本文主要是介绍SQL问题的常用信息收集命令及解决思路 |OceanBase应用实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
面对SQL问题,大家的常用的分析思路是:
一、问题是否源于SQL本身?是的话需进行SQL调优。
二、SQL语句本身无误,但执行效果并未达到我们的预期效果。
- 检查当前的服务器负载状况,例如CPU利用率、内存占用、IO读写等关键指标。
- 确认是否存在数据库锁冲突问题
- 统计信息是否准确
- 考虑其他可能的场景因素
常用的信息收集
一、获取 trace_id 的方式
方法一:如果SQL可以执行成功,执行完第一步的sql后立即执行获取
select last_trace_id();方法二:如果SQL执行失败,可以通过设置参数,失败后会返回信息(trace_id、执行节点等)
alter system set enable_rich_error_msg=true; // 需要在sys租户下执行方法三:直接通过 SQL 过滤 sql_audit
select * from oceanbase.GV$OB_SQL_AUDIT where query_sql like 'xxx%' order by REQUEST_TIME desc limit 5;二、执行信息收集
1、OCP 平台业务租户监控截图,包括性能和主机监控
2、获取执行计划
explain extended sql3、执行原始SQL,然后获取trace_id
select last_trace_id(); 获取trace id4、获取 sql_audit
select * from oceanbase.GV$OB_SQL_AUDIT where TRACE_ID='xxx' order by REQUEST_TIME desc limit 5;5、获取对应的observer log
通过 sql_audit 信息,到执行的节点下执行
grep 'xxx' observer.log*6、获取 sql_monitor(local计划默认不会生成sql_monitor)
1、sql 执行添加monitor hint:
select /*+ monitor */ * from xxx; delete /*+ monitor */ * from xxx;2、获取trace id
select last_trace_id();3、获取 sql_monitor,这里要替换traceid
select plan_line_id, plan_operation, sum(output_rows), sum(STARTS) rescan, min(first_refresh_time) open_time, max(last_refresh_time) close_time, max(last_refresh_time) - min(first_refresh_time) open_close_cost, min(first_change_time) first_row_time, max(last_change_time) last_row_eof_time, max(last_change_time) - min(first_change_time) rows_cost, count(1) from oceanbase.GV$SQL_PLAN_MONITOR where trace_id = 'xxxx' group by plan_line_id, plan_operation order by plan_line_id;7、查询表的统计信息
select * from OCEANBASE.DBA_TAB_STATISTICS where table_name='xxx' \G8、收集 explain trace 日志
set ob_log_level='TRACE';explain extend 原始sql;select last_trace_id();然后用 trace id 捞一下日志
三、收集常见问题
如果日志没有查到记录,可能是因为日志级别设置的太高
show parameters like '%syslog_level%';set ob_log_level='TRACE';也有可能日志限流以及刷新过快
alter system set syslog_io_bandwidth_limit='1G';alter system set max_syslog_file_count=15;常见的问题解决思路
可以先收集下执行计划,然后再执行转储合并以及收集统计信息后重试,来排除这方面导致慢的可能。
收集统计信息
CALL dbms_stats.gather_table_stats('库名', '表名');转储合并
转储:
alter system minor freeze;查询转储信息,如果没有记录说明转储完成
SELECT * FROM oceanbase.GV$OB_TABLET_COMPACTION_PROGRESS WHERE TYPE='MINI_MERGE'\G合并:
ALTER SYSTEM MAJOR FREEZE;查询合并状态,可以多查询几次,status 变成 idle 就可以了
SELECT * FROM oceanbase.CDB_OB_MAJOR_COMPACTION\Gsql_audit 判断
sql_audit 如果花费的时间都是 execute_time,就说明没有排队、堵塞等问题,这个时候就要看计划是否合理、sql是否可以优化。
根据 sql_monitor 中慢的部分再分析执行计划
举个🌰:
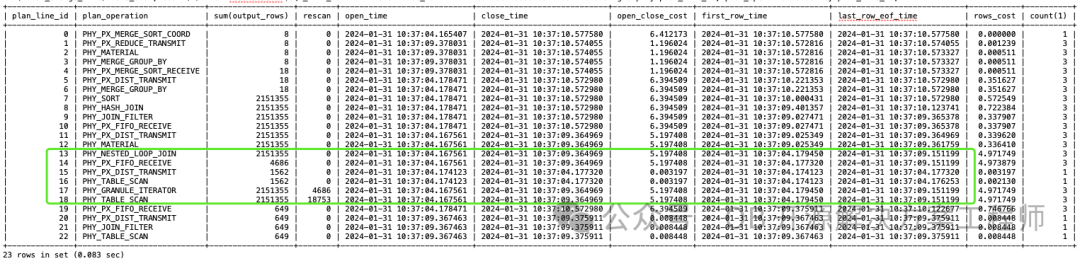
估行不准
比如慢的算子部分 EST.ROWS 跟直接count 差别很大,尤其是用了 NLJ 的场景。
数据倾斜
带有业务特征的字段十有八九都会比较容易倾斜。比如:时间字段高度可疑,特别是这种2099年。
怀疑统计信息不准确可以尝试动态采样
动态采样为了使优化器得到足够多的统计信息,会在计划生成阶段针对数据库对象进行提前采样,通过采样的方式进行行数估计,从而用于代价模型中,生成更好的计划。
语句添加 /*+dynamic_sampling(1)*/ 这个hint执行采集列的直方图
如果某些列的执行计划感觉有影响,可以确认列的统计信息是否准确
确认列的直方图收集情况,需要确认 HISTOGRAM 字段不为空。
select * from OCEANBASE.DBA_TAB_COL_STATISTICS where TABLE_NAME ='dim_scd_organization'\G收集所有列的统计信息
call dbms_stats.gather_table_stats('库名', '表名', degree=>4, method_opt=>'for all columns size 256');收集完成后再确认 OCEANBASE.DBA_TAB_COL_STATISTICS 的 HISTOGRAM 字段。
收集完可以再确认下sql的执行情况以及执行计划。
如果怀疑表关联顺序或者表关联算法有问题,可以通过 Hint 来指定。
如下为碰到的问题:
如果怀疑 NLJ(next-loop join) 慢,可以添加 Hint NO_USE_NL 关闭。

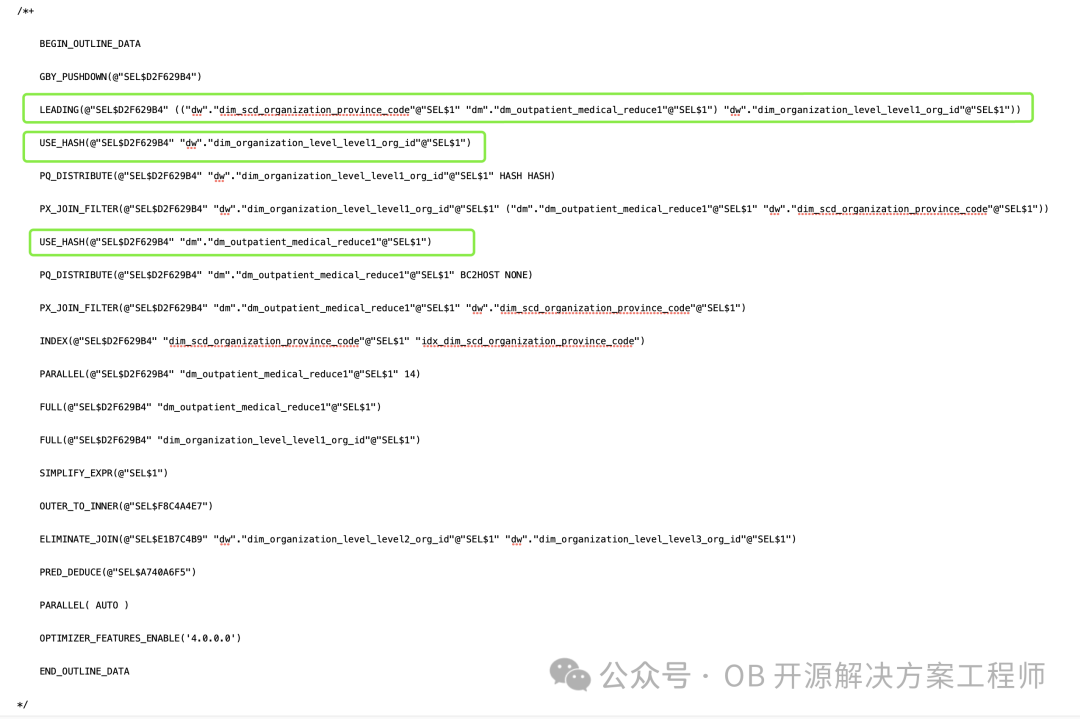
比如这个例子,USE_NL (xxx),Hint 换成/*+ NO_USE_NL(@"SEL$D2F629B4" "dm"."dm_outpatient_medical_reduce1"@"SEL$1")*/
来让这个算子不走 NLJ,再查看执行效率以及执行计划

如果执行结果不满足预期或者执行计划仍不是最优(比如:仍存在其他的nlj、关联顺序变化等),可以手动指定不合理的地方
/*+LEADING(@"SEL$D2F629B4" (("dw"."dim_scd_organization_province_code"@"SEL$1" "dm"."dm_outpatient_medical_reduce1"@"SEL$1") "dw"."dim_organization_level_level1_org_id"@"SEL$1")) USE_HASH(@"SEL$D2F629B4" "dw"."dim_organization_level_level1_org_id"@"SEL$1") USE_HASH(@"SEL$D2F629B4" "dm"."dm_outpatient_medical_reduce1"@"SEL$1")*/
这个 Hint 让 Leading 跟之前保持一致,dim_organization_level_level1_org_id 的关联算法也跟之前的保持一致,然后指定了 dm_outpatient_medical_reduce1 的关联算法由 USE_NL --> USE_HASH
写在最后
SQL问题可能的原因其实有很多,解决SQL问题很多时候还是依靠经验,我这里提供的一些思路也只是冰山一角,建议大家碰到SQL问题可以记录下来,处理得多了以后就会形成自己的一套方法论,也就会越来越得心用手。
这篇关于SQL问题的常用信息收集命令及解决思路 |OceanBase应用实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



