本文主要是介绍多文件和静态/动态链接以及虚拟内存管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多目标文件链接
//stack.c
char stack[512];
int top =-1;
void push(char c){stack[++top] = c;
}char pop(void){return stack[top--];
}int is_empty(void){return top == 1;
}// main.c
#include <stdio.h>
int a,b = 1;
int main(){
push('a');
push('b');
push('c');
while(!is_empty())putchar(pop());putchar('\n');return 0;
}
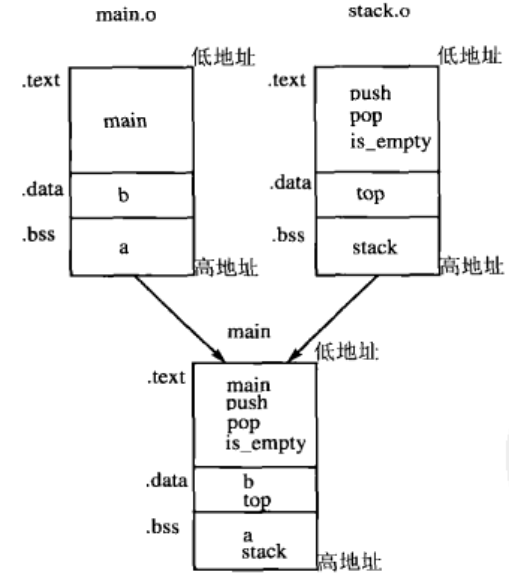
通过 readelf -a main命令可以看到
- main的.bss段合并了 main.o和stack.o的.bss段,包含了变量a和stack;
- main的.data段合并了main.o和 stack.o的.data段,其中包含了变量b和top;
- main的.text段合并了main.o和 stack.o的.text段
PS: GDB如何调试多个文件的code
//main.c 和 stack.c
(gdb)list stack.c:1
(gdb)b stack.c:10
定义和声明
extern和static
- 用extern声明的函数名具有external linkage
- 用static声明的函数名具有internal linkage
- 函数默认是extern的
凡是被多次声明的变量或函数,必须有且只有一个声明是定义,如果有多个定义,或者一个定义都没有,链接器就无法完成链接。
变量声明和函数声明有一点不同,函数声明的 extern关键字可以省略,而变量声明如果不写 extern意思就完全变了
用 static关键字声明具有 Internal Linkage,保护了函数的内部状态,是一种封装
头文件
通过宏定义避免硬编码
//stack.h
#ifdef STACK_H
#define STACK_H void push(char); char pop(void); int is_empty(void);
#endif//main.c
#include "stack.h"
对于用角括号包含的头文件**,gcc首先查找**-I**选项指定的目录,然后查找系统的头文件目录);
而对于用引号包含的头文件**,gcc首先查找包含这个头文件的当前文件所在的目录,然后查找**-I选项指定的目录,然后查找系统的头文件目录
则可以用gcc- c maln.c编译,gcc会自动在main.C所在的目录中找到stack. h。假如把 stack.h移到一个子目录下
则需要用gcc- c main.c -Istack编译,用-I选项告诉gcc头文件要到子目录 stack里找
在#include预处理指示中可以使用相对路径,例如把上面的代码改成#include “stack/stack,h”,那么编译时就不需要加-Istack选项了,因为是main.c要包含头文件,gcc会自动在main.c所在的目录中查找,而头文件相对于main.c所在目录的相对路径正是 stack/ stack.h
PS:gcc -E可以产生预编译文件
避免头文件被重复包含的方法为header guard
写.C文件和头文件时一般来说应遵循以下原则:
- C文件中可以有变量或函数定义,而.h文件中应该只有变量或函数声明而没有定义。
- 不要把一个C文件包含到另一个C文件中。
静态库
把一组代码编译成一个库,很多项目中复用
例如将stack.c文件拆分为四个文件,main.c保持不变
gcc -c stakc/stack.c stack/push.c stack/pop.c stack/is_empty.c
ar rs libstack.a stack.o push.o pop.o is_empty.o
# r表示将文件打包进libstack.a中,s表示为静态链接库
# 等价于
ar r libstack.a stack.o push.o pop.o is_empty.o
ranlib libstack.a
# 链接libstack.a main.c
gcc mian.c -L. -lstack -Istack -o main
-L选项告诉编译器去哪里找需要的库文件,L.表示在当前目录找。-lstack选项告诉编译器要链接 libstack库,-I选项告诉编译器去哪里找头文件
编译器默认会找哪些目录,用-print-search-dirs选项查看一下
gcc -print-search-dirs
在处理-lstack选项时,gcc首先到-L选项指定的目录下查找,看有没有共享库Iibstack.so,如果有就链接它,否则再找有没有静态库 Iibstack,a,如果有就链接它,如果还是没有,就到默认搜索路径下按同样的步骤查找。
gcc在链接时优先考虑共享库,其次才是静态库,如果希望gcc只考虑静态库,可以指定-static选项。
main.c只调用了push这一个函数,所以链接生成的可执行文件中也只有push而没有pop和 is_empty。链接器从静态库中只取出需要的目标文件来做链接,不需要的目标文件可以不链接
共享库
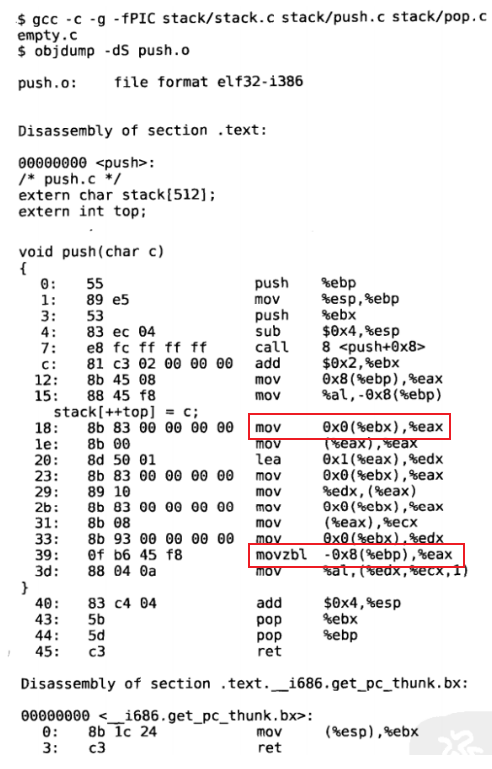
组成共享库的目标文件和一般的目标文件有所不同,在编译时要加-fPIC选项,即位置无关编码
gcc -c -fPIC stakc/stack.c stack/push.c stack/pop.c stack/is_empty.c
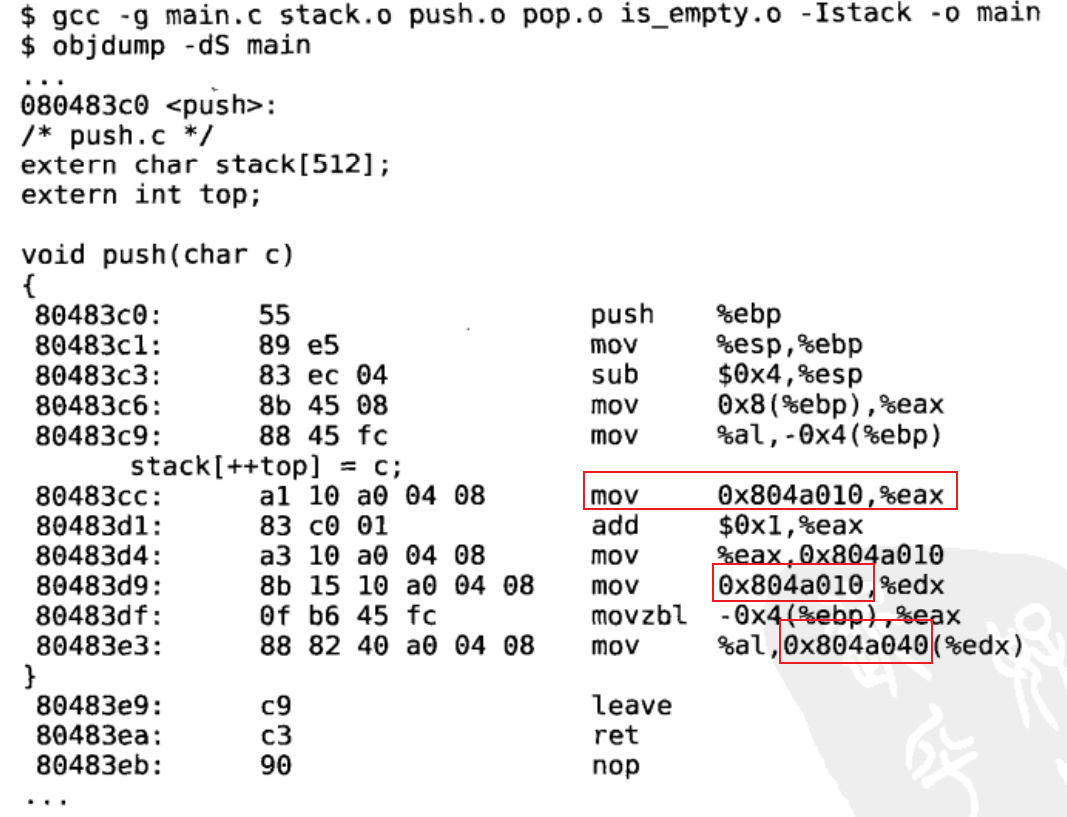
指令中凡是用到stack和top变量的地址都用0x0表示,以备在重定位时修改。
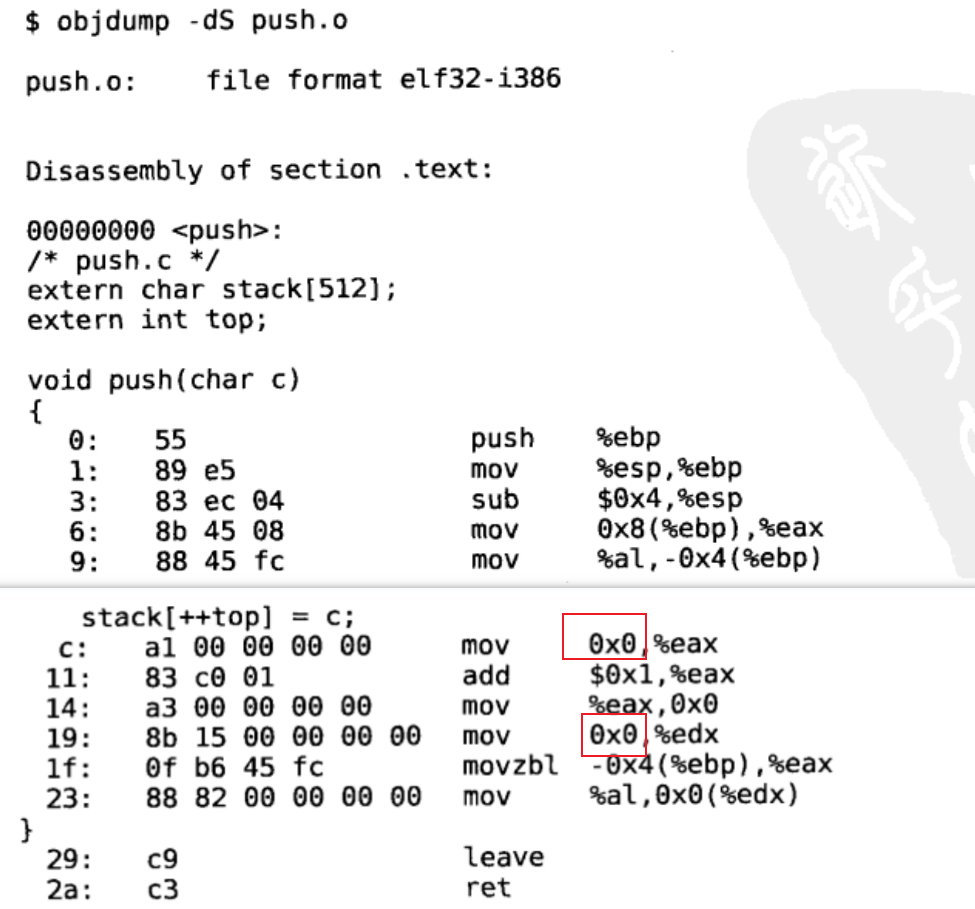
原来指令中的0x0被改成了0x804a010和0x804a040,这样做了重定位之后,各段的加载地址就定死了,因为在指令中使用了绝对地址
和先前的结果不同,指令中的0x0(%ebx)被修改成-0xc(ebx)和-0x8(%ebx),而不是修改成绝对地址。所以共享库各段的加载地址并没有定死,可以加载到任意位置。因为指令中的地址都是相对于ebx的,没有使用绝对地址,只要根据实际的加载情况修改ebx就可以了,这就是位置无关代码的特点.
对比前后的指令差异
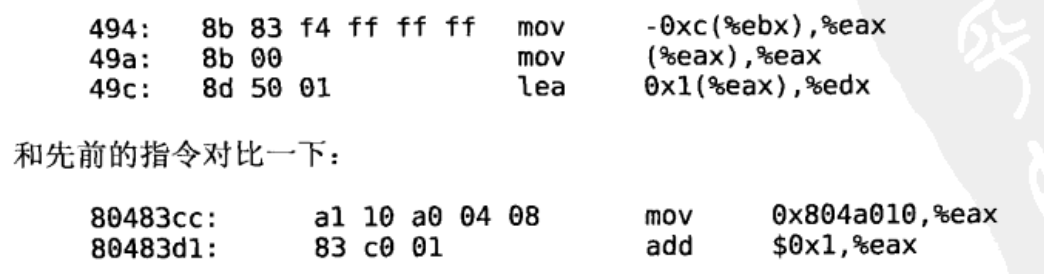
-0xc(%ebx)这个地址并不是变量top的地址,这个地址的内存单元中又保存了另外一个地址,而它才是变量top的地址。指令mov -0xc(%ebx),%eax是从地址ebx-12取出变量top的地址传给eax,而指令mov (%eax),%eax才是从top的地址取出top的值传给eax。指令lea 0x1(%eax),%edx是把top的值加1存到edx中。lea指令算出第一个操作数所代表的地址,但并不访问内存,而是直接把这个地址传给第二个操作数。我们知道x86的内存寻址方式涉及加法和乘法运算,lea指令只是利用寻址电路做加法和乘法运算,而不是真的寻址,
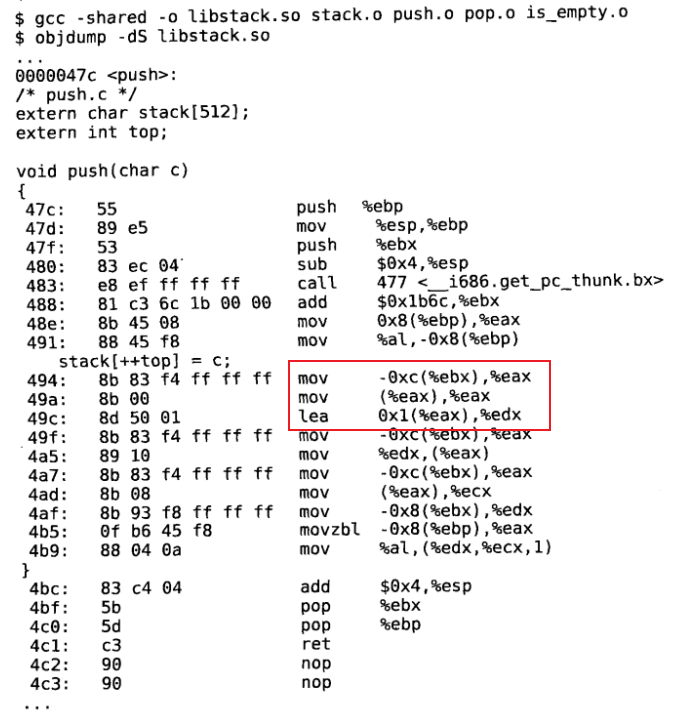
将main.c文件和共享库链接

用Ldd命令査看可执行文件依赖于哪些共享库:

动态链接器在那些目录搜索共享库?
- 首先在环境变量LD_ LIBRARY_PATH保存的路径中查找
- 然后从缓存文件/etc/ld.so. cache中查找这个缓存文件是由 ldconfig命令读取配置文件/etc/ld.so.conf生成的
- 如果上述步骤都找不到,则到默认的系统库文件目录中查找,先是/usr/ib然后是/Lib。
最常用的方法。把lsibtack.so所在目录的绝对路径(比如/home/ akaedu/somedir)添加到配置文件/etc/ld.so.conf(该文件中每个路径占一行),然后运行ldconfig命令:
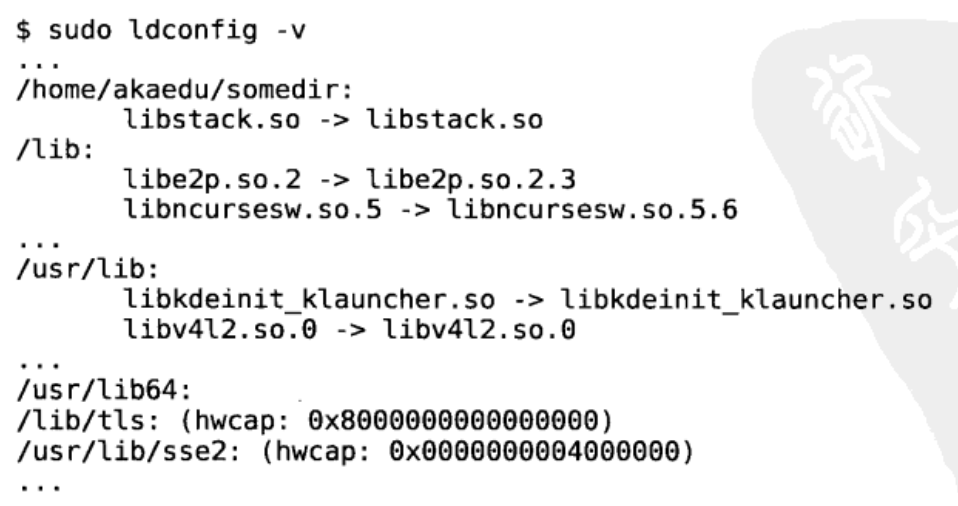
再查看动态库

函数的动态链接
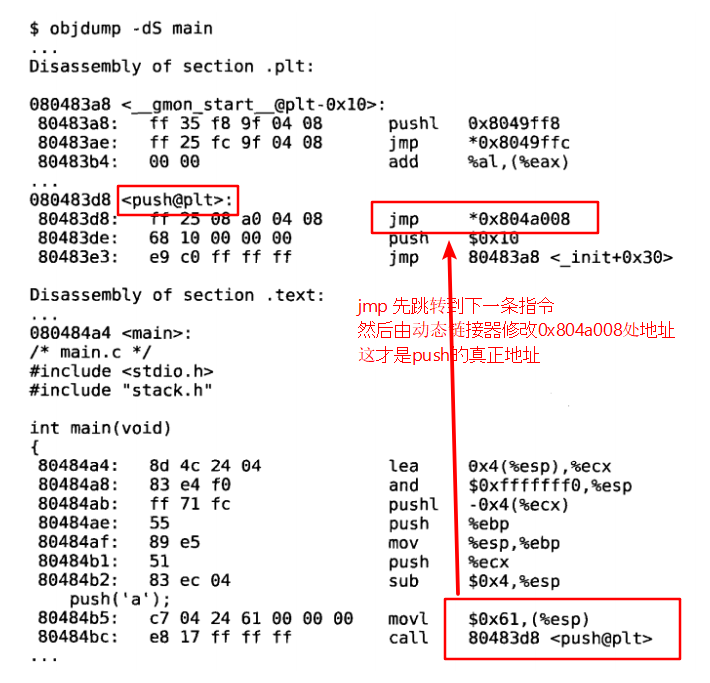
和链接静态库的情况不同,push函数的指令没有链接到可执行文件中,而且call 86483d8-push@pLt>这条指令调用的也不是push函数的地址,而是plt段里的地址。PLT是 Procedure Linkage Table的缩写,.plt段里保存的也是指令,和.text一起合并到 Text Segment
共享库命名
按照共享库的命名惯例,每个共享库有三个文件名:real name、 soname和 linker name。
真正的库文件(而不是符号链接)的名字是 real name,包含完整的共享库版本号,例如上面的 libcap.so.1.10、libc-2.8.90.so等
soname是符号链接的名字,只包含共享库的主版本号
但对于依赖libcap.So.1的程序来说,真正的库文件不管是 Libcap.S0.1.16还是Libcap.so.1.11都可以用,所以使用共享库可以很方便地升级库文件而不需要重新编译程序,这是静态库所没有的优点。注意libc的版本编号有一点特殊,libc-2.8.90.s0的主版本号是6而不是2或28
linker name仅在编译链接时使用,gcc的-L选项应该指定 linker name所在的目录。有的 linker name是库文件的一个符号链接,有的 linker name是一段链接脚本。
虚拟内存管理
ps //查看进程
cat /porc/29977/maps //查看进程地址空间
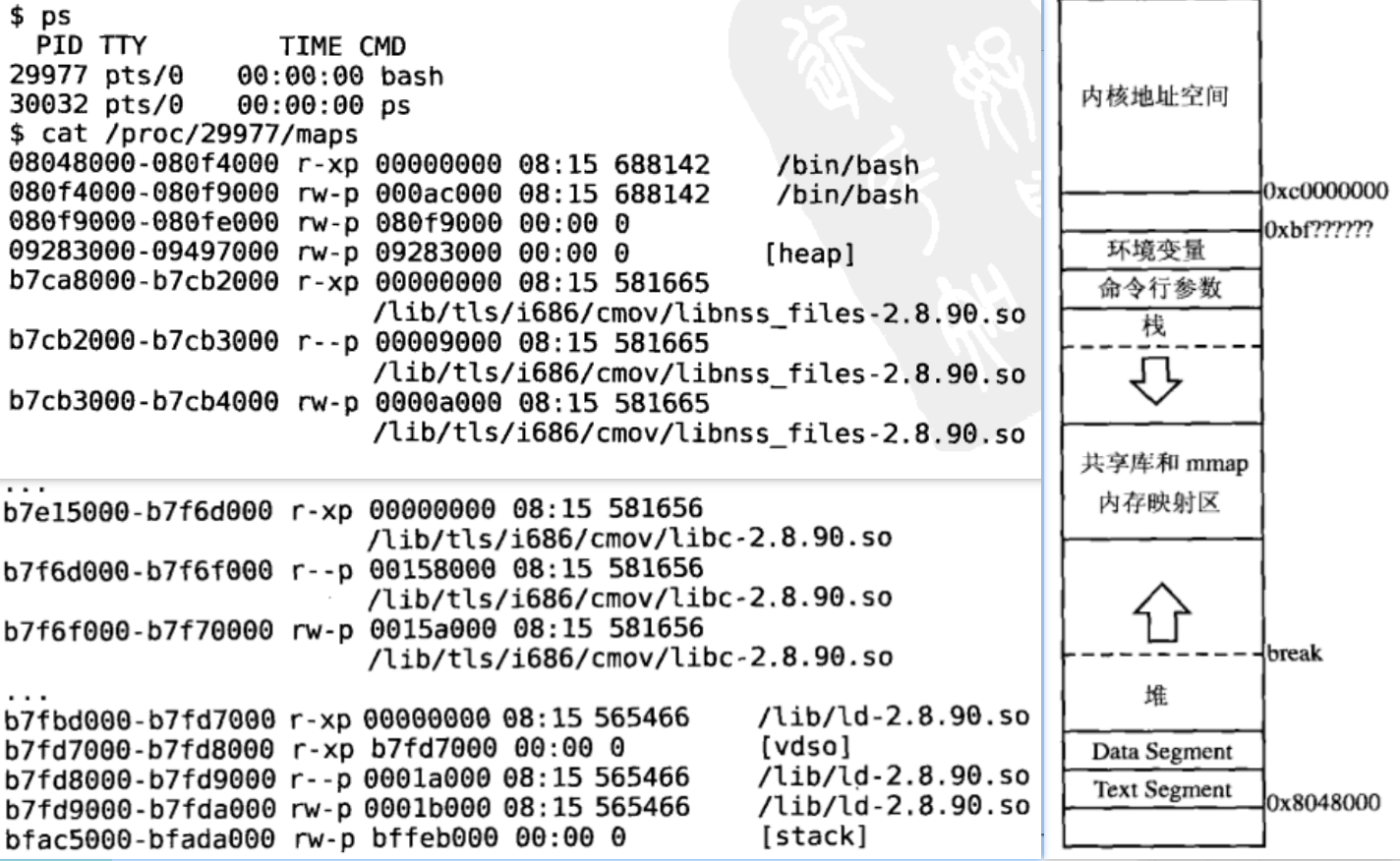
堆空间的地址上限(0x09497000)称为 Break,堆空间要向高地址增长就要抬高 Break,映射新的虚拟内存页面到物理内存,这是通过系统调用brk实现的, malloc函数也是调用brk向内核请求分配内存的。
操作系统虚拟内存控制机制的作用
(1)可以控制物理内存的访问权限。
物理内存本身是不限制访问的,任何地址都可以读写,而操作系统要求不同的页面具有不同的访问权限,这是利用CPU模式和MMU的内存保护机制实现的。错误的指令或恶意代码的破坏能力受到了限制,最多使当前进程因段错误而终止,不会影响到整个系统的稳定性。
(2)使每个进程有独立的地址空间。
不同进程中相同的VA被MMU映射到不同的PA,因此在某一个进程中访问任何虚拟地址都不可能访问到属于另外一个进程的物理内存页面,并且每个进程都认为自己独占0x0000000 xbffffffff 整个用户地址空间。独立地址空间的好处是:任何一个进程由于执行了错误指令或恶意代码而导致的非法内存访问都不会意外改写其他进程的数据,也不会影响其他进程的运行;链接器和加载器的实现也比较容易,不必考虑各进程的地址范围是否冲突。
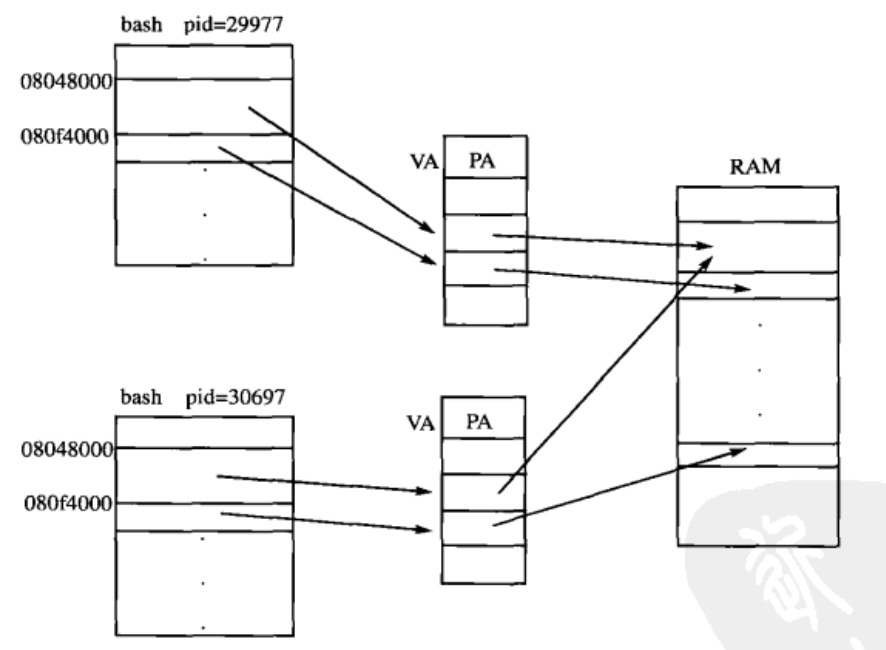
两个进程都是bash进程, Text Segment是一样的,并且 Text Segment是只读的,不会被改写,因此操作系统安排两个进程的TextSegment共享相同的物理页面。由于每个进程都有自己的一套VA到PA的映射表,在一个进程中通过VA只能访问到属于自己的物理页面,而不会访问到其他进程的物理页面。
(3)VA到PA的映射会给分配和释放内存带来方便
物理地址不连续的几块内存可以映射成虚拟地址连续的一块内存。比如要用 malloc分配一块很大的内存空间,虽然有足够多的空闲物理内存,却没有足够大的连续空闲内存,这时就可以分配多个不连续的物理页面而映射到连续的虚拟地址范围。
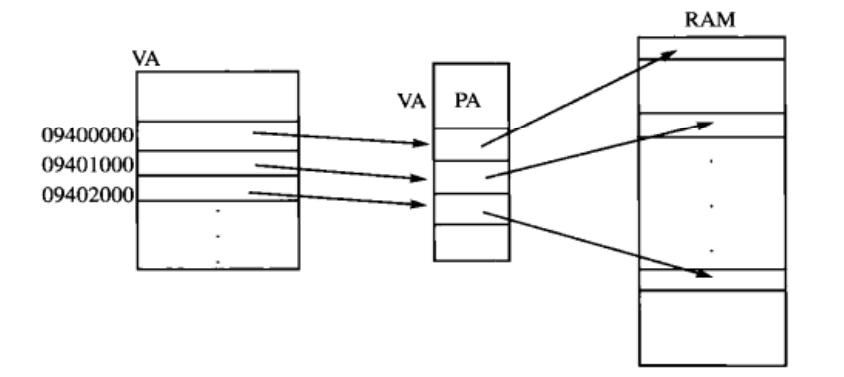
(4)一个系统如果同时运行着很多进程,为各进程分配的内存之和可能会大于实际可用的物理内存,虚拟内存管理机制使这种情况下各进程仍然能够正常运行。
进程访问的是虚拟内存页面,这些页面的数据可以保存在物理页面中,也可以临时保存在磁盘上而不占用物理页面,可以在磁盘上开一个分区或者建一个文件专门用于临时保存虚拟内存页面的数据,这称为交换设备( Swap Device)。启用了交换设备之后,系统中可分配的内存总量等于物理内存的大小与交换设备的大小之和
这篇关于多文件和静态/动态链接以及虚拟内存管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






