本文主要是介绍实体链接中使用实体一致性信息(coherence),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实体链接(Entity Linking; Entity Disambiguation)是自然语言处理中一个很重要的任务,目的是将文本中发现的mention链接到知识库(Knowledge Base)中的标注实体(Entity)。
实体链接一般需要考虑三种信息,先验信息(prior),mention和entity之间的相似度,实体之间的一致性(coherence)
-
先验信息。一个是实体本身出现的频率,一个是mention确定下链接到某实体的条件概率,即 p(e|m)
-
相似度。mention和entity之间相似度,mention和entity上下文的相似度
-
一致性。通常一篇文档都有自己独有的topic信息,那么同一篇文档中的实体之间有一定一致性(coherence),也就是这些实体通常一起出现的概率会比较高,从而满足这个topic信息
这里我们专门讨论下如何在实体链接中利用这些实体之间的一致性信息。
[1] Robust Disambiguation of Named Entities in Text
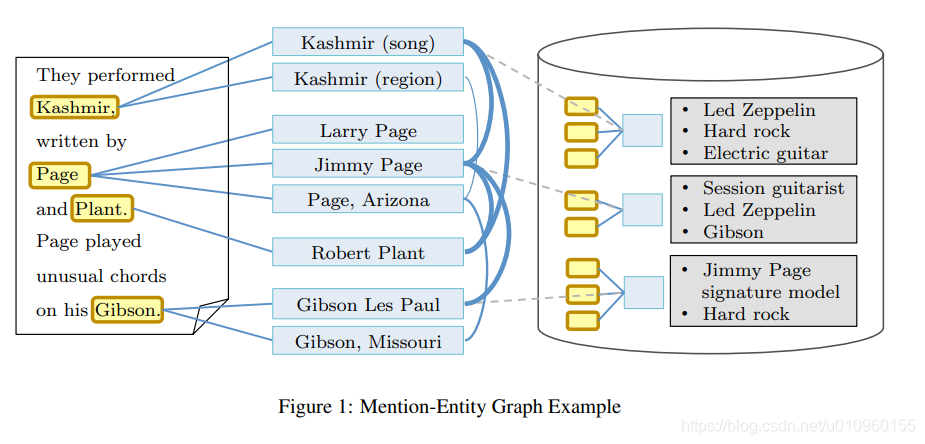
在这篇论文中,作者为了利用实体之间的一致性,构建了Mention-Entity Graph, 如上图所示。其中图中的节点有mention和entity两种类型。Mention和Entity之间的边是mention-entity popularity和mention-entity similarity线性组合得来的。 Entity和Entity之间的边代表它们的相关性,是通过统计Entity的Wikipedia中相同的内部链接(incoming links)得到的,具体计算方法如下:

有了Mention-Entity Graph后,可以把实体链接任务转为寻找最优子图(subgraph)任务。这个子图中,每个mention有且只有一条边,边的另一个节点就是最终结果的entity。作者定义了子图的density这个概念,那么最终目标就是在Mention-Entity Graph中寻找最大density的子图,这个阶段被称为graph algorithm。
Graph algorithm包含三个阶段,pre-processing, main loop, post-processing。pre-processing用来筛除部分candidate entities,减少计算量。在这里作者使用最短路径方法。main loop阶段是一个贪心算法,不断删除权重和最小的节点。这个阶段得到的子图不一定是最优的。第三个阶段post-processing选取第二阶段density最大的子图,然后通过枚举法找到最优子图。
这篇文章算法算是比较早利用Entity Coherence的方法,很经典。缺点也比较明显,graph algorithm中有太多的超参和trick,对于不同数据集需要仔细的调整,还是比较费力的。总的来说这篇文章还是非常经典,其中entity linking的思想应该不会过时,值得我们学校和思考。
[2] Collective Entity Linking in Web Text: A Graph-Based Method
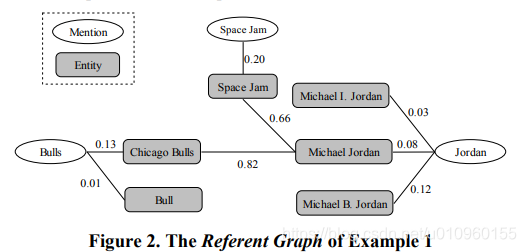
这篇文章与前面那一篇有点类似,首先构建Mention-Entity Graph,在这里作者称之为Refernt Graph, 如上图所示。 Mention和Entity 之间的边叫做 Local Mention-to-Entity Compatibility, 是通过计算mention和entity之间的上下文相似度得到的。Entity之间的边叫做Semantic Relation between Enitities,计算方法与论文1中计算entity之间相似度方法类似。

有了Mention-Entity Graph之后,我们就可以做collective inference。如上公式所示,给定一个mention, 对每个候选的entity计算mention-to-entity compatibility和rd(e),找到相乘值最大的那个作为结果。mention-to-entity compatibility我们很容易获得,那么如何计算rd(e), 这个值代表这个entity与这个document的主题相符合的证据。在这里作者使用random graph walk的方法计算这个值。
总的来说这篇文章跟第一篇论文方法很类似,不同的地方就是在coherence这里作者使用random walk计算。
[3] Deep Joint Entity Disambiguation with Local Neural Attention
这篇文章中作者提出了一种文档级别(document-level)的实体消歧方法,作者设计了Local Model和Global Model,其中Local Model主要是利用先验信息和相似度信息; Global Model利用实体之间的coherence
Local Model
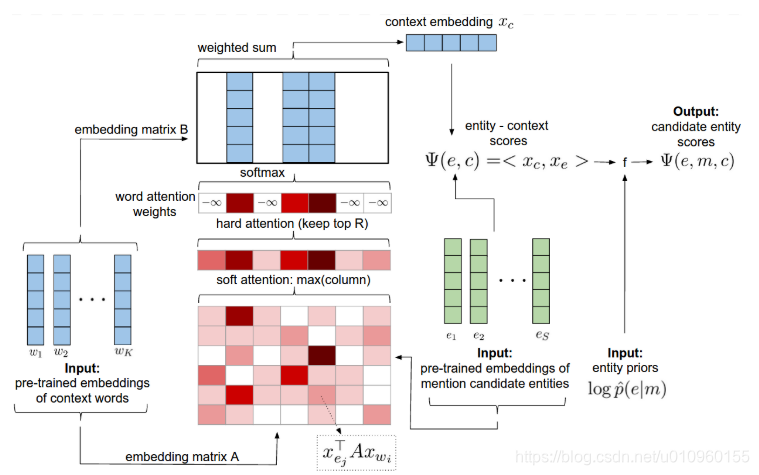
Local Model的框架图上图所示, 模型的输入有三个,一个是mention的上下文,一个是预训练的entity向量,最后一个输入是mention-entity的先验信息。模型的输出就是Local Score.
在这里作者的思想是,如果mention的上下文与某个entity candidate越相关,而且训练数据中这个mention曾链接到这个entity candidate出现的次数越多的话,那么这个entity candidate的得分就越高。作者在这里使用了几个关键技术,一个是预选了entity embedding,另一个是使用Attention寻找上下文中与某个entity candidate最相关的词。值得注意的是,作者使用的是hard attention
Global Model
 \
\
全局模型如上图所示,作者使用的是fully-connected pairwise CRF计算entity之间的相关性,我对这块不太熟悉,有兴趣的可以直接看论文。
[4] End-to-End Neural Entity Linking
这篇文章设计了一种端到端(End-to-End)的实体链接方法,不需要使用人工设计的特征。模型框架如下图,主要分为两步,第一步同样是local model,计算一个mention和entity candidate的分数;第二步global model,借助entity之间的coherence得到global score。
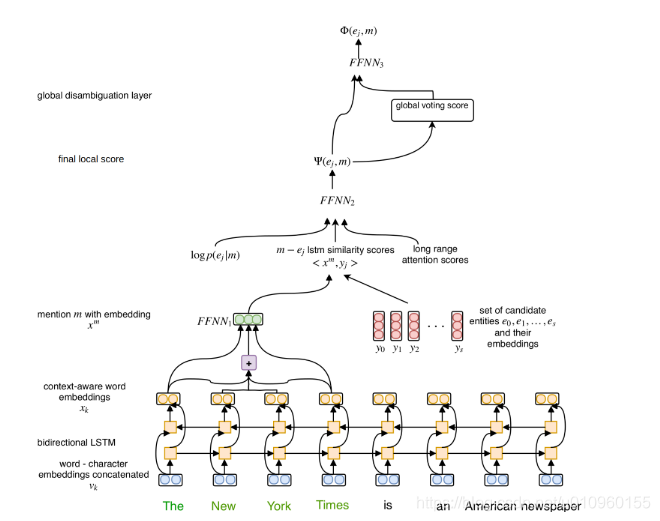
Local Model
在第一步中,作者使用了三种方法来表示一个word,这样就可以更加丰富的表示一个word
-
word embedding
-
character-level representation
-
contextual representation
对于entity,作者也对其就行训练,得到entity/word embedding。接下来计算mention和entity candidate的相似度,在这里考虑三个因素
-
先验知识 logp(e|m)
-
神经网络计算的mention和entity candidate相似度
-
mention上下文与entity candidate的相似度
最后使用一个FFNN将这三个分数进行组合,得到最终的local score.
Global Model
这一步作者使用voting entities的embedding来计算global score。主要思想是这样的,设想有一篇文档,这篇文档有一个主题, 其中有若干mentions。那么我们可以假设这些entity candidates中一部分也是跟这个主题相关的,我们称这些entities为voting entities。 我们可以使用这些voting entities来表示这个文档的主题。在这里作者使用的是这些entities embedding的均值作为topic。然后在计算candidate embedding和topic embedding的cosine相似度得到最终的global score。具体计算方法如下:
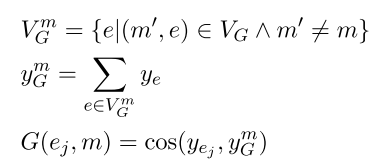
最后再使用一个FFNN将local score和global score进行融合,得到了最终的分数。
总结
一般来说,实体链接这个任务需要考虑的因素无非就是三个
-
先验知识
-
mention和entity的similarity
-
entity之间的一致性(coherence)
这篇文章我们主要介绍了四种使用coherence的方法,前两篇是非深度学习的,后两篇是基于深度学习的。在使用coherence上面,前两篇论文的方法都是基于mention-entity graph,也就是首先要构建一个图,这里存在一个问题,mention-entity之间的边是容易获取的,但entity之间的边不是很容易,这两篇论文是使用wikipedia构建entity之间的边。在很多任务中entity的信息不是那么完整,没有一个很完整description,这样就很难构建这样一个图。另外,第一篇论文使用一种迭代的方法计算coherence,引入了几个超参,所以还需要调整超参,可以说有点费力。第二篇论文使用random walk,还好一点。
第三篇和第四篇都是基于深度学习,总体思想类似,在使用coherence上,第三篇使用的是CRF,第四篇使用的是简单的cosine相似度。两篇论文都使用了pre-trained entity embedding和attention机制的上下文关键词提取。看来这两个因素还是很有用。
这篇关于实体链接中使用实体一致性信息(coherence)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





