本文主要是介绍Linux 使用 yum安装 ELK服务,yum 安装elasticsearch和Kibana(未写完),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 环境准备
- ELK组件介绍
- 安装Elasticsearch
- 安装Kibana
- 丢弃
- 下载ELK 服务安装包
- Elasticsearch安装
- Tips:
- 关闭elasticsearch https
环境准备
ELK组件介绍
ElasticSearch : 是一个近实时(NRT)的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
Logstash: 它是一个具有近实时(NRT)传输能力的数据收集、过滤、分析引擎,用来进行数据收集、解析、过滤,并最终将数据发送给ES。
Kibana: 它是一个为 ElasticSearch 提供分析和展示的可视化 Web 平台。它可以在 ElasticSearch 的索引中查找,交互数据,并生成各种维度表格、图形以及仪表盘。
安装顺序为 Elasticsearch > Kibana > Logstash
安装Elasticsearch
下载并安装公共签名密钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
从 RPM 存储库安装
cat > /etc/yum.repos.d/elasticsearch.repo << EOF
[elasticsearch]
name=Elasticsearch repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
EOF
安装elasticsearch
yum install --enablerepo=elasticsearch elasticsearch
安装完成后显示下面片段,里面有 kibana 的 token 信息和 elastic 的账号密码,注意保存
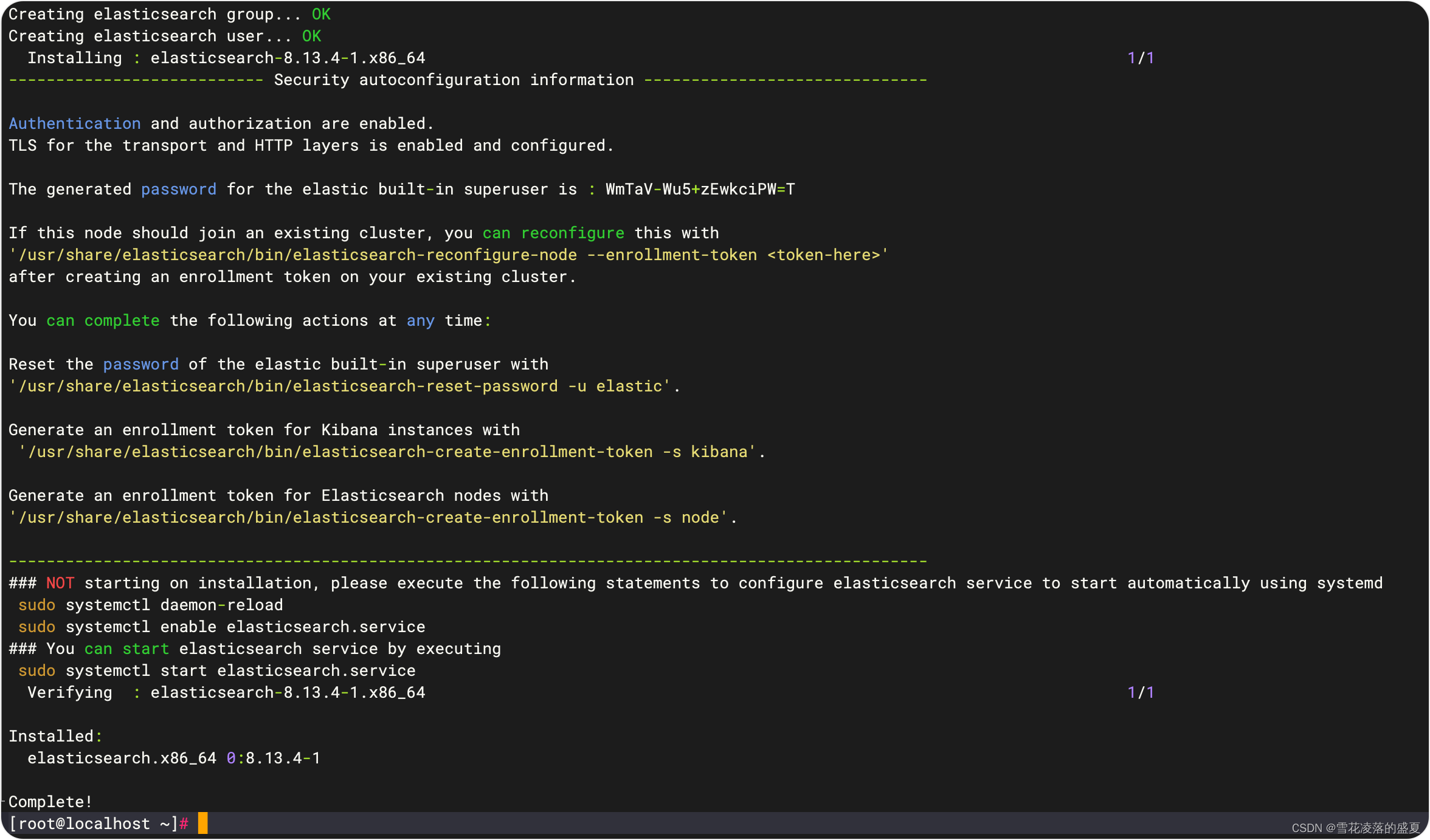
可随时执行的操作包括:
#重置elastic超级用户密码:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic# 为Kibana实例生成注册令牌:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana# 为Elasticsearch节点生成注册令牌:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
启动elasticsearch
# 设置为开机自启
systemctl enable elasticsearch.service# 启动elasticsearch
systemctl start elasticsearch.service
安装Kibana
下载并安装公共签名密钥
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
从 RPM 存储库安装
cat > /etc/yum.repos.d/kibana.repo << EOF
[kibana-8.x]
name=Kibana repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
安装Kibana
yum install kibana
修改vim /etc/kibana/kibana.yml配置文件,设置 IP 和端口

启动Kibana
# 设置为开机自启
systemctl enable kibana.service# 启动elasticsearch
systemctl start kibana.service
创建 kibana 的 token
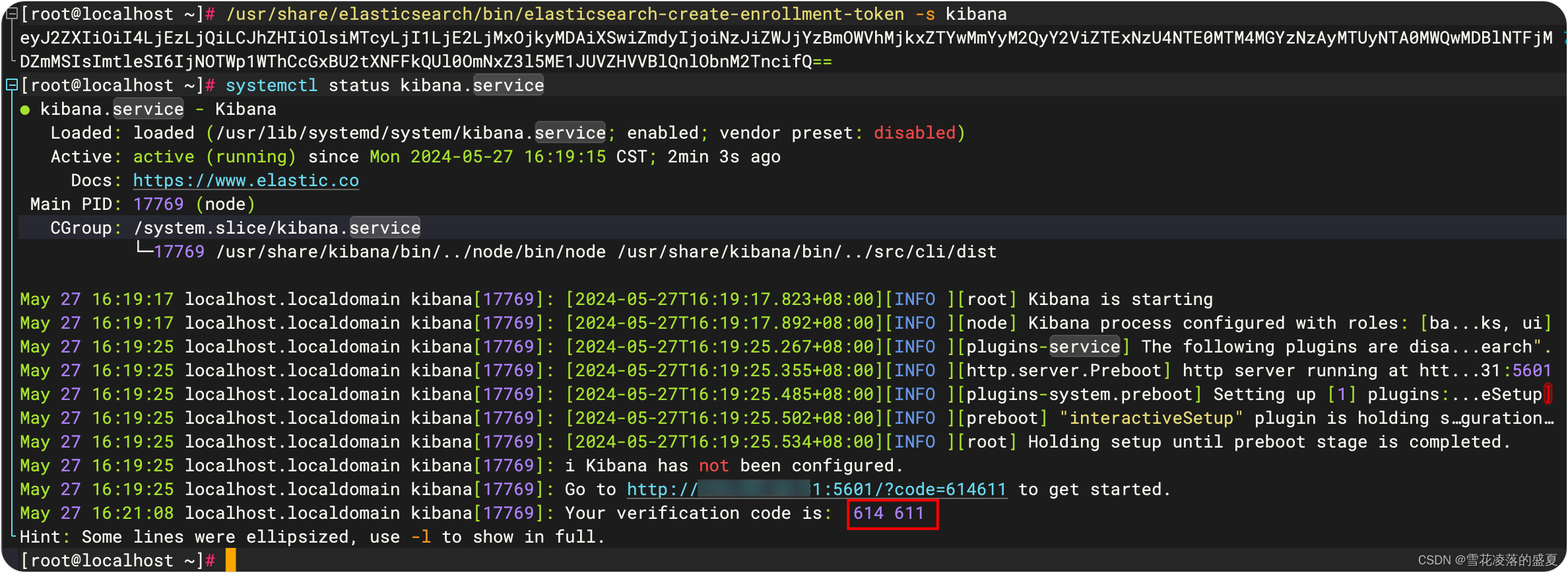
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
eyJ2ZXIiOiI4LjEzLjQiLCJhZHIiOlsiMTcyLjI1LjE2LjMxOjkyMDAiXSwiZmdyIjoiNzJiZWJjYzBmOWVhMjkxZTYwMmYyM2QyY2ViZTExNzU4NTE0MTM4MGYzNzAyMTUyNTA0MWQwMDBlNTFjMDZmMSIsImtleSI6IjNOTWp1WThCcGxBU2tXNFFkQUl0OmNxZ3l5ME1JUVZHVVBlQnlObnM2TncifQ==
使用浏览器打开 kibana 服务地址:http://172.25.16.31:5601,填入刚刚生成的 token,点击配置
此时需要验证码,使用systemctl status kibana.service查看kibana 验证码
登录到kibana,超级管理员账号为elastic,密码为前面安装elasticsearch生成的密码
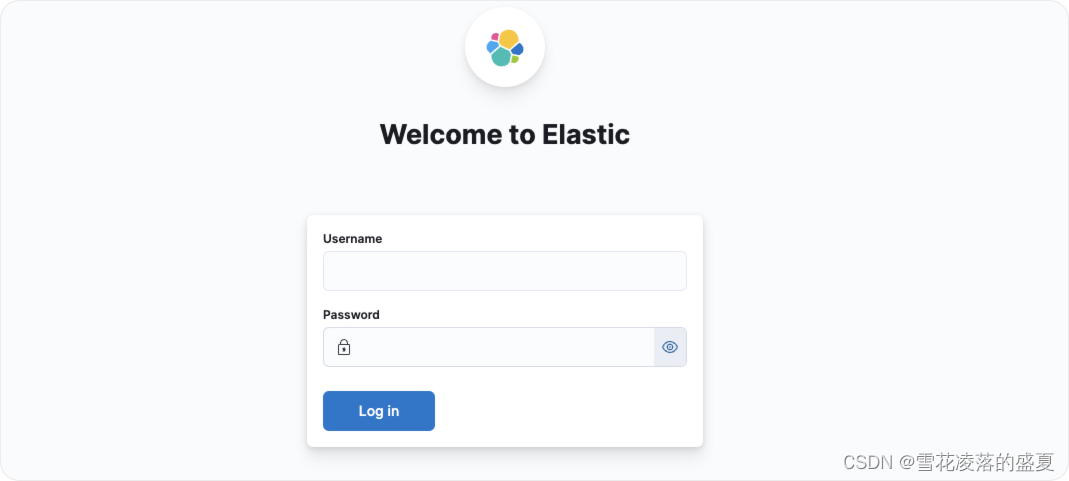
如果密码忘记了,可以使用/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic重置密码
参考文档:
官方文档 rpm 安装elasticsearch
丢弃
下载ELK 服务安装包
Elasticsearch:https://www.elastic.co/cn/downloads/kibana
Logstash:https://www.elastic.co/cn/downloads/kibana
Kibana:https://www.elastic.co/cn/downloads/kibana
我这里使用的是二进制安装包

Elasticsearch安装
# 解压
tar xvf elasticsearch-8.13.4-linux-x86_64.tar.gz# 添加用户
useradd es# 给于es 用户权限
chown es:es -R elasticsearch-8.13.4# 登录到es用户
su es# 启动es
./bin/elasticsearch
Tips:
关闭elasticsearch https
编辑elasticsearch.yml 文件,把 ture 改为 false

这篇关于Linux 使用 yum安装 ELK服务,yum 安装elasticsearch和Kibana(未写完)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





