本文主要是介绍7.大数据之_linux基本知识_2_文件目录操作命令_1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇 6.大数据之_linux基本知识_2_文件目录操作命令_0
1.6.2 rm(移除档案或目录)
用法:rm [-fir] 档案或目录
选项参数:
-f:忽略不存在的档案,不会出现警告,f(force)
-i:互动模式,再删除前会询问使用者是否进行删除动作
-r:递归删除,常用在目录的删除,(这是非常危险的选项),删除了就找不回来了
举例:

目录参考上图
<1>rm -i /tmp/test1/fff.txt
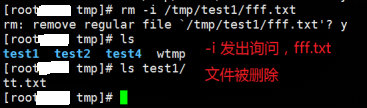
说明:使用-i命令删除档案(文件),系统发出交互信息。
<2>rm -i /tmp/test1/tt*
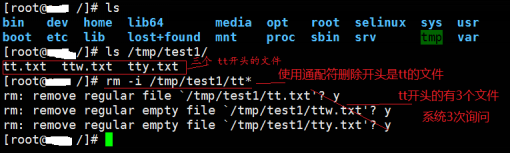
说明:通配符删除文件,*代表的是0~任意多个字符
<3>rmdir /tmp/test2/test3/

说明:由于目录下面有文件,所以删除时,系统会提示消息(提示消息的原因是root
用户所以预设加入了-i选项,这是一种保护机制,防止误删)。
这时使用:
rm -r /tmp/test2/test3/
/rm -r /tmp/test2/test3/ (去掉系统删除提示)
-r代表递归删除,也就是将目录下面的文件删除然后将test3目录删除,注意不会删除test2目录,这是递归向下。
<4>rm ./-aasd

说明:删除开头是-的档案(文件),一定要使用./指定在当前目录下面,因为-在linux系统中表示后面接的是选项,因此,单纯的使用『rm - aasd 』系统的指令就会误判。所以,只能避过首位字符是 "-"的方法,就是加上本目录『./ 』。还有另一种方式rm -- -aasd
1.6.3 mv移动档案与目录或更名
用法:mv [-fiu] 要移动的文件 目的位置
mv要移动的文件1要移动的文件2要移动的文件3 … 移动的目的位置
选项参数:
-f:如果目标文件已经存在,系统不会询问直接覆盖
-i:目标文件已存,系统发起询问是否覆盖(root用户系统会预设添加-i选项)
-u:若目标文件已经存在,且要移动的文件比较新,这时才会更新
举例:
<1>mv aaa.txt test1
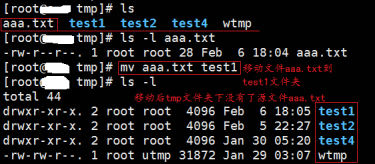
说明:将aaa.txt文件移动到test1文件夹下面
<2>mv -i aaa.txt test1(-i root用户会进行预设加入)

说明:移动时,目标文件夹有同名的文件,系统发起询问是否覆盖
<3>mv -u aaa.txt test1

说明:-u选项系统发起询问,是否覆盖原文件。
1.6.4取得路径的文件名和目录名
<1>basename
用法:basename路径
举例:basename /etc/sysconfig/networw
说明:上面命令会显示文件名
<2>dirname
用法:dirname路径
举例:dirname /etc/sysconfig/network
说明:上面命令显示路径

1.6.4 文件内容查看
就像windows的记事本浏览文件一样,linux下,文件内容查看有很多常用的指令。
cat:由第一行显示文件内容
tac:从最后一行显示文件内容
nl:显示文件,同时输出行号
more:一页一页显示内容
less:一页一页显示内容,可以往前翻页
head:只看头几行
tail:只看尾巴几行
od:以二进制的方式读取档案内容
<1>cat
举例:cat [-AbEnTv] 文件(可以是文件路径)
选项:
-A:列出特殊字符
-b:列出行号仅仅针对非空白行显示行号,空白航不显示行号
-E:将结尾的断行字符$显示出来
-n:打印行号,空白行也显示行号
-T:将tab键以^显示出来
-v:列出一些看不出来的特殊字符
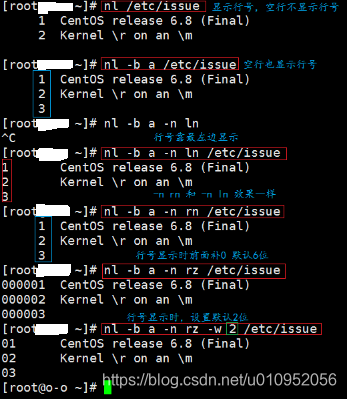
举例1:cat -n /etc/issue
说明:查看issue文件,-n表示同时显示行号
举例2: cat -nv /etc/xinetd.d/rsync
说明: -nv选项组合使用,显示行号,同时显示特殊字符。
<2>tac
用法:tac文件(也可以是文件的据对路径)
举例:tac /etc/issue
说明:从文件最后一行开始显示文件内容,就是倒序显示文件内容
<3>nl
用法:nl [选项参数] 文件
选项:
-b a:显示行号,空行也显示行号
-b t:显示行号,空行不显示行号
-n:列出行号的表示方法
-n ln:行号在屏幕的最左方显示
-n rn:行号在自己字段的最左方显示,且不加0
-n rz:行号在自己字段的最左方显示,且加0
-w:行号字段的占用位数
举例如下:
<4>more
用法:more文件(或者文件的绝对路径)
举例:more /etc/man.config
说明:将文件一页一页显示
操作键:
空格键:代表向下翻一页
Enter:代表向下翻一行
:f:立即显示文件名以及目前显示的行数
q:代表立刻离开more,不在显示该文档内容
b(或者ctrl b):代表往回翻页,这个动作只对文件有用,对管道没用
/字符串:代表在这个显示的内容当中,向下搜寻这个【字符串】
<5>.less 文档查看
用法:less 选项参数 文件
参数:
空格键:向下翻页
pagedown:向下翻页
pageup:向上翻页
/字符串:向下搜寻【字符串】的功能
?字符串:向上搜寻【字符串】的功能
n:重复前一个搜寻(与/或?有关)
N:反向重复前一个搜寻(与/或?有关)
q:退出less命令
举例:less /etc/man.config
说明:查看man.config文件
<6>head/tail 取出前几行/取出后几行
用法:head [-n number] 文件
参数:-n number:表示取出的行数,默认显示前10行(包含空行)
举例:
head /etc/man.config 取出前10行
head -n 21 /etc/man.config 取出前21行
注:tail和head用法一样,只是取出后几行
<7>.od 查看非纯文本文件
用法:od [-t type] 文件
type:
a:利用默认字符输出
c:使用ASCII字符输出
d[size]:利用十进制输出数据,每个整数占size bytes
f[size]:利用浮点数输出数据,每个数占size bytes
o[size]:利用八进制输出数据,每个整数占size bytes
x[size]:利用十六进制输出数据,每整个数占size bytes
举例:
od -t c /usr/bin/passwd 使用ASCII字符数出文件
od -t oCc /use/passwd 使用八进制和ASCII对照输出
od -t xCc /use/passwd 使用十六进制和ASCII对照输出
<8>.touch 修改文档时间或者创建新文档
介绍:每个文档在linux下会记录很多的时间参数,其中有三个主要的时间参数
modification time (mtime):
当文档的内容变动时,就会更新这个时间,文档内容不包含文档的权限和属性
status time (ctime):
当文档的状态改变时,就会更新这个时间,比如权限与属性的变更
access time (atime):
当文档的内容被读取时,就会变动这个时间,比如使用cat读取文档
用法:touch [-acdmt] 文件
选项参数:
-a:仅修订 access time
-c:仅修改文件的时间,若该档案不存在则不建立新文件
-d:可以接欲修订的日期而不用目前的日期,也可以用 --date="日期或时间"
-m:仅修改 mtime
-t:后面可以接欲修订的时间而不用目前的时间,格式为[YYMMDDhhmm]
举例:
a.[root@XXXxxx tmp]# touch ttt
[root@XXXxxx tmp]# ls -l ttt
-rw-r--r--. 1 root root 0 Feb 12 18:25 ttt
说明:在tmp文件夹下面创建文件ttt,touch 文件不存在就会创建。
[root@xxxx tmp]# ll ttt; ll --time=atime ttt; ll --time=ctime ttt;
上面这个命令是查看三个时间
-rw-r--r--. 1 root root 0 Feb 12 18:25 ttt 这是mtime
-rw-r--r--. 1 root root 0 Feb 12 18:25 ttt 这是atime
-rw-r--r--. 1 root root 0 Feb 12 18:25 ttt 这是ctime
ll===ls -l ,';'表示连续指令,也就是输入多重指令,这些指令可以依顺序执行
b.[root@xxxx tmp]# touch -d "2 days ago" ttt 修改时间为2天前
[root@xxxxx tmp]# ll ttt; ll --time=atime ttt; ll --time=ctime ttt;
-rw-r--r--. 1 root root 176 Feb 10 18:46 ttt 这是mtime
-rw-r--r--. 1 root root 176 Feb 10 18:46 ttt 这是atime
-rw-r--r--. 1 root root 176 Feb 12 18:46 ttt 这是ctime
c.[root@o-o tmp]# touch -t 0809061325 ttt 修改时间为2008年9月6号13点25分
[root@o-o tmp]# ll ttt; ll --time=atime ttt; ll --time=ctime ttt;
-rw-r--r--. 1 root root 176 Sep 6 2008 ttt 这是mtime
-rw-r--r--. 1 root root 176 Sep 6 2008 ttt 这是atime
-rw-r--r--. 1 root root 176 Feb 12 18:50 ttt 这是ctime
1.6.5 文件预设权限
当建立一个默认的文件时,系统会设定默认的权限,这个默认权限就与umask(当前用户建立文件或者目录的时候的默认权限值)有关

0022是系统umask的数字形态的权限值,后三组022表示的是创建文件时,系统需要处理的文件权限值,第一个0暂时不用理会。
创建文件时,一般默认,文件是不可以执行的,一般文件是为了保存数据使用的。所以系统文件的最大权限是666也就是,预设权限是 –rw-rw-rw-
创建目录时,要进入此目录,就需要x权限,因此,默认权限全部开放,最大权限值是777,预设权限是drwxrwxrwx
umask确定的是,在创建目录或者权限时需要除去的权限值,因此系统默认权限值是:
创建文件:(-rw-rw-rw-) – (------w--w) ==> (-rw-r--r--) 也就是666 – 022 ==> 644(非数学减法)
创建目录:(drwxrwxrwx) – (d-----w--w)=>(drwxr-xr-x)也就是777-022=>755(非数学减法)
验证:
![]() 创建的文件
创建的文件
![]() 创建的目录
创建的目录
这篇关于7.大数据之_linux基本知识_2_文件目录操作命令_1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







