- start(可选):计算的起始偏移量。
- end(可选):计算的结束偏移量。
如果指定了 start 和 end 参数,BITCOUNT 命令将只计算从 start 到 end(包括 end)之间(包括边界)的位。如果省略了 start 和 end,那么将计算整个字符串。
3. 返回值说明
- 返回字符串中设置为 1 的位的数量。
4. 参数限制
- start 和 end 的限制:
start和end必须是非负整数,且end必须大于或等于start。它们指定了计算位的范围。
5. 内存分配与性能
BITCOUNT命令的性能通常取决于字符串的长度和计算机硬件的性能。对于较长的字符串,该命令可能需要一些时间来计算。但是,由于 Redis 的内部优化,这个命令通常比使用其他编程语言或工具来手动计算要快得多。
6. 应用实例
- 假设有一个 key 名为
user_visits,其存储的字符串值为二进制表示 “10101”(对应十进制中的 21)。执行BITCOUNT user_visits将返回 3,因为字符串中有 3 个位被设置为 1。 - 如果想要计算从第 2 个位到第 4 个位之间(包括边界)设置为 1 的位的数量,可以执行
BITCOUNT user_visits 1 3。在这个例子中,由于只有第 2 个位被设置为 1,所以将返回 1。
7. 注意事项
- 当使用
BITCOUNT时,需要注意start和end是否在有效范围内,以避免计算到错误的位。 - 如果 key 不存在,
BITCOUNT将返回 0。
8. 关联命令
- SETBIT:用于设置指定 key 所储存的字符串值中,指定偏移量上的位的值。
- GETBIT:用于获取指定 key 所储存的字符串值中,指定偏移量上的位的值。
9. 总结
BITCOUNT 是一个强大的 Redis 命令,它允许开发者快速地计算二进制数据中特定位模式的数量。这种能力在多种场景中都非常有用,例如统计用户访问频率、记录在线用户状态等。
示例
用于统计字符串从start字节到end字节比特值为1的数量。例如,统计id在第1个字节到第3个字节之间的独立访问用户数, 对应的用户id是11, 15, 19。
127.0.0.1:6379> bitcount unique:users:20220718 1 3
bitop
BITOP是Redis中用于执行位操作的命令,它允许用户对一个或多个键(key)的值进行位运算,并将结果存储在另一个键中。BITOP命令在处理位图(Bitmap)数据结构时特别有用,它提供了一种高效的方式来执行常见的位运算操作,如AND(与)、OR(或)、NOT(非)和XOR(异或)等。
以下是BITOP命令的详细介绍:
1. 语法
BITOP operation destkey key [key ...]
- operation:要执行的位运算操作,可以是
AND、OR、NOT或XOR。 - destkey:存储运算结果的
键名。 - key:要进行位运算的键名,可以是一个或多个。
2. 参数说明
- operation:指定要执行的位运算类型。
AND:对所有key的值执行位与运算。OR:对所有key的值执行位或运算。NOT:仅对一个key的值执行位非运算(注意,NOT操作时key只能有一个)。XOR:对所有key的值执行位异或运算。
- destkey:用于存储运算结果的键名。
- key:要进行位运算的键名列表。
对于NOT操作,只需要一个key;对于其他操作,可以指定一个或多个key。
3. 返回值
BITOP命令返回保存到destkey的字符串的长度,这个长度与输入key中最长的字符串长度相等。
4. 注意事项
- 当处理不同长度的字符串时,较短的字符串所缺少的部分会被视为0。
- 空的key也被视为包含0的字符串序列。
- NOT操作只能对一个key执行。
5. 示例
假设我们有以下三个key及其对应的值(以二进制表示):
key1: 1010key2: 1100key3: 0011
执行以下BITOP命令:
BITOP AND result key1 key2:将key1和key2进行位与运算,结果存储在result中,result的值为1000(即十进制的8)。BITOP OR result key1 key2 key3:将key1、key2和key3进行位或运算,结果存储在result中,result的值为1111(即十进制的15)。BITOP NOT result key1:对key1进行位非运算,结果存储在result中,result的值为0101(即十进制的5)。BITOP XOR result key1 key2:将key1和key2进行位异或运算,结果存储在result中,result的值为0110(即十进制的6)。
6. 性能考虑
BITOP命令的时间复杂度是O(N),其中N是位图包含的二进制位数量。在处理长字符串时,该命令可能需要一些时间来完成计算。因此,在处理实时指标和统计时,涉及大输入时需要注意效率问题。可以使用bit-wise操作来避免阻塞主实例。
7. 总结
BITOP是Redis中用于执行位操作的强大命令,它允许用户高效地处理位图数据结构,并执行常见的位运算操作。通过合理使用BITOP命令,可以优化数据存储和查询性能,实现更高效的数据处理和分析。
这篇关于redis数据类型之Hash,Bitmaps的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






