本文主要是介绍【DevOps】Elasticsearch在Ubuntu 20.04上的安装与配置:详细指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、ES 简介
1、核心概念
2、工作原理
3、 优势
二、ES 在 Ubuntu 20.04 上的安装
1、安装 Java
2、下载 ES 安装包
3、创建 ES 用户
4 、解压安装包
5、 配置 ES
6、 启动 ES
7、验证安装
三、ES 常用命令
1、创建索引
2、 插入文档
3、查询文档
四、ES 配置详解
1、集群配置
2、节点配置
3、 索引配置
4、安全配置
五、ES 高级应用
1、集群管理
2、分片和副本
3、索引优化
4、数据分析
5、 安全管理
六、ES 学习资源
七、总结
八、ES 未来发展
九、建议
Elasticsearch (ES) 作为一款功能强大的开源搜索和分析引擎,在现代数据驱动的应用中扮演着不可或缺的角色。它凭借着高性能、可扩展性和丰富的功能,在搜索、日志分析、数据可视化等领域得到广泛应用。本文将带你深入了解 ES 的核心概念、工作原理,并详细介绍如何在 Ubuntu 20.04 上安装和配置 ES,帮助你快速掌握 ES 的精髓,并将其应用于你的项目中。
一、ES 简介
Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎,它提供了一种简单、高效的方式来存储、搜索和分析海量数据。ES 采用 RESTful API 进行操作,支持多种编程语言,并提供丰富的插件扩展功能。
1、核心概念
- 索引 (Index):类似于数据库中的表,用于存储特定类型的数据。
- 类型 (Type):在索引中用于区分不同类型的数据,例如文章、用户等。
- 文档 (Document):存储在索引中的单个数据项,类似于数据库中的行。
- 字段 (Field):文档中的单个属性,类似于数据库中的列。
- 集群 (Cluster):多个 ES 节点的集合,用于提高性能和容错性。
- 节点 (Node):集群中的单个 ES 实例,负责存储数据、处理请求等。
- 分片 (Shard):每个索引可以被划分为多个分片,用于提高性能和数据分布。
- 副本 (Replica):每个分片可以有多个副本,用于提高容错性和数据可用性。
2、工作原理
ES 采用倒排索引机制来实现快速搜索。当添加新文档时,ES 会将文档中的文本内容进行分词和索引,并将每个词语与其对应的文档 ID 存储在索引中。搜索时,ES 会根据用户输入的关键词,从索引中查找包含该关键词的文档 ID,并返回相关结果。
3、 优势
- 高性能:基于 Lucene 的倒排索引机制,可以快速搜索海量数据。
- 可扩展性:支持集群部署,可以轻松扩展到多个节点,满足高并发需求。
- 功能丰富:提供丰富的 API 和插件,支持多种搜索功能和数据分析功能。
- 开源免费:完全免费使用,并拥有庞大的社区支持。
二、ES 在 Ubuntu 20.04 上的安装
1、安装 Java
ES 依赖于 Java 运行环境,需要先安装 Java。
sudo apt update
sudo apt install default-jre
2、下载 ES 安装包
从 Elasticsearch 官方网站 Download Elasticsearch | Elastic 下载与操作系统匹配的安装包。
3、创建 ES 用户
为了更安全地运行 ES,建议创建一个专门的用户来运行 ES 服务。
sudo useradd -M -s /bin/bash elasticsearch
4 、解压安装包
将下载的安装包解压到指定的目录。
sudo tar -xzf elasticsearch-7.17.3.tar.gz -C /opt/
sudo chown -R elasticsearch:elasticsearch /opt/elasticsearch-7.17.3
5、 配置 ES
-
修改配置文件:编辑
config/elasticsearch.yml文件,根据需要修改配置项,例如节点名称、集群名称、数据存储路径等。- 节点名称:
node.name: 设置节点的唯一标识符。 - 集群名称:
cluster.name: 设置集群的名称。 - 数据存储路径:
path.data: 设置数据存储目录。 - 日志存储路径:
path.logs: 设置日志存储目录。 - 网络配置:
network.host: 设置 ES 监听的 IP 地址。
node.name: es-node-1 cluster.name: my-elasticsearch-cluster path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 - 节点名称:
-
配置 Java 环境变量:编辑
bin/elasticsearch.env文件,设置 Java 环境变量。export JAVA_HOME=/usr/lib/jvm/default-java
6、 启动 ES
在 ES 安装目录下运行 bin/elasticsearch 命令启动 ES。
sudo -u elasticsearch /opt/elasticsearch-7.17.3/bin/elasticsearch
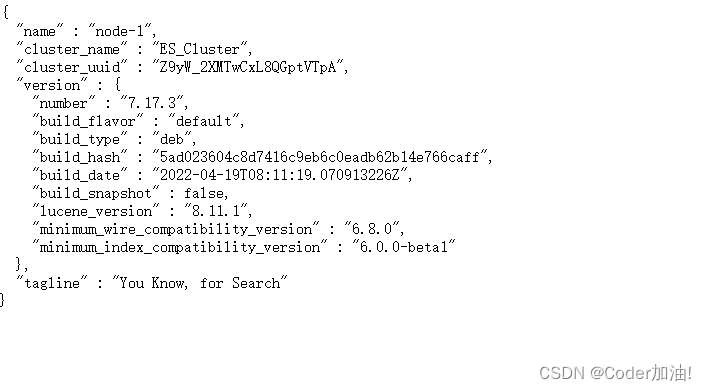
7、验证安装
访问 http://localhost:9200,如果返回 ES 版本信息,则表示安装成功。
三、ES 常用命令
1、创建索引
curl -XPUT http://localhost:9200/my_index -H 'Content-Type: application/json' -d'
{"settings": {"number_of_shards": 5,"number_of_replicas": 1}
}
'
2、 插入文档
curl -XPOST http://localhost:9200/my_index/my_type -H 'Content-Type: application/json' -d'
{"title": "My first document","content": "This is the content of my first document."
}
'
3、查询文档
curl -XGET http://localhost:9200/my_index/my_type/_search -H 'Content-Type: application/json' -d'
{"query": {"match": {"title": "first"}}
}
'
4、 删除索引
curl -XDELETE http://localhost:9200/my_index
5、删除文档
curl -XDELETE http://localhost:9200/my_index/my_type/1
四、ES 配置详解
1、集群配置
- cluster.name: 设置集群的名称,所有节点的集群名称必须一致。
- discovery.zen.minimum_master_nodes: 设置成为主节点的最低数量,默认值为 1。
- discovery.zen.ping.unicast.hosts: 设置节点发现机制,默认值为 127.0.0.1。
2、节点配置
- node.name: 设置节点的唯一标识符。
- node.master: 设置节点是否可以成为主节点,默认值为 true。
- node.data: 设置节点是否可以存储数据,默认值为 true。
3、 索引配置
- index.number_of_shards: 设置每个索引的分片数量,默认值为 5。
- index.number_of_replicas: 设置每个分片副本的数量,默认值为 1。
- index.refresh_interval: 设置索引刷新的频率,默认值为 1 秒。
4、安全配置
- xpack.security.enabled: 设置安全功能是否启用,默认值为 false。
- xpack.security.authc.realms.file.order: 设置认证方式,默认值为 1。
- xpack.security.transport.ssl.enabled: 设置 TLS/SSL 是否启用,默认值为 false。
五、ES 高级应用
1、集群管理
ES 支持集群部署,可以将多个节点组成一个集群,提高性能和容错性。
2、分片和副本
ES 可以将索引划分为多个分片,并为每个分片创建多个副本,提高性能和数据可用性。
3、索引优化
可以通过调整索引配置、分词器等方式优化索引性能。
4、数据分析
ES 提供丰富的分析功能,可以进行聚合、统计、趋势分析等操作。
5、 安全管理
ES 支持用户认证、访问控制等安全功能,确保数据安全。
六、ES 学习资源
- 官方网站:Elastic — The Search AI Company | Elastic
- 官方文档:Elasticsearch Guide [8.13] | Elastic
- 社区论坛:Discuss the Elastic Stack - Official ELK / Elastic Stack, Elasticsearch, Logstash, Kibana, Beats and more forums
- GitHub 仓库:GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine
七、总结
ES 是一款强大的搜索和分析引擎,它拥有丰富的功能和广泛的应用场景。本文介绍了 ES 的核心概念、工作原理以及在 Ubuntu 20.04 上的安装和配置方法,希望能帮助你快速上手 ES,并将其应用于你的项目中。
八、ES 未来发展
ES 作为一款快速发展的技术,未来将会继续不断改进和创新,例如:
- 更高性能:不断优化内核,提高搜索和分析速度。
- 更强大功能:增加更多分析功能和插件,满足更多场景需求。
- 更易用性:简化操作流程,降低使用门槛。
- 更安全可靠:提高安全性,增强数据可靠性。
九、建议
- 建议使用专门的用户来运行 ES,提高安全性。
- 建议根据实际需求调整 ES 的配置,以获得最佳性能。
- 建议学习 ES 的 API,使用代码进行操作,提高效率。
- 建议关注 ES 的官方文档和社区论坛,了解最新信息和最佳实践。
希望本文能够帮助你快速入门 ES,并将其应用于你的项目中。
这篇关于【DevOps】Elasticsearch在Ubuntu 20.04上的安装与配置:详细指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







