本文主要是介绍ElasticSearch 内存那点事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“该给ES分配多少内存?”
“JVM参数如何优化?“
“为何我的Heap占用这么高?”
“为何经常有某个field的数据量超出内存限制的异常?“
“为何感觉上没多少数据,也会经常Out Of Memory?”
以上问题,显然没有一个统一的数学公式能够给出答案。 和数据库类似,ES对于内存的消耗,和很多因素相关,诸如数据总量、mapping设置、查询方式、查询频度等等。默认的设置虽开箱即用,但不能适用每一种使用场景。作为ES的开发、运维人员,如果不了解ES对内存使用的一些基本原理,就很难针对特有的应用场景,有效的测试、规划和管理集群,从而踩到各种坑,被各种问题挫败。
要理解ES如何使用内存,先要尊重下面两个基本事实:
1. ES是JAVA应用
2. 底层存储引擎是基于Lucene的
看似很普通是吗?但其实没多少人真正理解这意味着什么。
首先,作为一个JAVA应用,就脱离不开JVM和GC。很多人上手ES的时候,对GC一点概念都没有就去网上抄各种JVM“优化”参数,却仍然被heap不够用,内存溢出这样的问题搞得焦头烂额。了解JVM GC的概念和基本工作机制是很有必要的,本文不在此做过多探讨,读者可以自行Google相关资料进行学习。如何知道ES heap是否真的有压力了? 推荐阅读这篇博客:Understanding Memory Pressure Indicator。 即使对于JVM GC机制不够熟悉,头脑里还是需要有这么一个基本概念: 应用层面生成大量长生命周期的对象,是给heap造成压力的主要原因,例如读取一大片数据在内存中进行排序,或者在heap内部建cache缓存大量数据。如果GC释放的空间有限,而应用层面持续大量申请新对象,GC频度就开始上升,同时会消耗掉很多CPU时间。严重时可能恶性循环,导致整个集群停工。因此在使用ES的过程中,要知道哪些设置和操作容易造成以上问题,有针对性的予以规避。
其次,Lucene的倒排索引(Inverted Index)是先在内存里生成,然后定期以段文件(segment file)的形式刷到磁盘的。每个段实际就是一个完整的倒排索引,并且一旦写到磁盘上就不会做修改。 API层面的文档更新和删除实际上是增量写入的一种特殊文档,会保存在新的段里。不变的段文件易于被操作系统cache,热数据几乎等效于内存访问。
基于以上2个基本事实,我们不难理解,为何官方建议的heap size不要超过系统可用内存的一半。heap以外的内存并不会被浪费,操作系统会很开心的利用他们来cache被用读取过的段文件。
Heap分配多少合适?遵从官方建议就没错。 不要超过系统可用内存的一半,并且不要超过32GB。JVM参数呢?对于初级用户来说,并不需要做特别调整,仍然遵从官方的建议,将xms和xmx设置成和heap一样大小,避免动态分配heap size就好了。虽然有针对性的调整JVM参数可以带来些许GC效率的提升,当有一些“坏”用例的时候,这些调整并不会有什么魔法效果帮你减轻heap压力,甚至可能让问题更糟糕。
那么,ES的heap是如何被瓜分掉的? 说几个我知道的内存消耗大户并分别做解读:
1. segment memory
2. filter cache
3. field data cache
4. bulk queue
5. indexing buffer
6. state buffer
7. 超大搜索聚合结果集的fetch
Segment Memory
Segment不是file吗?segment memory又是什么?前面提到过,一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。 由于词典的size会很大,全部装载到heap里不现实,因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
下面是词典索引和词典主存储之间的一个对应关系图:
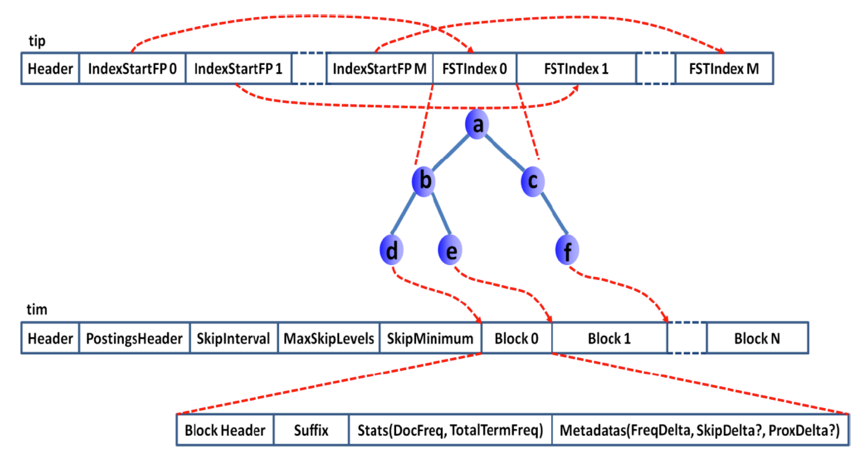
Lucene file的完整数据结构参见Apache Lucene - Index File Formats
说了这么多,要传达的一个意思就是,ES的data node存储数据并非只是耗费磁盘空间的,为了加速数据的访问,每个segment都有会一些索引数据驻留在heap里。因此segment越多,瓜分掉的heap也越多,并且这部分heap是无法被GC掉的! 理解这点对于监控和管理集群容量很重要,当一个node的segment memory占用过多的时候,就需要考虑删除、归档数据,或者扩容了。
怎么知道segment memory占用情况呢? CAT API可以给出答案。
1. 查看一个索引所有segment的memory占用情况:
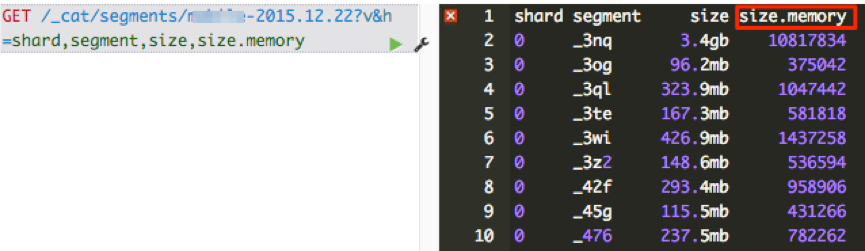
2. 查看一个node上所有segment占用的memory总和:
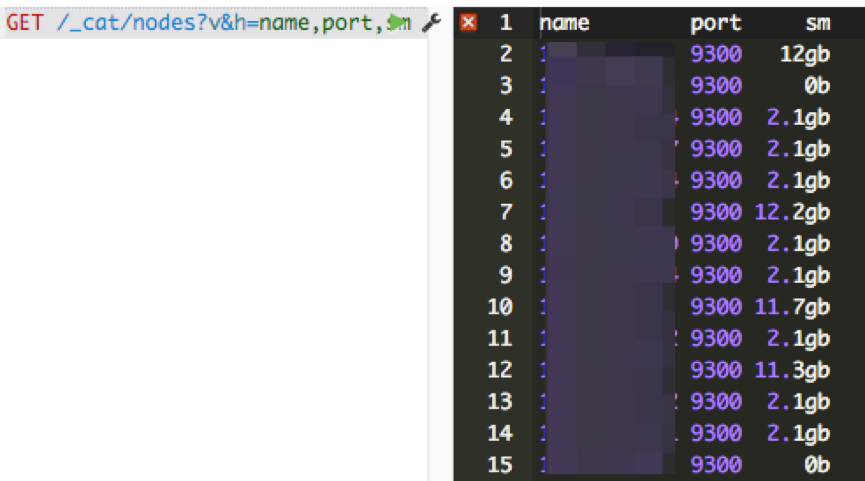
那么有哪些途径减少data node上的segment memory占用呢? 总结起来有三种方法:
1. 删除不用的索引
2. 关闭索引 (文件仍然存在于磁盘,只是释放掉内存)。需要的时候可以重新打开。
3. 定期对不再更新的索引做optimize (ES2.0以后更改为force merge api)。这Optimze的实质是对segment file强制做合并,可以节省大量的segment memory。
Filter Cache
Filter cache是用来缓存使用过的filter的结果集的,需要注意的是这个缓存也是常驻heap,无法GC的。我的经验是默认的10% heap设置工作得够好了,如果实际使用中heap没什么压力的情况下,才考虑加大这个设置。
Field Data cache
在有大量排序、数据聚合的应用场景,可以说field data cache是性能和稳定性的杀手。 对搜索结果做排序或者聚合操作,需要将倒排索引里的数据进行解析,然后进行一次倒排。 这个过程非常耗费时间,因此ES 2.0以前的版本主要依赖这个cache缓存已经计算过的数据,提升性能。但是由于heap空间有限,当遇到用户对海量数据做计算的时候,就很容易导致heap吃紧,集群频繁GC,根本无法完成计算过程。 ES2.0以后,正式默认启用Doc Values特性(1.x需要手动更改mapping开启),将field data在indexing time构建在磁盘上,经过一系列优化,可以达到比之前采用field data cache机制更好的性能。因此需要限制对field data cache的使用,最好是完全不用,可以极大释放heap压力。 需要注意的是,很多同学已经升级到ES2.0,或者1.0里已经设置mapping启用了doc values,在kibana里仍然会遇到问题。 这里一个陷阱就在于kibana的table panel可以对所有字段排序。 设想如果有一个字段是analyzed过的,而用户去点击对应字段的排序表头是什么后果? 一来排序的结果并不是用户想要的,排序的对象实际是词典; 二来analyzed过的字段无法利用doc values,需要装载到field data cache,数据量很大的情况下可能集群就在忙着GC或者根本出不来结果。
Bulk Queue
一般来说,Bulk queue不会消耗很多的heap,但是见过一些用户为了提高bulk的速度,客户端设置了很大的并发量,并且将bulk Queue设置到不可思议的大,比如好几千。 Bulk Queue是做什么用的?当所有的bulk thread都在忙,无法响应新的bulk request的时候,将request在内存里排列起来,然后慢慢清掉。 这在应对短暂的请求爆发的时候有用,但是如果集群本身索引速度一直跟不上,设置的好几千的queue都满了会是什么状况呢? 取决于一个bulk的数据量大小,乘上queue的大小,heap很有可能就不够用,内存溢出了。一般来说官方默认的thread pool设置已经能很好的工作了,建议不要随意去“调优”相关的设置,很多时候都是适得其反的效果。
Indexing Buffer
Indexing Buffer是用来缓存新数据,当其满了或者refresh/flush interval到了,就会以segment file的形式写入到磁盘。 这个参数的默认值是10% heap size。根据经验,这个默认值也能够很好的工作,应对很大的索引吞吐量。 但有些用户认为这个buffer越大吞吐量越高,因此见过有用户将其设置为40%的。到了极端的情况,写入速度很高的时候,40%都被占用,导致OOM。
Cluster State Buffer
ES被设计成每个node都可以响应用户的api请求,因此每个node的内存里都包含有一份集群状态的拷贝。这个cluster state包含诸如集群有多少个node,多少个index,每个index的mapping是什么?有少shard,每个shard的分配情况等等 (ES有各类stats api获取这类数据)。 在一个规模很大的集群,这个状态信息可能会非常大的,耗用的内存空间就不可忽视了。并且在ES2.0之前的版本,state的更新是由master node做完以后全量散播到其他结点的。 频繁的状态更新都有可能给heap带来压力。 在超大规模集群的情况下,可以考虑分集群并通过tribe node连接做到对用户api的透明,这样可以保证每个集群里的state信息不会膨胀得过大。
超大搜索聚合结果集的fetch
ES是分布式搜索引擎,搜索和聚合计算除了在各个data node并行计算以外,还需要将结果返回给汇总节点进行汇总和排序后再返回。无论是搜索,还是聚合,如果返回结果的size设置过大,都会给heap造成很大的压力,特别是数据汇聚节点。超大的size多数情况下都是用户用例不对,比如本来是想计算cardinality,却用了terms aggregation + size:0这样的方式; 对大结果集做深度分页;一次性拉取全量数据等等。
小结:
1. 倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
2. 各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
3. 避免返回大量结果集的搜索与聚合。缺失需要大量拉取数据可以采用scan & scroll api来实现。
4. cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
5. 想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
原文来自:
http://elasticsearch.cn/article/32
作者介绍:
wood
主页是:http://elasticsearch.cn/people/wood
附录:
ES中文论坛:http://elasticsearch.cn/
这篇关于ElasticSearch 内存那点事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






