本文主要是介绍FaceChain-FACT:开源10秒写真生成,复用海量LoRa风格,基模友好型写真应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

github开源地址:https://github.com/modelscope/facechain/tree/main/facechain_adapter
魔搭创空间应用体验:魔搭社区
一、效果演示
FaceChain FACT的代码和模型目前已经在github和modelscope创空间上同步开源。FaceChain FACT具有简单的交互式界面设计,只需一张人物形象图片和简短的操作,即可实现无限风格写真和固定模板写真的生成。同时,FaceChain FACT还支持包括指定人物姿态、自定义风格LoRA模型、以及多人模板写真等进阶功能,具体示例如下:
a.)无限风格写真:
选择风格,上传人物形象,即可生成对应风格写真。操作界面:

生成结果:

b.)指定人物姿态:
在无限风格写真基础上,在高级选项中上传姿态参考图片。操作界面:


生成结果:

c.)指定风格LoRA:
在无限风格写真基础上,在高级选项中上传自定义风格LoRA模型并调整提示词和风格权重。操作界面:


生成结果:

d.)固定模板写真:
上传模板和人物形象,确定重绘人脸编号,即可生成对应写真。操作界面:

生成结果:

e.)多人模板写真:
在固定模板写真基础上,根据人脸编号处理多人模板不同人脸。操作界面:


生成结果:

f.)鲁棒性写真样例:
相比原版FaceChain,FaceChain FACT的人像生成体验也有了质的飞跃。1.)在生成速度方面,FaceChain FACT成功摆脱了冗长繁琐的训练阶段,将定制人像的生成时间由5分钟大幅缩短到10s左右,为用户带来无比流畅的使用体验。2.) 在生成效果方面,FaceChain FACT进一步提升了人脸ID保持的细腻程度,使其兼具真实的人像效果以及高质量的写真质感。同时,FaceChain FACT对FaceChain海量的精美风格以及姿态控制等功能具有丝滑的兼容能力,对于输入人脸图像光照不理想、表情夸张等情况也能准确从质量欠佳的图像中解耦出人物ID信息,保证生成写真图片具有高超的艺术表现力。
1.)输入光照异常样例:


2.)输入表情夸张样例:


二、原理介绍
AI写真的能力来源于以Stable Diffusion为代表的文生图大模型及其微调技术。由于大模型具有强大的泛化能力,因此可以通过在单一类型的数据和任务中进行微调的方式,在保持模型整体的文本跟随和图像生成能力的基础上,实现下游任务。基于训练和免训练的AI写真的技术基础就来自于对文生图模型进行不同的微调任务。目前市面上的AI写真大多采用“训练+生成”的两阶段模式,此时的微调任务为“生成固定人物ID的写真图片”,对应的训练数据为多张该人物ID的形象图片。该模式的效果与训练数据的规模成正相关,因此往往需要庞大的形象数据支撑以及一定的训练时间,这也增加了用户的使用成本。
不同于上述模式,免训练的AI写真将微调任务调整为“生成指定人物ID的写真图片”,即将人物ID形象图片(人脸图片)作为额外的输入,输出具有与输入形象具有相同ID特征的写真图片。该模式可以将线下训练与线上推理彻底分离,用户使用时直接基于微调后的模型进行写真生成,仅需一张图片,无需大量数据和训练等待时间,10秒钟即可生成专属AI写真。免训练AI写真的微调任务的基础算法是基于适配器(adapter)模块实现的,其基本结构如下图所示。人脸图片经过固定权重的图像编码器(image encoder)以及低参数量的特征投影层得到对齐后的特征,而后通过对固定权重的Stable Diffusion中的U-Net模块添加与文本条件类似的注意力机制模块实现对模型的微调。此时人脸信息作为独立分支的条件平行于文本信息一起送入模型中进行推理,故而可以使生成图片具有ID保持能力。

基于face adapter的基础算法尽管可以实现免训练AI写真,但仍需进行一定的调整以进一步优化其效果。市面上的免训练写真工具往往存在以下几点问题:写真图像质量差、写真文本跟随能力和风格保持能力不佳、写真人脸可控性和丰富度差、算法对ControlNet和风格Lora的兼容性不好等。针对上述问题,FaceChain将其归结于已有的用于免训练AI写真的微调任务耦合了过多人物ID以外的信息,并提出了解耦训练的人脸适配器算法(FaceChain Face Adapter with deCoupled Training,FaceChain FACT)以解决上述问题。通过在百万级别的写真数据上对Stable Diffusion模型进行微调,FaceChain FACT可以实现高质量的指定人物ID的写真图片生成。FaceChain FACT的整个框架如下图所示。

FaceChain FACT的解耦训练分为两个部分:从图像解耦人脸,以及从人脸解耦ID。已有方法往往将写真图像去噪作为微调任务,从而导致模型无法将注意力准确定位到人脸区域,从而导致Stable Diffusion的原有文生图功能受到影响。FaceChain FACT借鉴换脸算法的串行处理以及区域控制的优势,从结构和训练策略两方面实现从图像中解耦人脸的微调方法。在结构上,不同于已有方法使用并行的交叉注意力机制处理人脸和文本信息,FaceChain FACT采用串行处理的方法作为独立的adapter层插入原始Stable Diffusion的block中,从而将人脸适配作为类似换脸处理的独立步骤作用于去噪过程中,避免了彼此之间的干扰。在训练策略上,FaceChain FACT在原始的MSE损失函数的基础上引入人脸适配增量正则(Face Adapting Incremental Regularization,FAIR)损失函数,控制adapter层人脸适配步骤的特征增量集中于人脸区域。在推理过程中,用户可以通过调整face adapter的权重灵活调节生成效果,在保持Stable Diffusion原有文生图功能的同时,平衡人脸的保真度与泛化性。FAIR损失函数的具体形式如下所示:
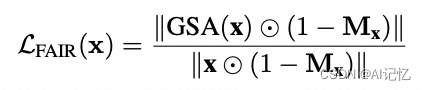
此外,针对写真人脸可控性和丰富度差的问题,FaceChain FACT提出从人脸解耦ID的训练方法,使得写真过程仅控制人物ID而非整个人脸。首先,为了更针对性提取人脸的ID信息并保持部分关键人脸细节,并且更好适应Stable Diffusion的结构,FaceChain FACT采用在大量人脸数据上预训练的基于Transformer架构的人脸特征提取器,抽取其倒数第二层的全部token,后续连接简单的注意力查询模型进行特征投影,从而使得提取的ID特征兼顾上述三点要求。另外,在训练过程中,FaceChain FACT使用Classifier Free Guidance(CFG)的方法,对相同ID对不同人脸写真图片进行随机打乱和舍弃,从而使得模型的输入人脸图片和用于去噪的目标图片可能具有同ID的不同人脸,以进一步避免模型过拟合于人脸的非ID信息。
三、拓展&共建
- 全身写真
- SDXL基模
- 破秒加速
- 多样风格
- 人物视频
这篇关于FaceChain-FACT:开源10秒写真生成,复用海量LoRa风格,基模友好型写真应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





