本文主要是介绍70 JpaRepository 查询方法没有实现却可以正常使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
这是一个 我最开始看着 都挺奇怪的一个问题, 呵呵 存在一些 XXRepository的一些方法, 没有具体的方法实现, 但是 依然可以调用该方法 处理业务
呵呵 比如 如下方法, 可以再业务代码中直接 @Resource 注入 TaskRepository, 然后也可以正常的调用他的 existsByTopic 方法, 但是 这个方法 却没有具体的实现, 一时之间很让人迷惑
public interface TaskRepository extends JpaRepository<Task, String>, TaskCustomRepository {boolean existsByTopic(String topic);
}方法名的解析为 PartTree
呵呵 这个问题 该从哪里入手呢?, 呵呵 首先当然是这个 TaskRepository 的实例了, 这里也会分两步, 一是实例是怎么生成的[这个不急, 后面介绍 : Spring 对于这部分 JpaRepository 的处理], 二是生成的实例到底是什么, 什么东西决定了 它能够执行 existsByTopic
首先我们看一下 TaskRepository 的这个实例, 关于 Spring的代理对象 可以参照文章 Spring的代理对象

可以看到这里 advisors 列表有 8 个, 怎么确定 哪一个是我们想要的呢
第一个 ExposeInvocationInterceptor$1, 呵呵 熟悉的朋友都知道是 吧当前 MethodInvokcation 封装到了一个 context 里面, 以提供更内层可以更方便的获取 MethodInvocation
第二个 CrudMethodMetadataPopulatingMethodInterceptor, 看下备注 ”{@link MethodInterceptor} to build and cache {@link DefaultCrudMethodMetadata} instances for the invoked methods, Will bind the found information to a {@link TransactionSynchronizationManager} for later lookup.“, 呵呵 显然不是, 再看一下实现 和备注说的事情是差不多的
第三个 事务相关的 Interceptor, 显然不是
第四个 事务相关的 Interceptor, 显然不是
第五个 DefaultMethodInvokingMethodInterceptor, 看下备注 "Method interceptor to invoke default methods on the repository proxy." 似乎是和默认方法相关的 Interceptor 显然不是, 看下实现 果然是和 默认方法相关
第六个 QueryExecutorMethodInterceptor, 查询方法 "This {@link MethodInterceptor} intercepts calls to methods of the custom implementation and delegates the to it if configured. Furthermore it resolves method calls to finders and triggers execution of them. You can rely on having a custom repository implementation instance set if this returns true." 看下备注, 以及方法名称 还是有一些相似
第七个 ImplementationMethodExecutionInterceptor 呵呵 这个看方法的实现, 更像是支持 TaskCustomRepository 的这部分的实现
第八个 事务相关的 Interceptor, 显然不是
然后查看一下 QueryExecutorMethodInterceptor 的对象, 呵呵 这里有一个 queries 的一个映射, key 是 existsByTopic, value 是一个 PartTreeQuery, 这个 PartTreeQuery 里面似乎是封装了 existsByTopic 的语义

想都不用想 existsByTopic 这个方法名称 坑定会被解析成类似于 "select count(*) > 0 from task where topic = '$topic'; " 的类似语义的 sql, 那么 具体是 怎么解析的, 以及 具体的sql是什么, 这部分的代码体现呢?
根据上面的推断, 估计 这个 existsByTopic 的解析应该是在这个 PartTreeQuery 相关的地方
来到 PartTree 的构造方法里面, 可以看到传入的 source 为方法名, existsByTopic, 然后 PartTree 里面有两个对象, 一个是 Subject, 一个是 Predicate
这个 Subject 看名字还不咋好看, 看字段大概的意思是这是什么类型的方法, 这里区分了几类特性, 计数查询, 是否存在的查询, 去重的查询, 是否是删除
Predicate 一看名字应该能够看出来是限定查询条件以及一些其他的参数控制的, 这里大概的意思是 topic 是否等于 上下文传入的参数
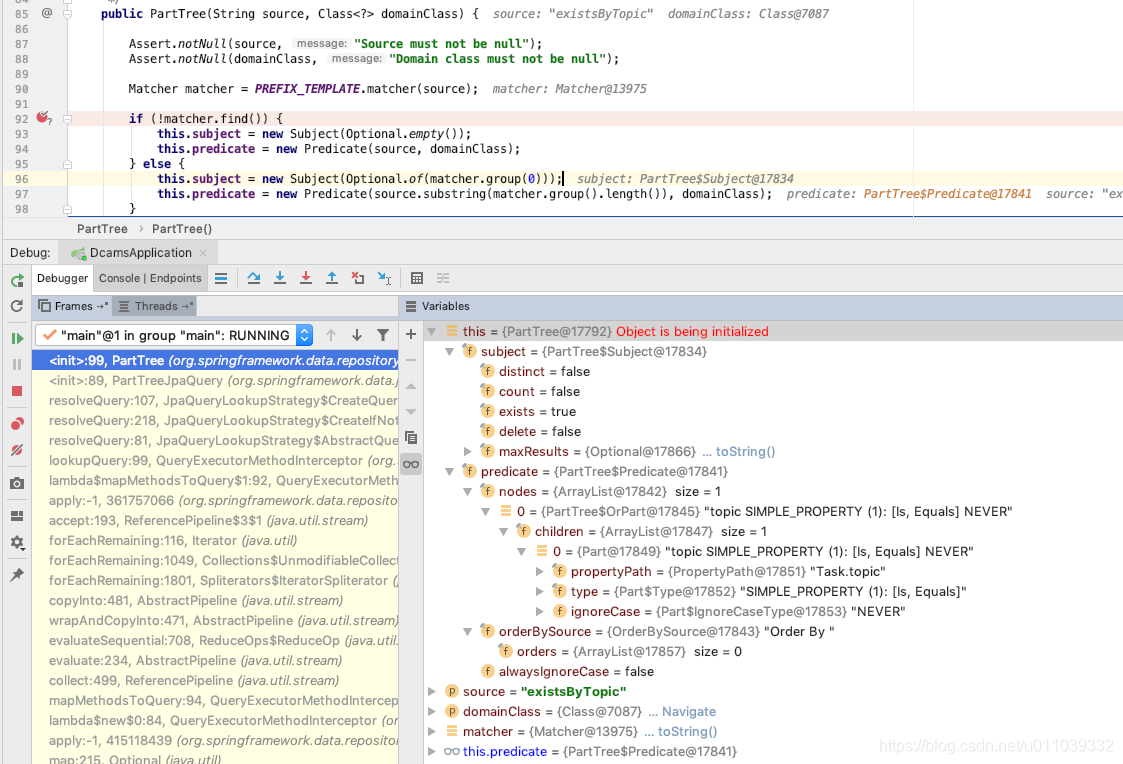
也可以看到的一点是对于 existsByTopic 的解析是通过正则来做的模式匹配, 对于方法名称做了一定的逻辑意义区分, 对于符合 patter 的 xxxBy 这一部分是作为 PartTree 的 Subject 部分
对于 By 之后的部分是来解析作为 Predicate
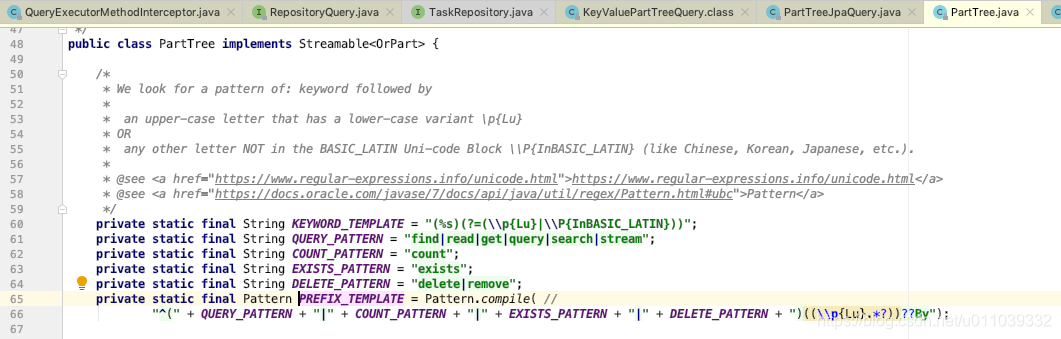
PartTree.Subject 的解析
判断是否属于某一特性同样是使用的是正则 或者 字符串的一些常用 api, 当然有些特性是互斥的, 这个是正则层面上就回区分开
对于 Subject 可能 findDistinctFirst10By 这种就算是比较复杂的了, distinct : true, count : false, exists : false, delete : false, maxResults : 10

PartTree.Predicate 的解析
Predicate 这个层面上需要确定几个东西, 是否忽略大小写[模式匹配确认], 是否需要排序, 以及根据什么排序, 可以参见下面的 OrderBySorce
另外还有就是我们关注的条件, 可以看到的是这里是将条件根据 Or 来进行 split, 所以 nodes 中也装的是 OrPart, 所以说在这里 Or 的优先级是比 And 低的
cond1 and cond2 or cond3 and cond4 等价于 (cond1 and cond2) or (cond3 and cond4)

我们可以看一下一个稍微比较复杂的示例 "TopicAndIdOrCreatedOnAndLastUpdatedOnAllIgnoreCaseOrderByTopicDesc"

当然这里也是存在一些可以 hack 的东西, 我的理解应该算是 bug 了吧, 这里的 AllIgnoreCase 是可以放在 source 的任何的地方的
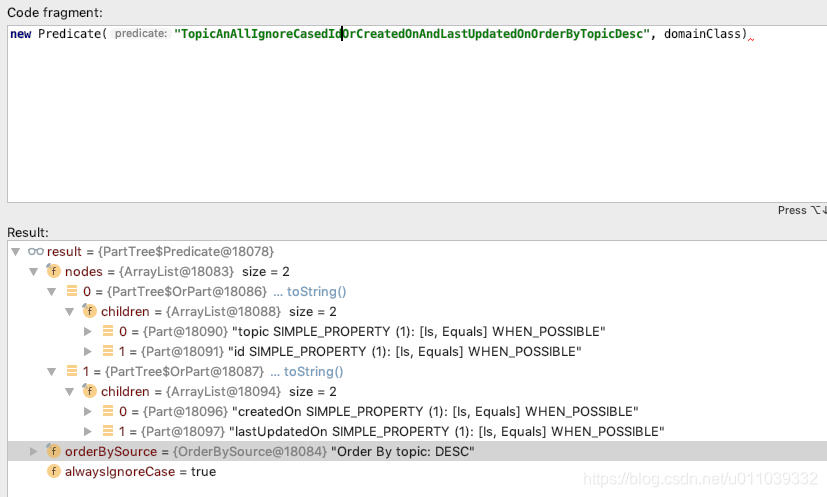
PartTree. OrderBySorce 的解析
根据 Asc, Desc 来进行 split, 封装可能存在多组排序的 字段 + 排序方式 信息
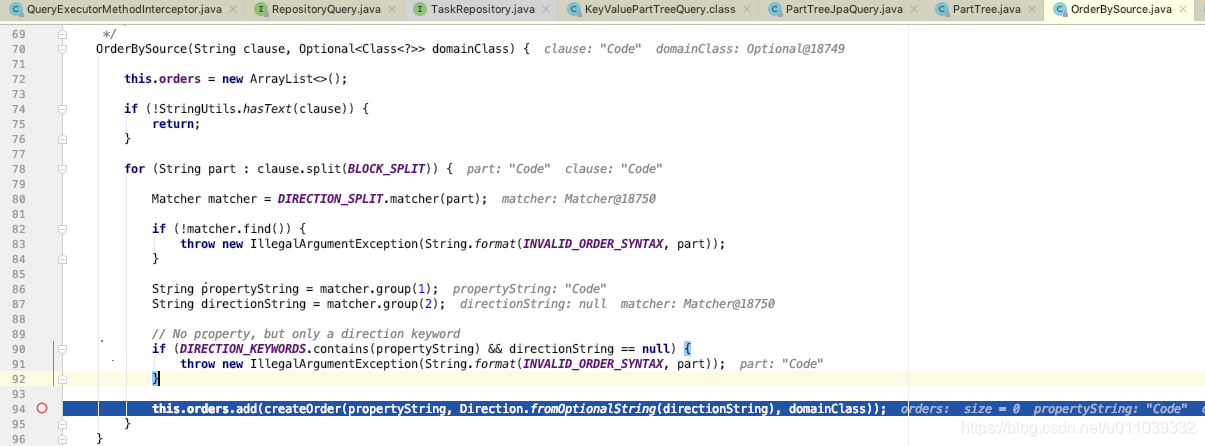
PartTree. OrPart 的解析
根据 And 进行拆分, 将每一个条件封装成 children 里面的一个 Part[AndPart]

我们来看一个稍微比较复杂的 OrPart "TopicIsNotAndIdIsLessThanAndCreatedOnEndingWithAndLastUpdatedOnIsContainingIgnoreCase"

PartTree.Part 的解析
这里面就对应于一个最小的原子条件, 拆分成三部分, 是否 ignorecase, 操作类型
操作的字段, 至于参数 是运行时由程序传入的

我们来看一个稍微比较复杂的 Part[AndPart] "TopicMatchesIgnoreCaseRegex"

呵呵 整个的 PartTree 的这部分的差不多就是这些吧, 最外层 Subject + Predicate
Predicate 拆分为 orPartList + orderBy
OrPartList 拆分为 Part + Part + ... + Part
Part 拆分为 proeprty + operateType + ignoreCase
这种 PartTree 的整体的 Schema 也可以通过上面的代码 来抽象, 或者 有专门的规范文档 : Spring Data JPA - Reference Documentation
以上的 PartTree 的解析流程 是在初始化 JpaRepository 实例的时候处理的, 这里是创建 QueryExecutorMethodInterceptor 的初始化方法里面
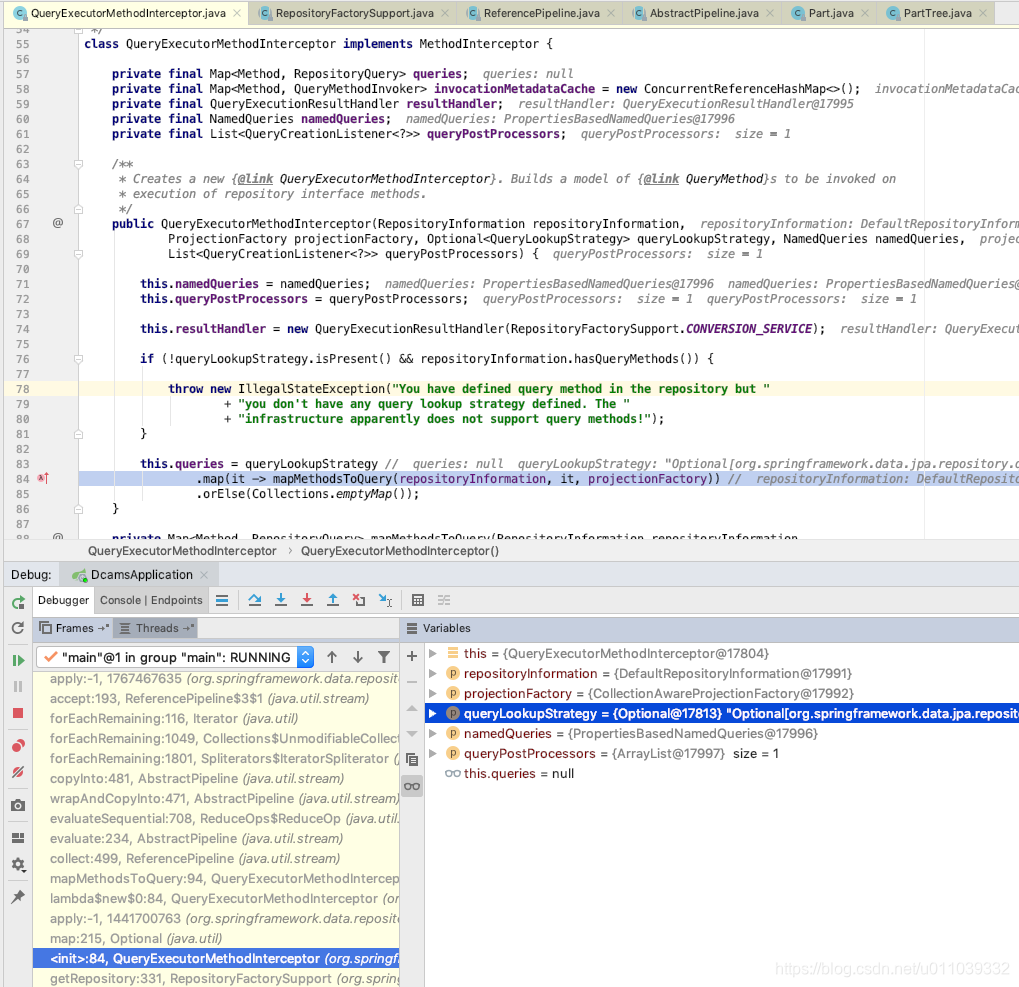
创建最上面的 TaskRepository 的实例的地方, 这里添加了 QueryExecutorMethodInterceptor 的 Advise
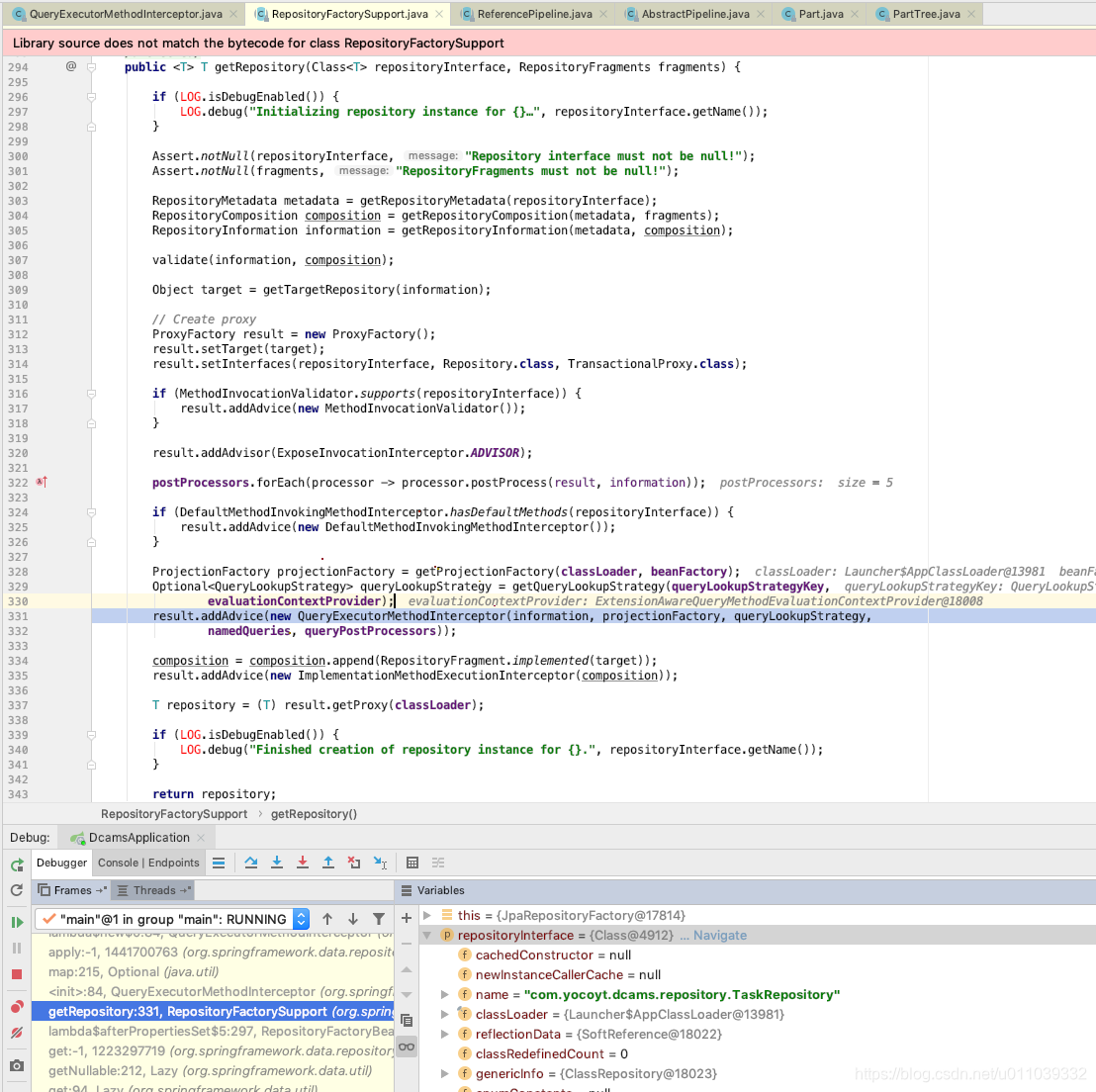
PartTree 怎么 apply
我们来到 真正处理业务的地方, 呵呵 简单的思路就是直接在 sessionImpl.list 来一个断点, 看这里的 sql, 以及断点堆栈上下文 确实就是调用 TaskRepository. existsByTopic 的地方
并且这里也可以看到 existsByTopic 生成出来的 sql 大致是什么样的, 以及运行时传入的参数是什么
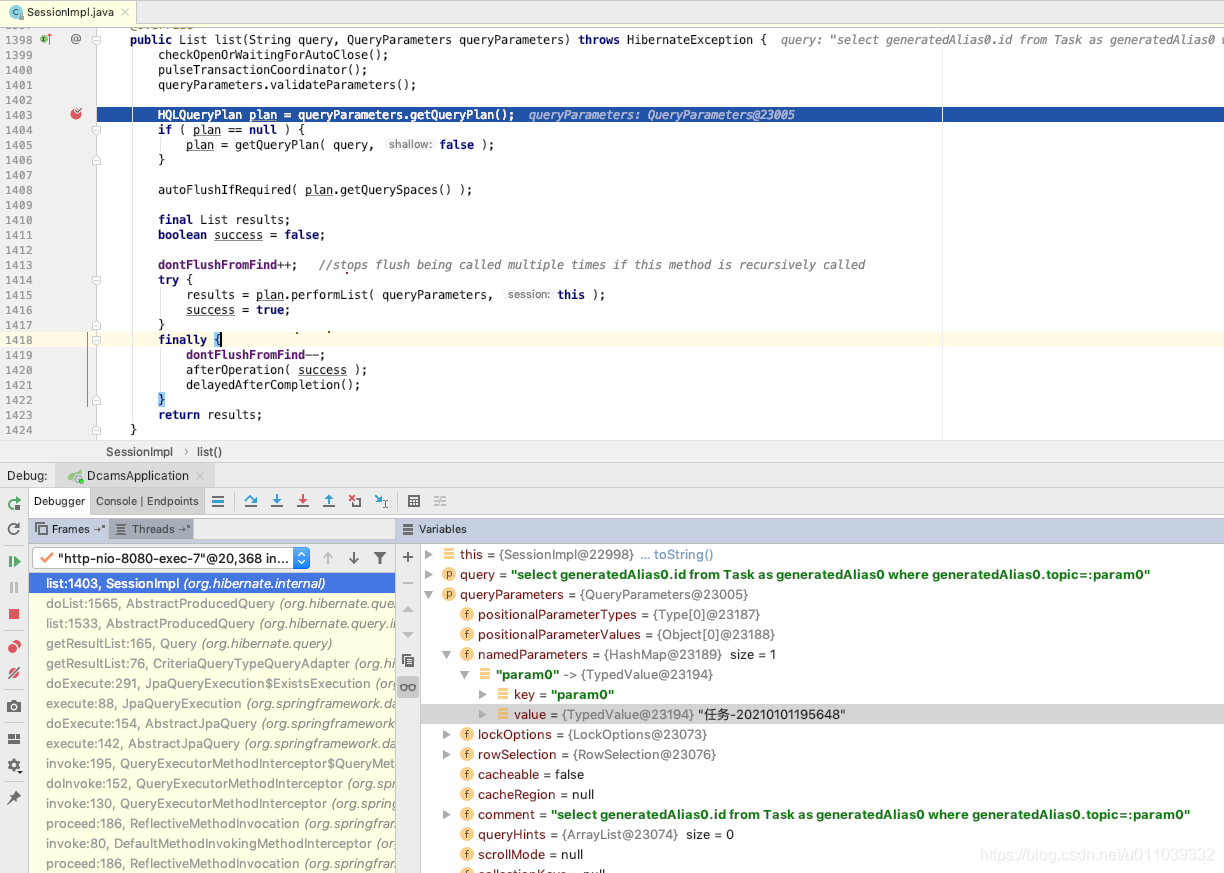
上面的业务的 sql 来自于 AbstractProducedQuery

再来看看这个 AbstractProducedQuery 实例来自于 ExistsExecution, query.createQuery(accessor)
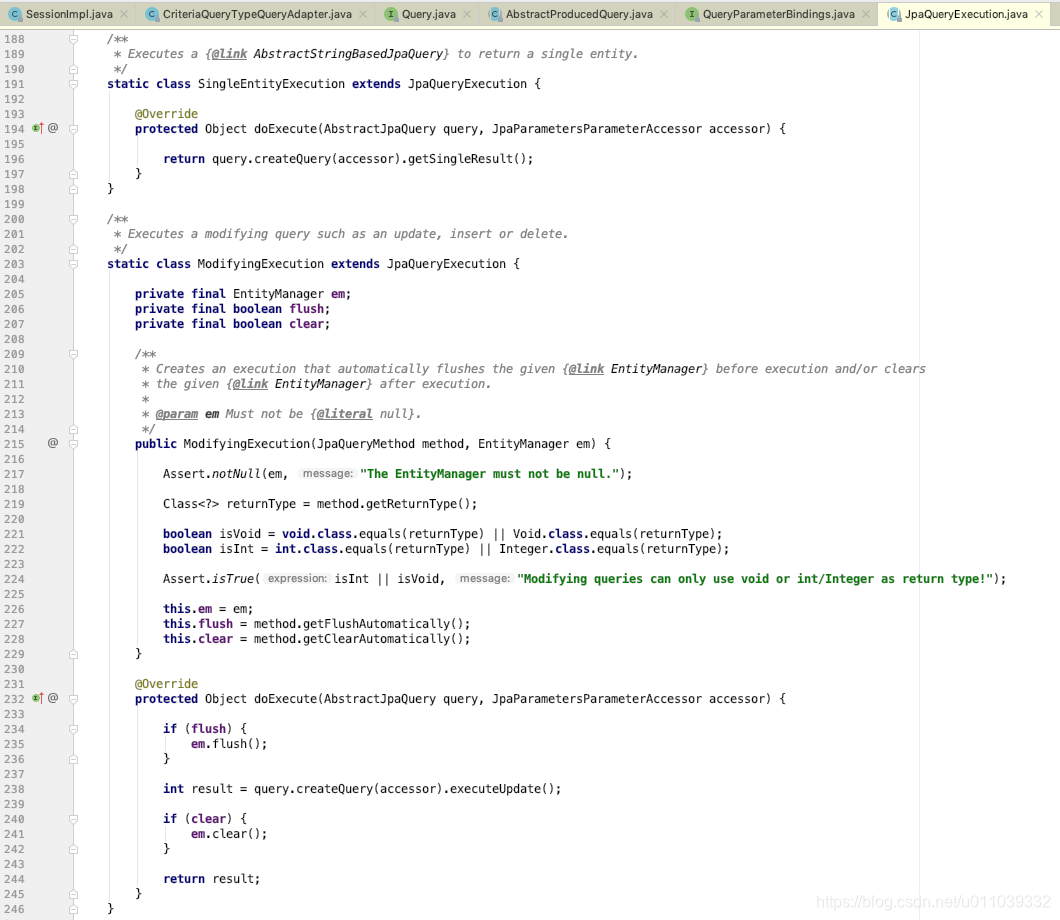
我们先来看下宏观上 ExistsExecution 的实现, 返回的是 boolean, 判断的是 生成的业务sql查询查询是否有结果

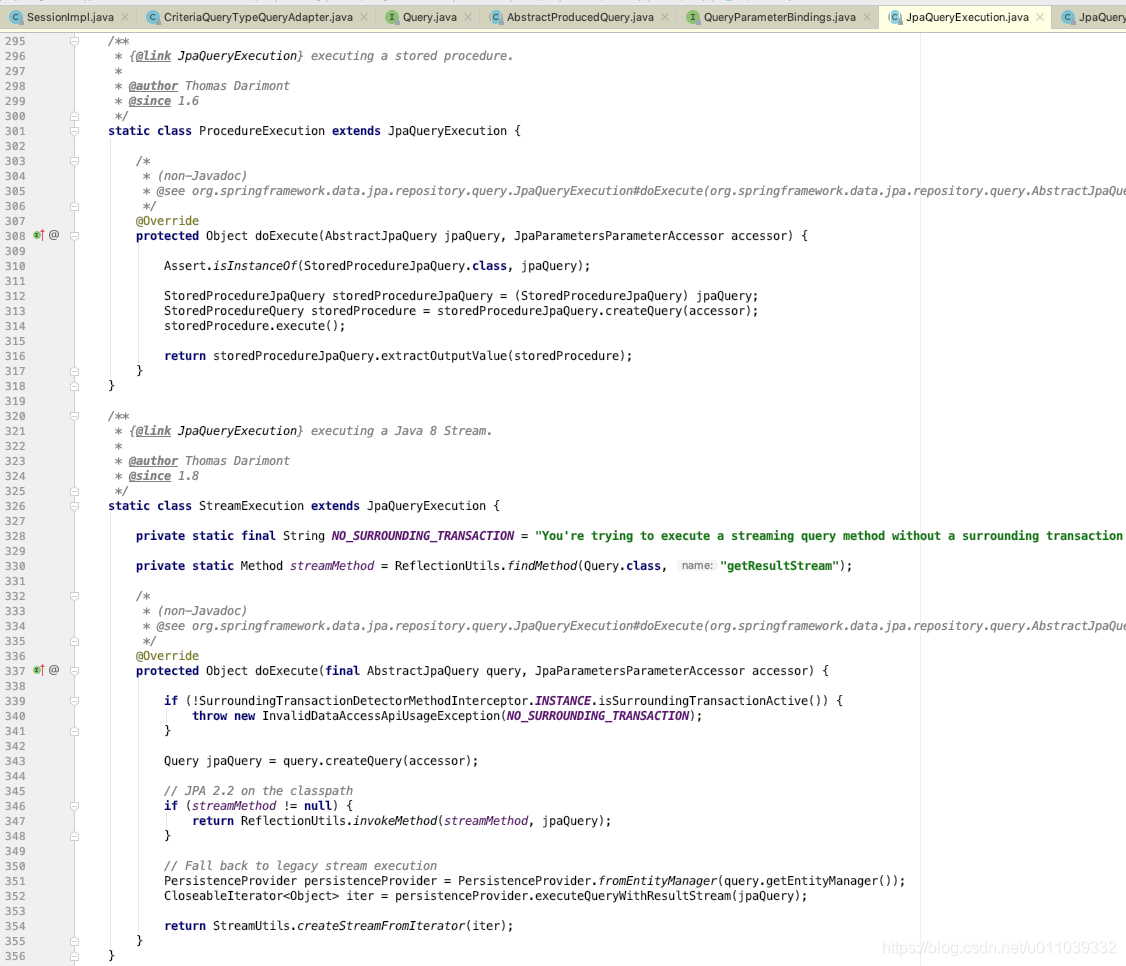
除了 ExistsExecution 之外的其他的 XXXExecution
呵呵呵 可以看一下 一些其他的 Execution, 基本上都是基于 query.createQuery(accessor) 的查询结果在处理业务, 增加了一些 自己的这个实现的一些特定的 feature
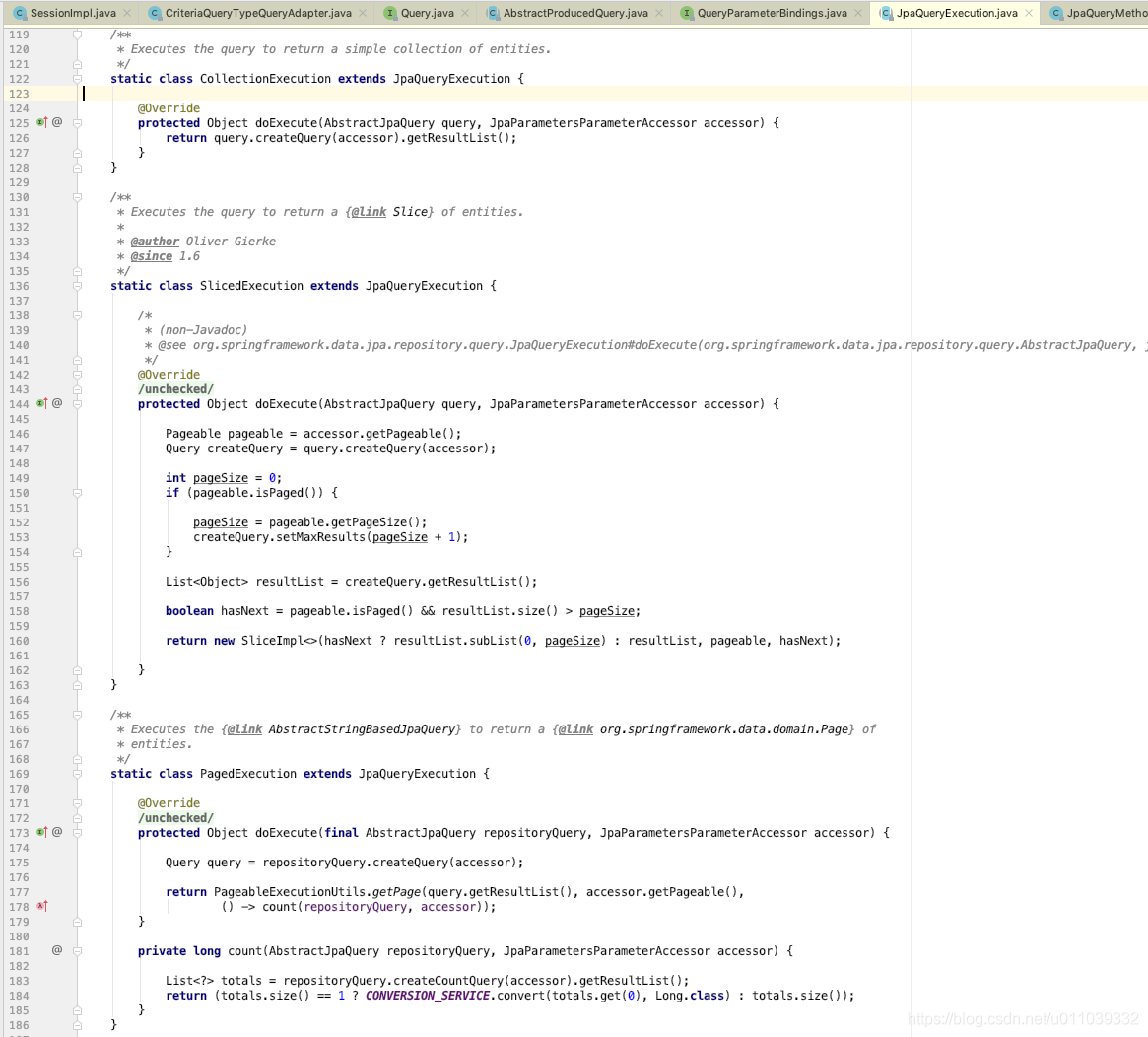

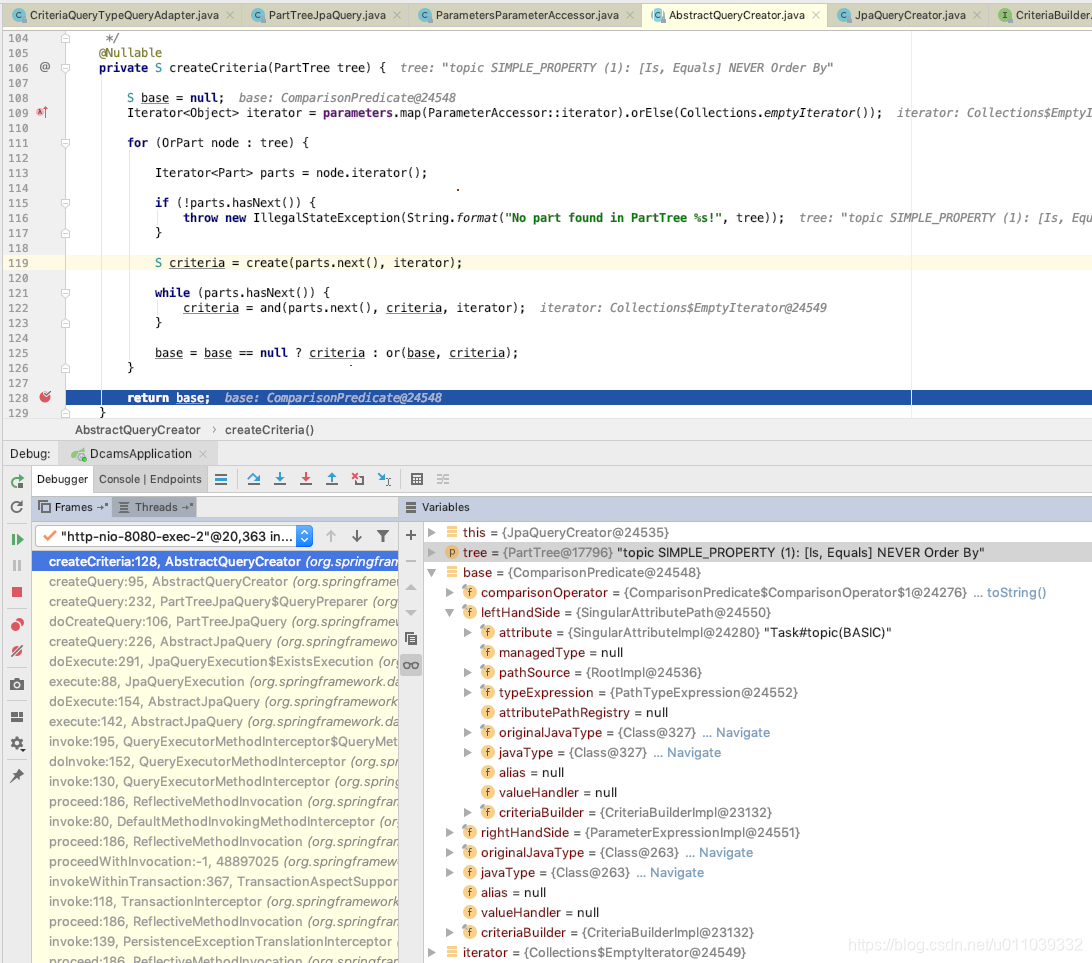
PartTree 怎么转换为业务 sql
将 PartTree 转换为 XXPredicate, 里面包含了 Predicate 这部分的转换
将 Predicate, Sort 封装成为 CriteriaQuery
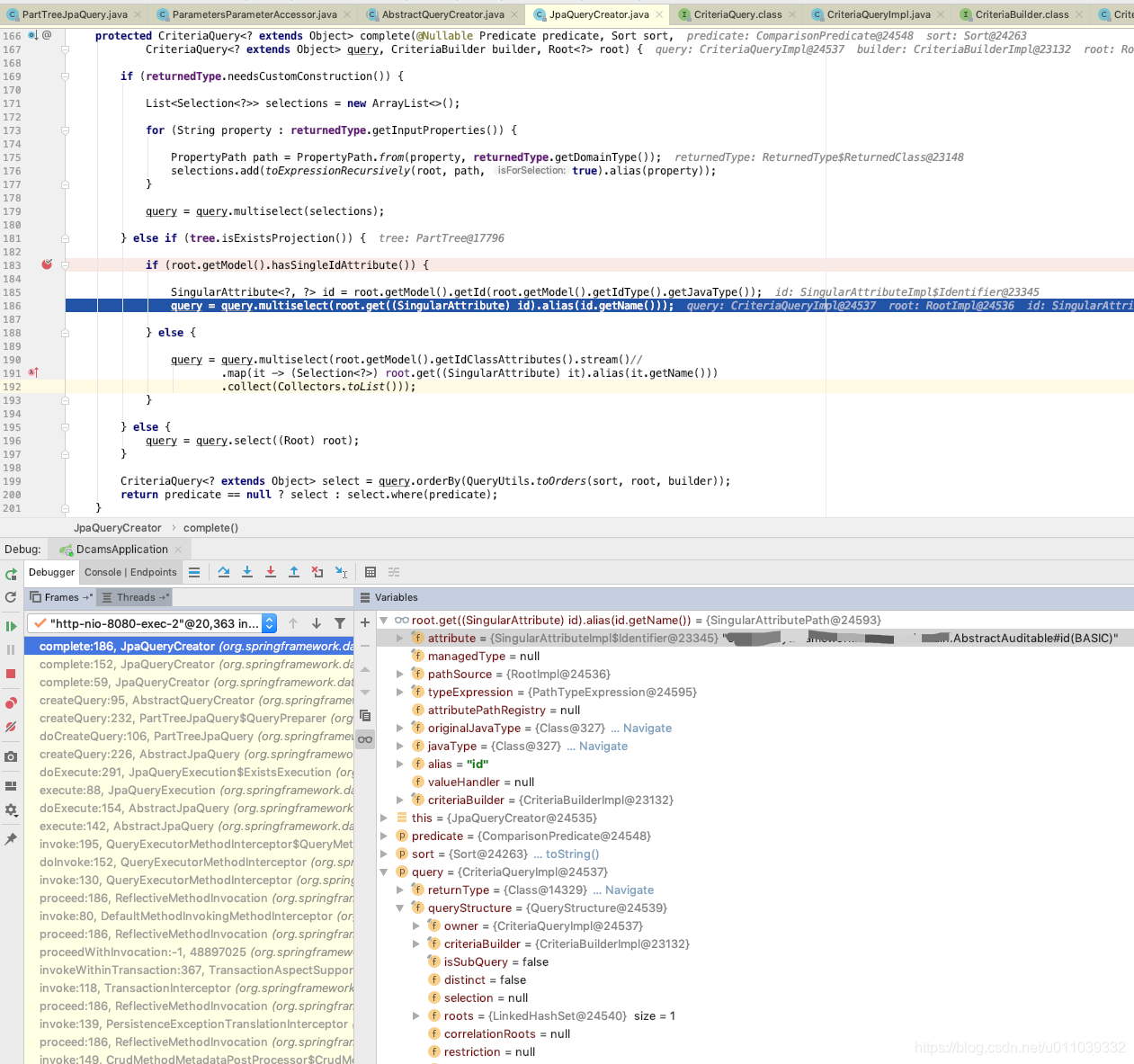
根据 QueryStructure 里面的 selection 和 restriction 来构造业务 sql, 比如我们这里 "existsByTopic" 构造完成之后的 sql 为 "select generatedAlias0.id from Task as generatedAlias0 where generatedAlias0.topic=:param0"
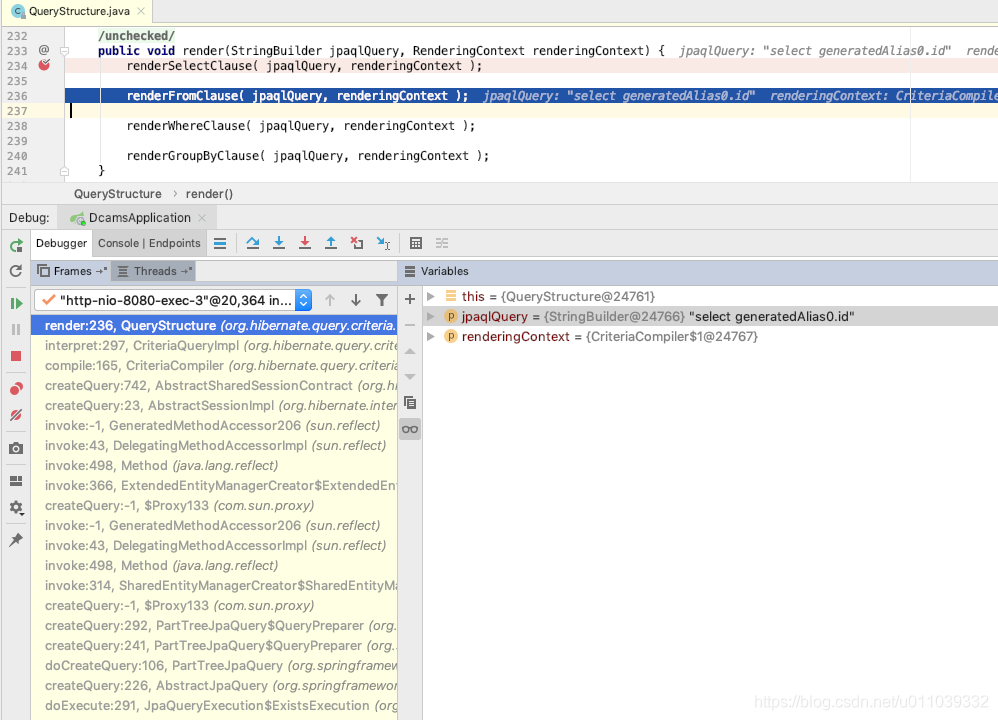
参数的绑定
我们先来看一下 获取运行时参数的地方, 是通过 ParameterBinder 获取的参数, 并且 bind 到 query 上面
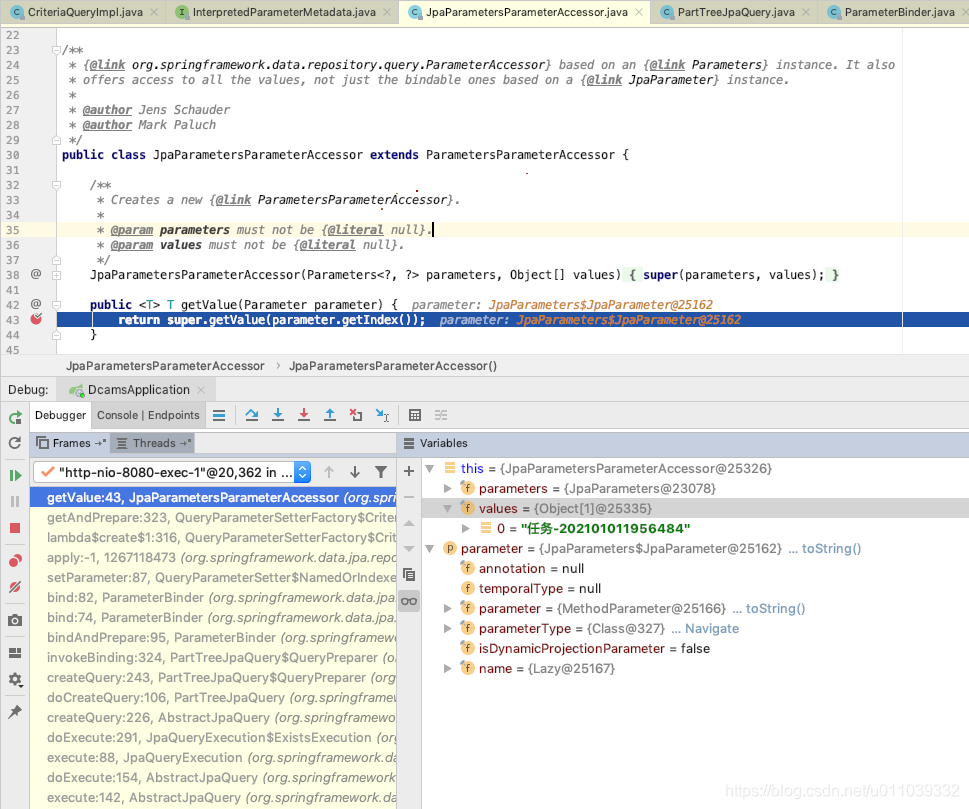
这里的获取的运行时的参数来自于 accessor, 然后下面的 query.setParameter 绑定了参数 到 query 上面
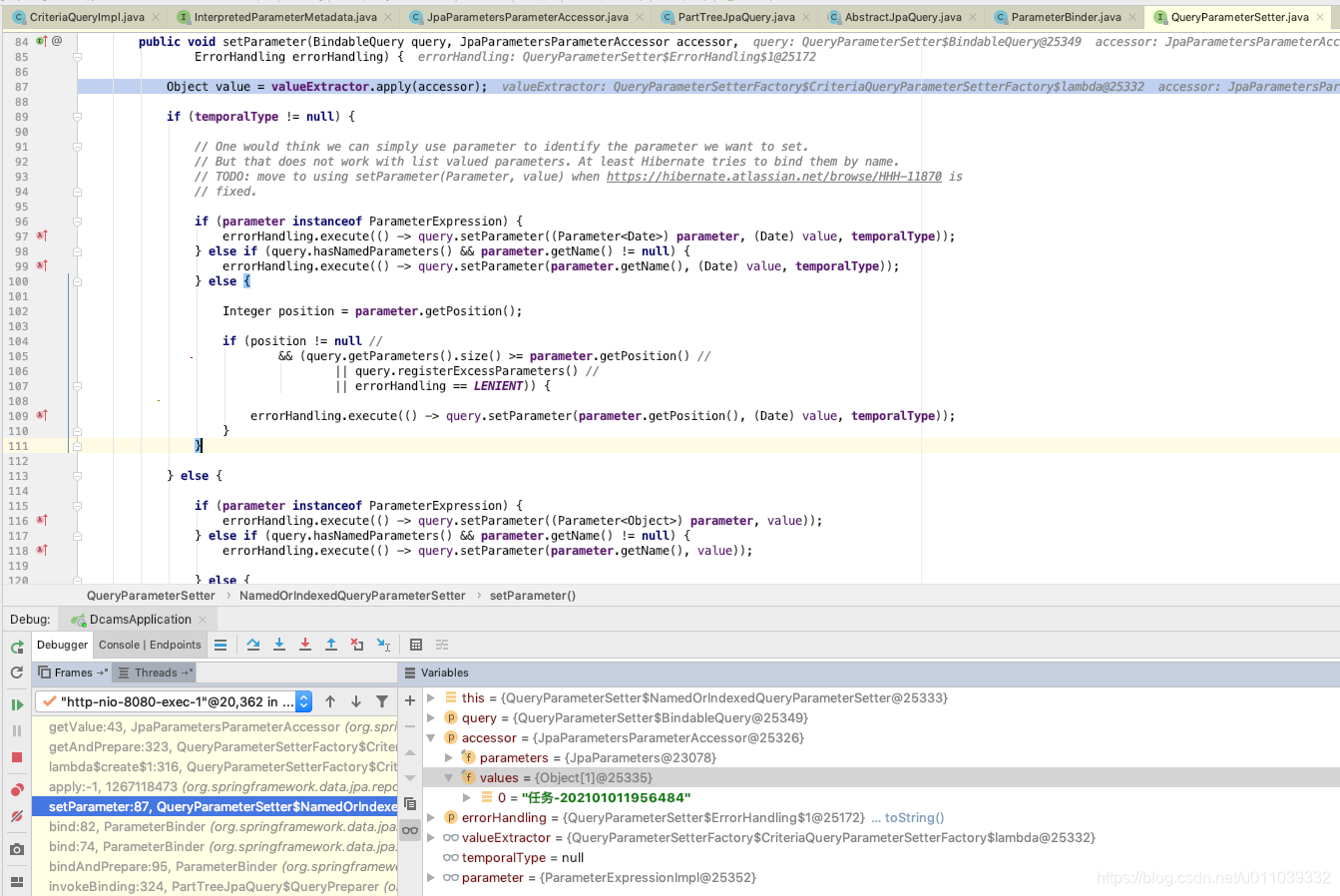
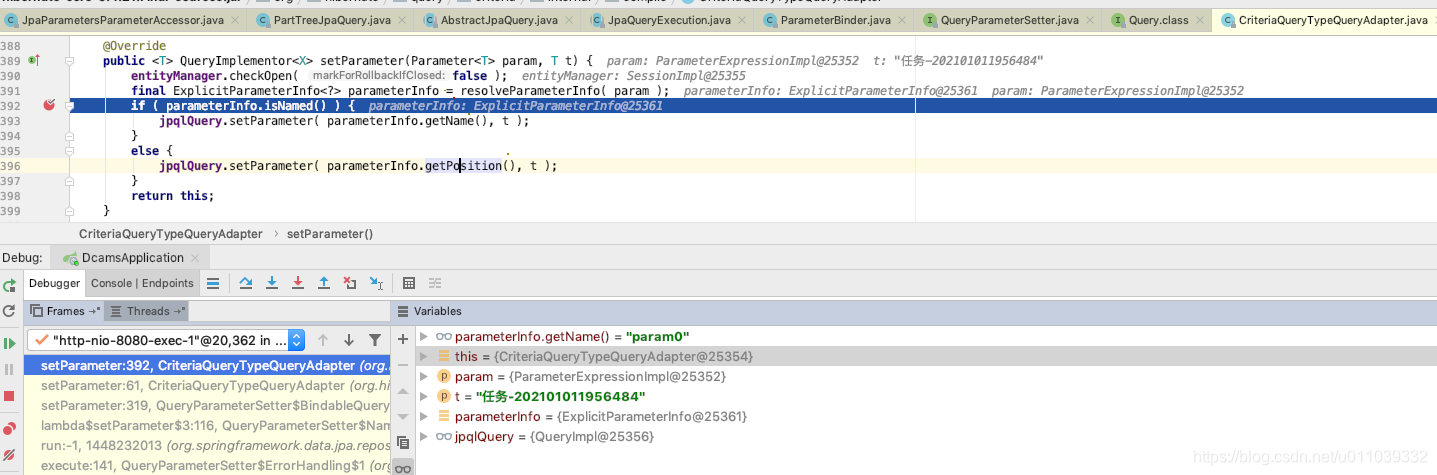
accessor 来自于 AbstractJpaQuery, 这里可以获取到 运行时的参数 以及一些方法级别的上下文信息

具体的参数绑定到 query, 呵呵 更细节的我们就不往下看了
完
参考
Spring Data JPA - Reference Documentation
Spring的代理对象
这篇关于70 JpaRepository 查询方法没有实现却可以正常使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




