本文主要是介绍【机器学习300问】102、什么是混淆矩阵?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、混淆矩阵的定义
混淆矩阵是一种用于评估分类模型性能的评估指标。当模型对数据进行预测并将数据分配到预定义的类别时,混淆矩阵提供了一种直观的方式来总结这些预测与数据实际类别之间的对应关系。具体来说,它是一个表格。
二、分类模型性能评估一级指标
分类模型的性能评估指标有三个等级,一级评估指标如下:
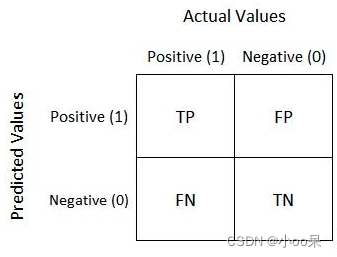
- 真正例(True Positives, TP):模型预测为正类,实际上也是正类的样本数。
- 假正例(False Positives, FP):模型预测为正类,但实际上为负类的样本数。
- 真负例(True Negatives, TN):模型预测为负类,实际上也是负类的样本数。
- 假负例(False Negatives, FN):模型预测为负类,但实际上为正类的样本数。
混淆矩阵就是根据一级分类指标得到的一张表。
我自己的理解是三句话:
第一句:分类你可以理解成猜迷,猜的对不对用“T真,F假”来表示。
第二句:你猜的这个东西的时候,你猜测它类别是“P正”还是“N负”。
第三句:你猜的这个东西,它本身的分类用“标签label”表示。
所以按照上面的三句话理解,举几个例子:
情况一:这个东西,本来的“标签”是“正”的,我猜它是“正”,意味着我猜对了,故TP。
情况二:这个东西,本来的“标签”是“负”的,我猜它是“负”,意味着我猜对了,故TN。
情况三:这个东西,本来的“标签”是“正”的,我猜它是“负”,意味着我猜错了,故FN。
情况四:这个东西,本来的“标签”是“负”的,我猜它是“正”,意味着我猜错了,故FP。
二、分类模型性能评估二级指标
分类模型的二级评估指标在之前的文章中提到过,但没有总结过。因此在本文章简单总结一下:
| 二级指标 | 公式 | 意义 |
| 准确率(Accuracy) | 分类模型所有判断正确的结果占总观测值的比重 | |
| 精确率(Precision) | 在模型预测是Positive的所有结果中,模型预测对的比重 | |
| 召回率(Recall) (又叫灵敏度Sensitivity) | 在真实值是Positive的所有结果中,模型预测对的比重 | |
| 特异度(Specificity) | 在真实值是Negative的所有结果中,模型预测对的比重 |
更多更详细的知识点,在往期文章中有提到,下面是跳转链接:
【机器学习300问】25、常见的模型评估指标有哪些?![]() https://blog.csdn.net/qq_39780701/article/details/136407056
https://blog.csdn.net/qq_39780701/article/details/136407056
三、分类模型新能评估三级指标
分类模型的三级评估指标就是F1分数,在之前的文章中提到过。这里就不赘述了。
【机器学习300问】32、F1分数是什么?![]() https://blog.csdn.net/qq_39780701/article/details/136607068
https://blog.csdn.net/qq_39780701/article/details/136607068
四、混淆矩阵举例说明
以一个图片多分类问题为例,想要判断一张图片是“猫”、“狗”和“猪”其中的哪一种。

混淆矩阵中的数值是样本数量,如果我们要计算准确率accuracy,那么可以统计所有表中数字的总和做分母。对角线相加做分子(因为对角线上的元素代表模型预测结果是正确的)。可以算出
这篇关于【机器学习300问】102、什么是混淆矩阵?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








