本文主要是介绍C语言实现Hash Map(3):Map代码优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在上一节中,我们学习了C语言实现Hash Map(2):Map代码实现详解,通过代码,我们更深入地了解了Map实现的原理,学习了如何通过key找到对应的桶并加入节点。也正如上一节提到的,虽然这是github中star比较多的代码,但是程序还可以进一步地优化:
- 程序桶的数量是在每次添加节点的时候自动调节的,即使用realloc函数重新分配
- 可以固定一下默认的桶的大小,而不是每次都从0开始网上分配
- 假设使用FreeRTOS,并没有realloc函数,所以将其改为动态分配和释放
- 程序仅支持值为
char *类型的映射,且值的数据是拷贝的- 支持不同数据类型的键
- 支持拷贝值和保存值的指针两种方式
文章目录
- 1 桶的默认大小
- 2 桶的内存分配
- 3 支持不同的数据类型
- 3.1 数据结构修改
- 3.2 map_init
- 3.3 map_set
- 3.4 map_get
- 4 测试
- 5 总结
1 桶的默认大小
首先来解决桶内存的问题。由上一节我们知道,在每次增加节点的时候,若当前节点的数量大于等于桶的数量,则会使用realloc重新分配桶内存。但这样的话,最开始从0开始,随着节点的增加,分配1、 2、 4、 8个桶,未免有点太麻烦了,也可能会产生一些内存碎片。所以我们希望在初始化的时候,就初始化固定的桶。
所以解决办法很简单,我们直接在初始化函数中传入一个默认的桶数量的参数,然后调用map_resize即可。
void map_init(unsigned int nbuckets)
{...assert((nbuckets % 2) == 0);map_resize(&base, nbuckets);
}
由上节课可知,map_bucketidx函数中使用的是按位与来获取余数,所以这里的nbuckets的值应为2的倍数,所以这里断言判断一下。
2 桶的内存分配
另外,在map_resize函数中使用的是stdlib.h库中的realloc函数,我们就在分配之前释放上一次分配的,然后使用MAP_MALLOC分配就行了。如下图所示:
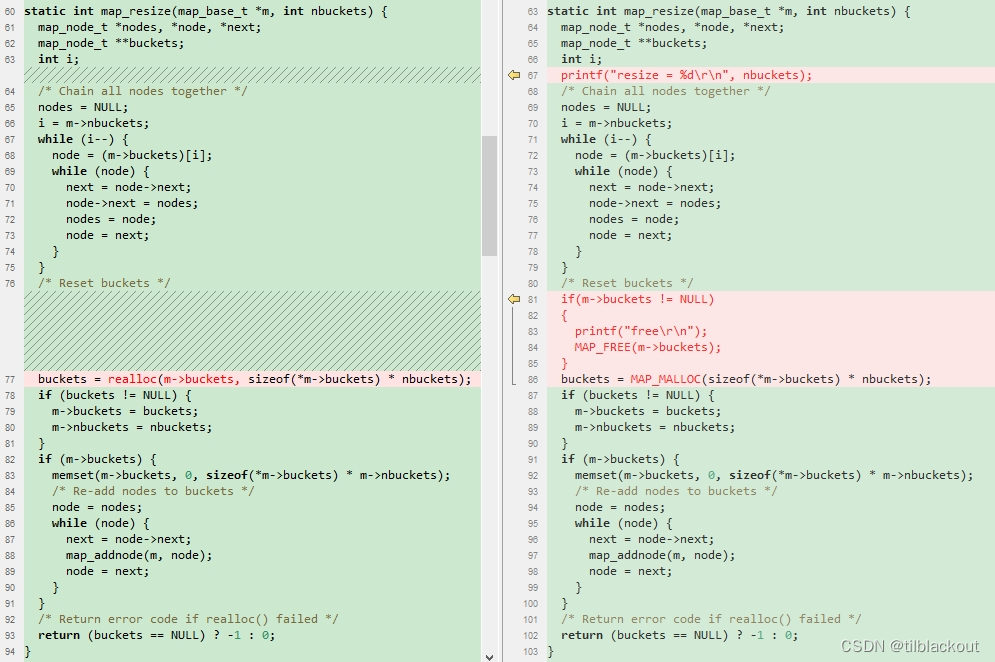
由于我们设置了桶的默认大小,我们可以根据实际情况调整桶的大小,只要不超过这个大小,就不会调用到map_resize函数。
3 支持不同的数据类型
从代码中可以看出:
int map_set_(map_base_t *m, const char *key, void *value, int vsize)
{...memcpy((*next)->value, value, vsize);...
}
value传入的是一个指针,然后函数中使用memcpy拷贝的是指针指向地址里面的值。所以这种情况就导致我们map的值只能使用字符串或定义一个变量并传入地址。假设我们希望值为int类型,然后直接写入数值就不允许了。另外,有的时候我们又希望这个函数不要拷贝函数的内容,比如我们的值传入的就是常量字符串,那我们在函数中还又拷贝一次,这样浪费了内存。所以我们就来更改一下这部分的代码,让它既支持拷贝参数内容,又支持保存参数的地址。
3.1 数据结构修改
首先我们回顾一下之前的数据结构:
typedef map_t(void*) map_void_t;
typedef map_t(char*) map_str_t;
typedef map_t(int) map_int_t;
typedef map_t(char) map_char_t;
typedef map_t(float) map_float_t;
typedef map_t(double) map_double_t;
其中map_t为:
#define map_t(T)\struct { map_base_t base; T ref;}
我们知道,map实际的数据结构就是map_base_t,而这个T ref就是标记不同数据类型的唯一地方了。而且ref变量仅在下面用到:
#define map_get(m, key)\( (m)->ref = map_get_(&(m)->base, key) )
也就是获取键值的是保存在这个变量中,但很明显,假设类型为int,map_get_却返回的是一个指针,类型明显不符。另外将结果保存在ref中似乎也没什么意义。所以我们直接删除ref这个变量,和所有的类型的typedef,直接typedef整个结构体就行了。
为了能够区别不同数据类型的长度,我们增加两个变量,typeSize表示数据类型的大小,isCpyAddr表示设置键值的时候是拷贝地址里的值(isCpyAddr=1),还是直接传入值给函数(拷贝参数,isCpyAddr=0)。然后将整个数据结构命名为map_c_t:
typedef struct{map_base_t base;unsigned char typeSize;unsigned char isCpyAddr;
}map_c_t;
接下来我们就改下面三个函数:map_init、map_set和map_get,删掉宏定义的map_set和map_get。
- 对于其它几个宏定义和函数,如
map_remove、map_deinit等,自行更改一下,主要是将函数参数map_base_t修改为map_c_t即可。
3.2 map_init
原来的map_init是一个宏定义,然后用memset将整个map数据结构置0,现在我们将其改为函数。对于不同的数据类型,我们声明一个枚举类型供用户选择传参:
typedef enum{MAP_TYPE_VOID_PTR, //void *MAP_TYPE_CHAR_PTR, //char *MAP_TYPE_INT, //intMAP_TYPE_CHAR, //charMAP_TYPE_FLOAT, //floatMAP_TYPE_DOUBLE, //double
}MAP_TYPE;
然后map_init函数如下:
void map_init(map_c_t *instance, MAP_TYPE type, unsigned char isCpyAddr, unsigned int nbuckets)
{memset(instance, 0, sizeof(map_c_t));switch(type){case MAP_TYPE_VOID_PTR:{instance->typeSize = sizeof(void *);break;}case MAP_TYPE_CHAR_PTR:{instance->typeSize = sizeof(char *);break;}case MAP_TYPE_INT :{instance->typeSize = sizeof(int);break;}case MAP_TYPE_CHAR :{instance->typeSize = sizeof(char);break;}case MAP_TYPE_FLOAT :{instance->typeSize = sizeof(float);break;}case MAP_TYPE_DOUBLE :{instance->typeSize = sizeof(double);break;}default:break;}instance->isCpyAddr = isCpyAddr; //拷贝地址里的内容assert((nbuckets % 2) == 0);map_resize(&instance->base, nbuckets);
}
- 根据枚举类型保存数据的
typeSize,这样比如在用户传入数字的时候,就知道拷贝多大的数据。 isCpyAddr保存是否需要拷贝地址里的内容- 最后根据设置的桶的初始大小来分配内存
3.3 map_set
我们直接来看一下代码前后的对比:
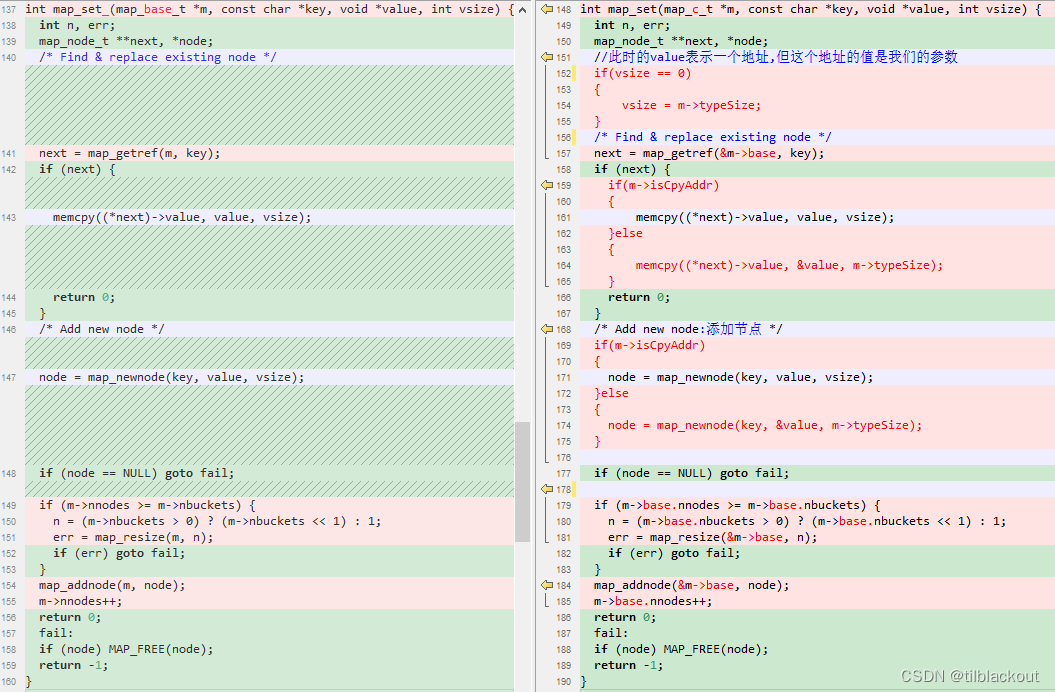
- 首先将原来的
map_base_t改为我们定义的map_c_t,然后更改下面所有用到base的地方 - 这里
vsize为我们传入的参数的大小,如果参数为字符串且我们用的是拷贝方式的话,我们需要传入vsize的大小,这样用户传入字符串的时候,我们就知道拷贝多大的长度。在其它时候,vsize可以传0,vsize就设置为数据类型对应的typeSize。 - 最后就是根据
isCpyAddr来判断是拷贝地址里的值还是拷贝地址,分别在节点已经存在时和创建节点时修改代码。
这里举一个例子,如果我们设置的是MAP_TYPE_INT,然后传入的值是123,那么这个void *类型的value的值就是123,如果直接用memcpy拷贝的话,就拷贝的是123这个地址里的值;所以传入123的时候我们就拷贝value的地址&value就行了。
3.4 map_get
map_get函数不需要做太大的改动,只要把参数改成我们定义的map_c_t,然后把map_getref中的参数改成&m->base就行了。
void *map_get(map_c_t *m, const char *key) {map_node_t **next = map_getref(&m->base, key);return next ? (*next)->value : NULL;
}
4 测试
这里我把各个类型的使用都写了一个例子,只需要更改TEST_MODE宏定义即可:
#include <stdio.h>
#include <stdlib.h>
#include "map.h"#define TEST_MODE 1static map_c_t langMap;
int main()
{
#if (TEST_MODE == 1) //字符串测试:拷贝字符串地址[常用]map_init(&langMap, MAP_TYPE_CHAR_PTR, 0, 8);map_set(&langMap, "test", "1234", 0);char **ret = map_get(&langMap, "test");printf("%x %x = %s\r\n", "1234", *ret, *ret);
#elif (TEST_MODE == 2) //字符串测试:拷贝字符串的值map_node_t后面的内存中(需要指定长度)map_init(&langMap, MAP_TYPE_CHAR_PTR, 1, 8);map_set(&langMap, "test", "1234", sizeof("1234"));char *ret = map_get(&langMap, "test");printf("%x %x = %s\r\n", "1234", ret, ret);
#elif (TEST_MODE == 3) //int测试:保存数字的值到map_node_t后[常用]map_init(&langMap, MAP_TYPE_INT, 0, 8);map_set(&langMap, "test", 123, 0);int *ret = map_get(&langMap, "test");printf("%x = %d\r\n", *ret, *ret);
#elif (TEST_MODE == 4) //int测试:拷贝int变量的值到map_node_t后const int a = 123;map_init(&langMap, MAP_TYPE_INT, 1, 8);map_set(&langMap, "test", &a, 0);int *ret = map_get(&langMap, "test");printf("%x %x = %d\r\n", &a, *ret, *ret);
#elif (TEST_MODE == 5) //int测试:保存int变量的地址const int a = 123;map_init(&langMap, MAP_TYPE_INT, 0, 8);map_set(&langMap, "test", &a, 0);int **ret = map_get(&langMap, "test");printf("%x %x = %d\r\n", &a, *ret, **ret);
#elif (TEST_MODE == 6) //char测试:拷贝字符的值到map_node_t后[常用]map_init(&langMap, MAP_TYPE_CHAR, 0, 8);map_set(&langMap, "test", 'a', 0);char *ret = map_get(&langMap, "test");printf("%x = %c\r\n", *ret, *ret);
#elif (TEST_MODE == 7) //double测试:保存double变量地址到map_node_t后const double a = 3.14;map_init(&langMap, MAP_TYPE_DOUBLE, 0, 8);map_set(&langMap, "test", &a, 0);double **ret = map_get(&langMap, "test");printf("%x %x = %lf\r\n", &a, *ret, **ret);
#elif (TEST_MODE == 8) //double测试:拷贝double变量的值到map_node_t后const double a = 3.14;map_init(&langMap, MAP_TYPE_DOUBLE, 1, 8);map_set(&langMap, "test", &a, 0);double *ret = map_get(&langMap, "test");printf("%x %x = %lf\r\n", &a, ret, *ret);
#else//1.float类型:代码同double//2.void *类型:这种情况一般是保存地址,所以map_init最后一个参数为0
#endifreturn 0;
}
这里来展示一下int作为值类型,传入数值时的演示结果:
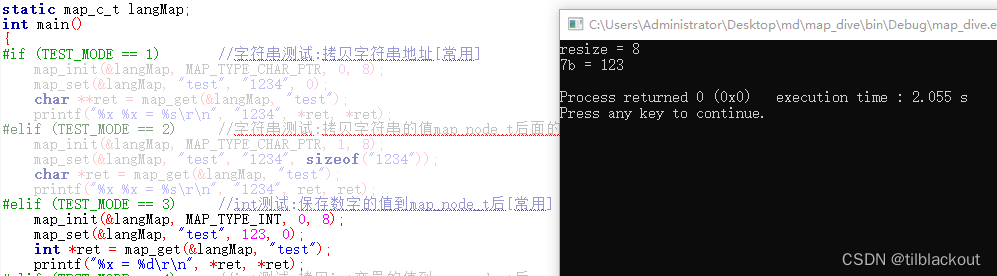
可以看到,输出符合预期,0x7b是创建map_node_t节点时分配的内存地址里value的地址。
5 总结
本文基于Github上给的代码进行了一些小小的优化,使其可以适配不同的数据类型,并能够初始分配一个桶的内存。但正如前面所说,代码并没有完整做完适配,如map_deinit等函数还需要小小修改一下。大家可以自行修改,或者大家还有什么优化的建议都可以在我下面的git仓库中进行提交。
- 完整代码:https://github.com/Vinolzy/map_fix
这篇关于C语言实现Hash Map(3):Map代码优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






