本文主要是介绍搭建访问阿里云百炼大模型环境,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近这波大降价,还有限时免费,还不赶快试试在线大模型?下面整理访问百炼平台的千问模型方法。
创建RAM子账号并授权
创建RAM子账号
1. “访问控制RAM”入口(控制台URL)
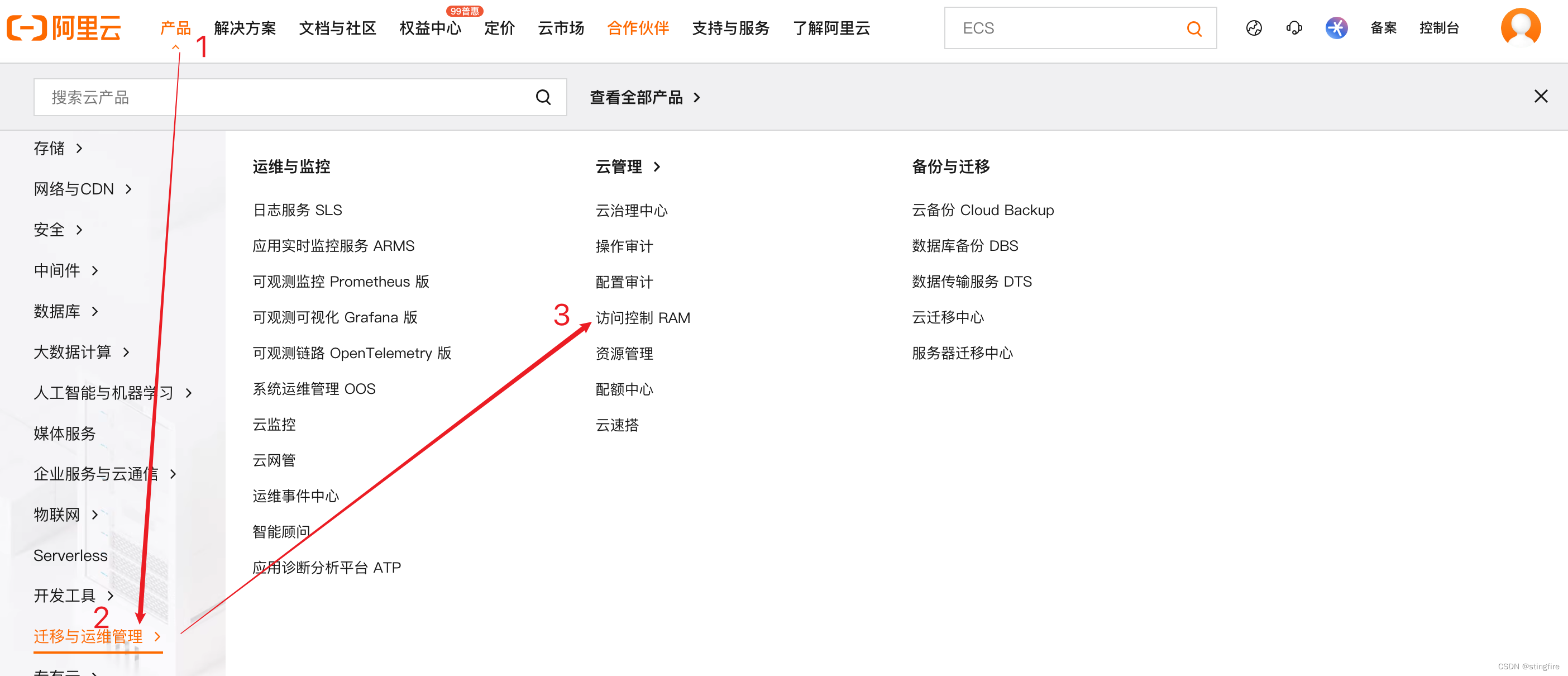
然后点击进入“RAM管理控制台”

2. 添加用户
身份管理-->用户,打开创建用户入口:


RAM子账户授权
1. 选择需要授权的用户进行授权操作
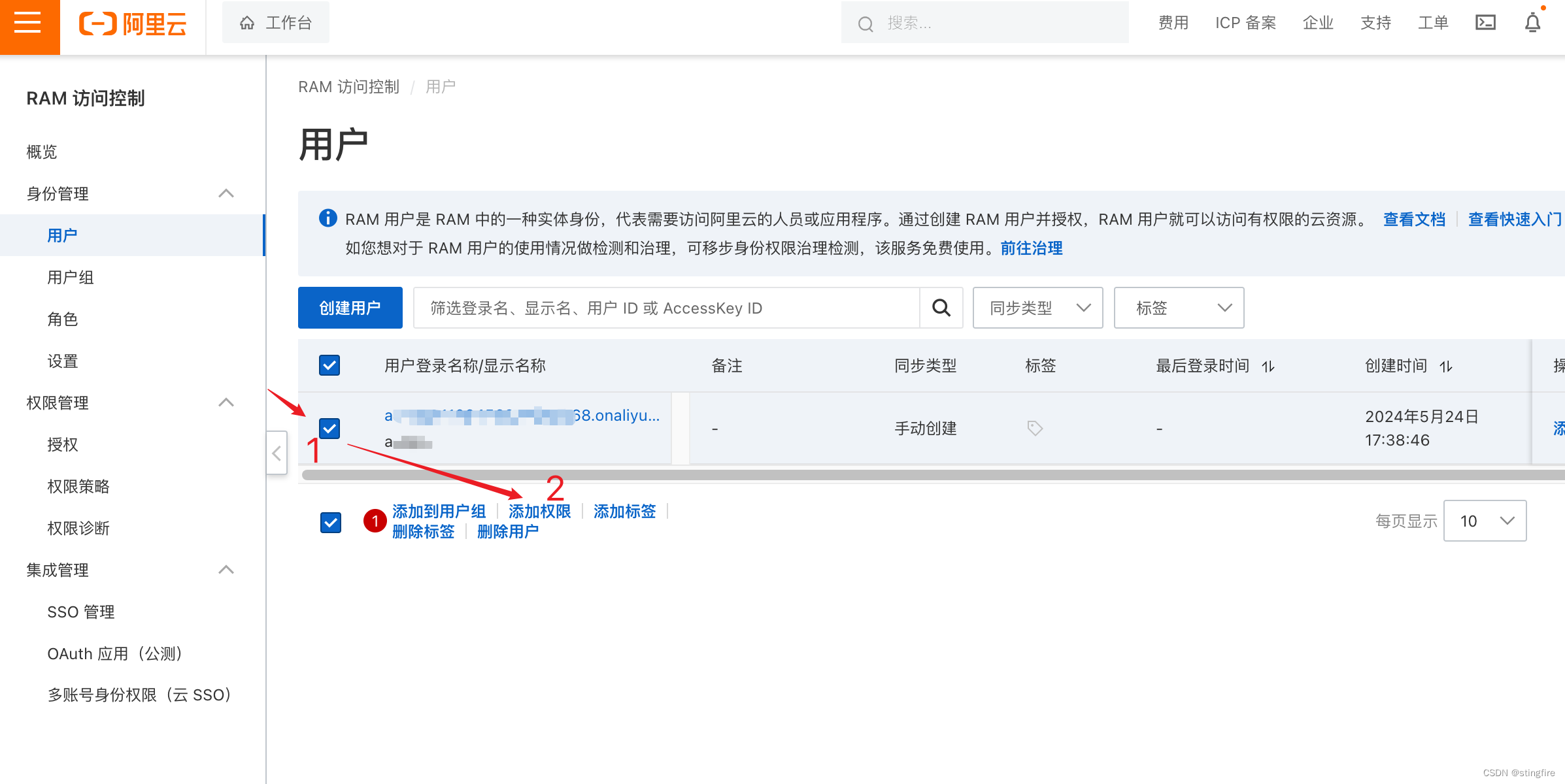
2. 选择添加百炼权限
下面截图是笔者已经添加过了,操作步骤按下面序号标注进行即可添加“AliyunSFMFullAccess”权限。

添加百炼权限
1. 访问百炼控制台

点击“管理控制台”进入。(URL直通车)

2. 选择授权用户
“系统管理” --> “权限管理” --> “用户管理”

在用户管理页面对欲授权的用户操作“权限编辑”:
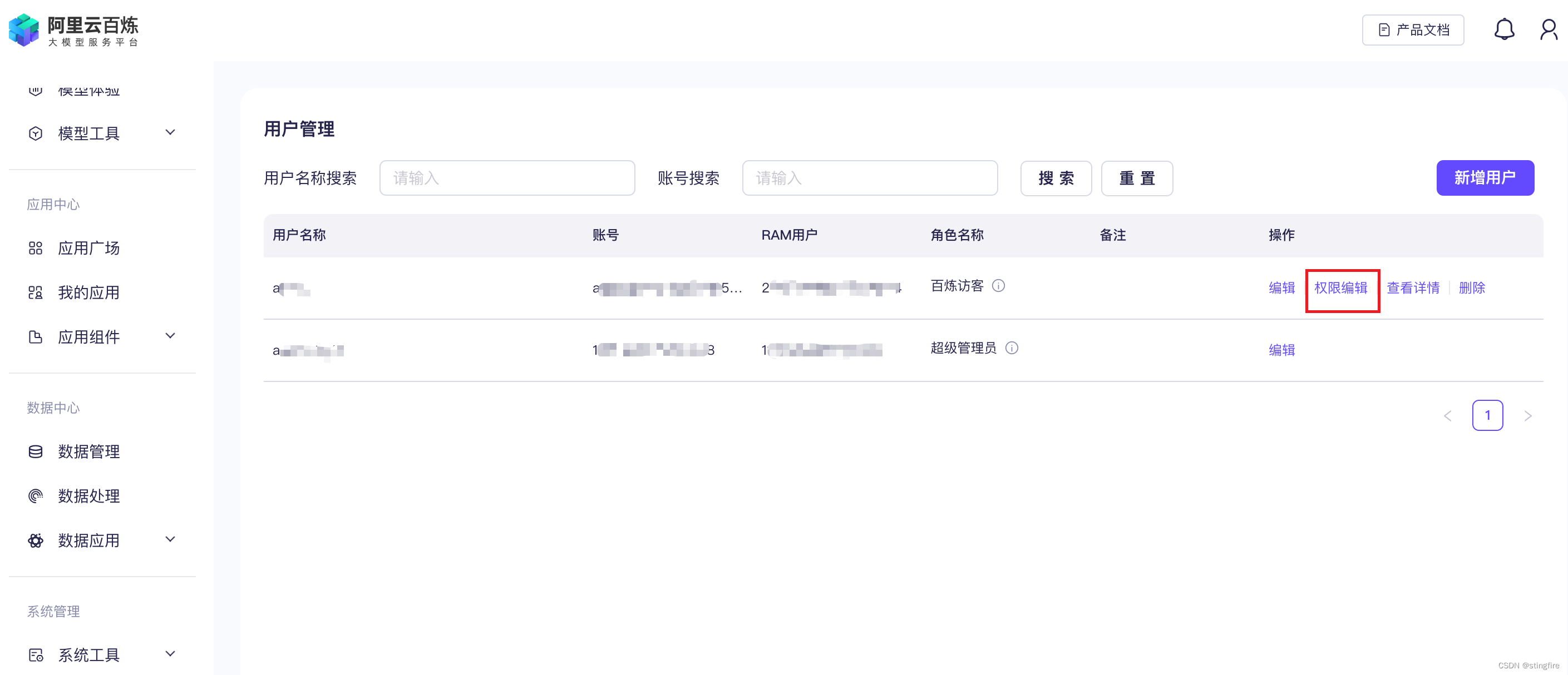
3. 业务授权:
根据需要选择权限:

访问千问
基于LangChain编写下面示例代码:
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_bailian import Bailian# 构建prompt
prompt = ChatPromptTemplate.from_template("给我讲一个关于 {topic}的笑话")# 构建LLM模型
# 需要在环境变量设置ACCESS_KEY_ID、ACCESS_KEY_SECRET、AGENT_KEY和APP_ID
access_key_id = os.environ.get("ACCESS_KEY_ID")
access_key_secret = os.environ.get("ACCESS_KEY_SECRET")
agent_key = os.environ.get("AGENT_KEY")
app_id = os.environ.get("APP_ID")llm = Bailian(access_key_id=access_key_id,access_key_secret=access_key_secret,agent_key=agent_key,app_id=app_id)chain = prompt | llm | StrOutputParser()print(chain.invoke({"topic": "大模型"}))
其中的ACCESS_KEY_ID / ACCESS_KEY_SECRET / AGENT_KEY / APP_ID四个参数根据《
AccessKey、AppID及AgentKey获取方式》获得。
运行后百炼平台返回(貌似并不好笑-_-!):

题外话:
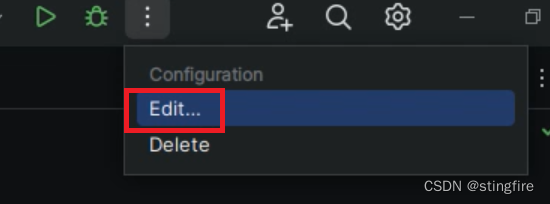
执行上面Python代码时PyCharm报ACCESS_KEY_ID / ACCESS_KEY_SECRET / AGENT_KEY / APP_ID非法的异常。通过debug发现在bashrc文件(linux环境)中设置的环境变量并没有在PyCharm中生效。这时只需要通过配置PyCharm项目的环境变量即可:

参考资料:
RAM子账号使用方式和授权操作
这篇关于搭建访问阿里云百炼大模型环境的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









