本文主要是介绍第五十四周:文献阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
Abstract
文献阅读:基于经验模态分解的混合空气质量预测模型
现有问题
提出方法
方法论
1、扩展ARIMA模型
2、经验模态分解(EMD)
3、截断奇异值分解(SVD)
SE-ARIMA模型
研究实验
1、数据集
2、评估指标
3、实验过程
4、实验结果
总结
摘要
本周我阅读的文献《A Hybrid Air Quality Prediction Model Based on Empirical Mode Decomposition》中提出了一种新型的混合模型,用于预测多个监测站点的空气质量。该模型主要包含扩展的自回归积分移动平均(ARIMA)模型、经验模态分解(EMD)和截断奇异值分解(SVD)。模型的核心在于扩展ARIMA模型以适应空间数据矩阵,通过EMD处理,模型可以更好地理解和预测数据中的动态变化。SVD的应用则进一步处理这些子序列,通过矩阵的奇异值分解,保留最重要的特征同时去除噪声,优化数据的表达。这种结合传统统计方法和现代信号处理技术的方法,在实验中显示出比现有模型更高的预测精度和更低的计算成本。
Abstract
The literature I read this week, "A Hybrid Air Quality Prediction Model Based on Empirical Mode Decomposition," proposes a novel hybrid model for predicting air quality at multiple monitoring stations. This model mainly includes an extended autoregressive integral moving average (ARIMA) model, empirical mode decomposition (EMD), and truncated singular value decomposition (SVD). The core of the model lies in extending the ARIMA model to adapt to spatial data matrices. Through EMD processing, the model can better understand and predict dynamic changes in the data. The application of SVD further processes these subsequences, preserving the most important features while removing noise and optimizing data expression through matrix singular value decomposition. This combination of traditional statistical methods and modern signal processing techniques has shown higher prediction accuracy and lower computational costs than existing models in experiments.
文献阅读:基于经验模态分解的混合空气质量预测模型
A Hybrid Air Quality Prediction Model Based on Empirical Mode Decompositionhttps://webofscience.clarivate.cn/wos/woscc/full-record/WOS:001074356700009pdf:IEEE Xplore Full-Text PDF:
2024 清华科技
现有问题
第一,空气质量受到许多因素的影响,例如天气条件,空间特征,甚至电子设备等,因此不可能对所有因素进行建模。第二,空气质量在不同时间和地点有很大差异,如果不考虑空间和时间特征,很难达到高精度。第三,由于网络和监测设备的脆弱性,收集的空气质量数据可能不完整。也就是说,在采集的数据中存在大量的噪声,这可能会影响预测模型的准确。
传统的ARIMA模型虽然在空气质量预测中被广泛使用,由于监测站之间的空间关系,其性能在面对数据的高波动性和缺乏空间上下文信息时往往不稳定。虽然一些深度网络可以达到更高的精度,但需要大量的训练数据,繁重的计算和时间成本。
提出方法
提出了一种混合模型,该模型将扩展自回归综合移动平均(ARIMA)模型与经验模式分解(EMD)和奇异值分解(SVD)相结合,以预测未来几小时的空气质量数据。
- 首先,通过扩展ARIMA模型以适应多监测站点的矩阵时间序列预测,用于预测多个相邻监测站的多个空气质量指标的矩阵序列,增强模型处理多元数据的能力。
- 接着使用EMD方法将非平稳的空气质量时间序列数据分解为多个平滑的子序列,这有助于分离和识别数据中的各种模态成分。
- 最后,应用截断SVD技术压缩并去噪数据矩阵,提高预测的准确性和效率。
方法论
模型的核心在于扩展ARIMA模型以适应空间数据矩阵,这通过将传统的ARIMA模型与矩阵操作相结合来实现。EMD作为一种自适应方法,能有效地将时间序列分解为若干固有模态函数(IMF),它不需要固定的基函数,适用于非线性和非平稳数据分析。通过EMD处理,模型可以更好地理解和预测数据中的动态变化。SVD的应用则进一步处理这些子序列,通过矩阵的奇异值分解,保留最重要的特征同时去除噪声,优化数据的表达。
1、扩展ARIMA模型
本文中的扩展ARIMA模型不仅处理单一时间序列数据,而是通过矩阵序列来同时预测多个监测站点的空气质量指标。这种方法能够考虑到空间相关性,即不同监测站点之间的数据关联,这是传统ARIMA模型所忽视的。在数学上,这种扩展涉及到将ARIMA模型的参数估计和预测过程从一维时间序列推广到多维矩阵序列。
ARIMA模型本质上是一种线性回归模型,用于跟踪平稳时间序列数据的线性趋势。模型表示为ARIMA(p,d,q)。参数p、d、q为整数值,决定了时间序列模型的结构。其中参数p、q分别为AR模型和MA模型的阶数,参数d为应用于数据的差分水平。阶(p,q)的ARMA模型的数学表示如下
使用标准化的方法来构建ARIMA模型,该方法包括三个迭代步骤:
- 模型识别与模型选择确定模型的类型,是AR(p)还是MA(q),还是ARMA(p,q)。
- 参数估计对模型参数进行调整以优化模型。
- 对模型进行检验残差分析,使模型更加完善。
2、经验模态分解(EMD)
经验模态分解(EMD)是一种适用于非线性、非平稳信号的分析方法。通过这种技术,原始的复杂数据被分解为一系列简单的子信号(固有模态函数,IMF),每个IMF代表数据中的一个简单波动模式。这样的分解帮助模型捕捉到隐藏在嘈杂数据中的重要特征,为后续的分析和预测提供了更清晰、更稳定的数据基础。每一个 IMF必须满足2个条件:
- 在整个时程内极值点个数与过零点个数相等或最多相差1;
- 在任意时刻,由局部极大值点形成的上包络线和由局部极小值点形成的下包络线的平均值为零,即上、下包络线相对于时间轴局部对称。
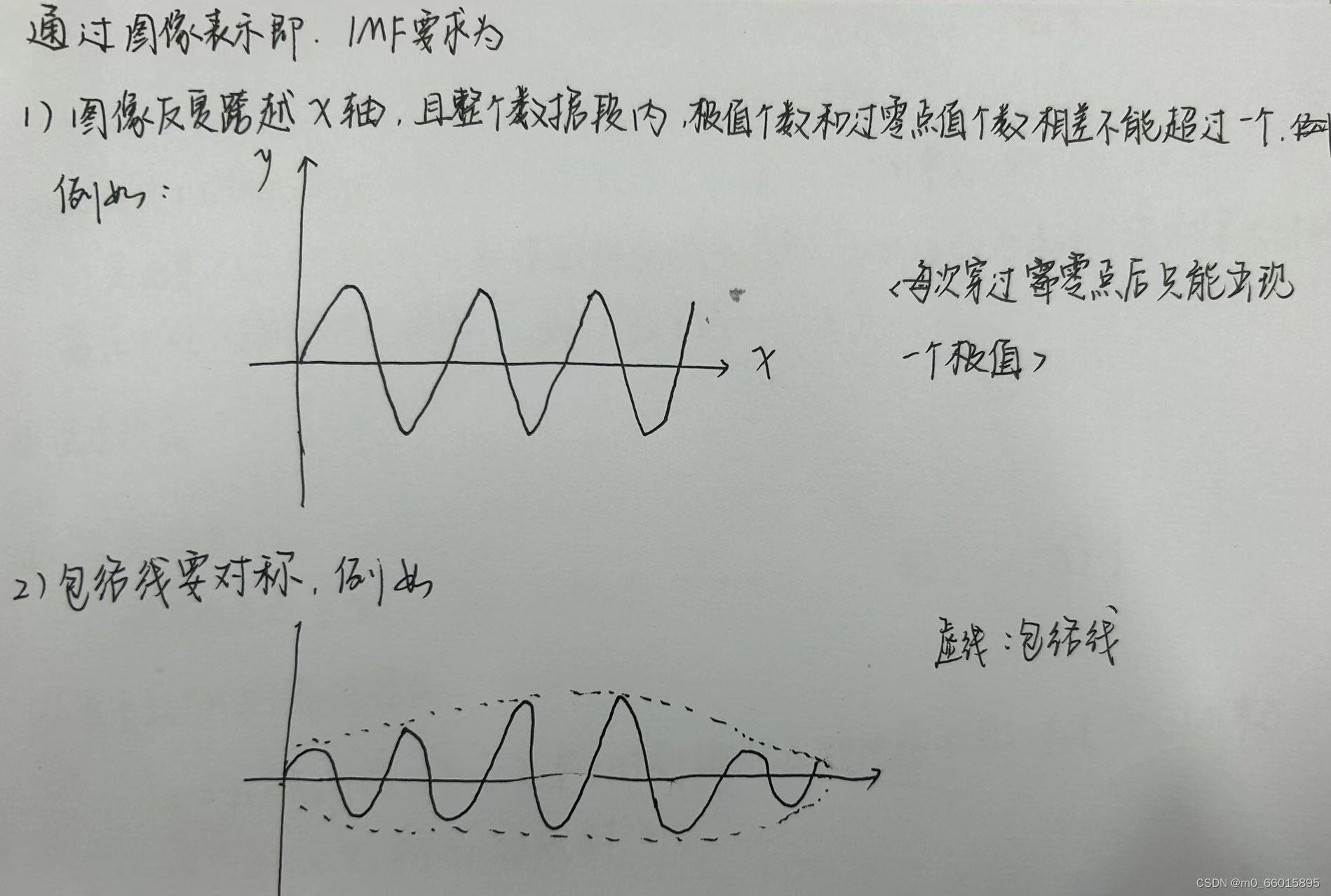
EMD过程
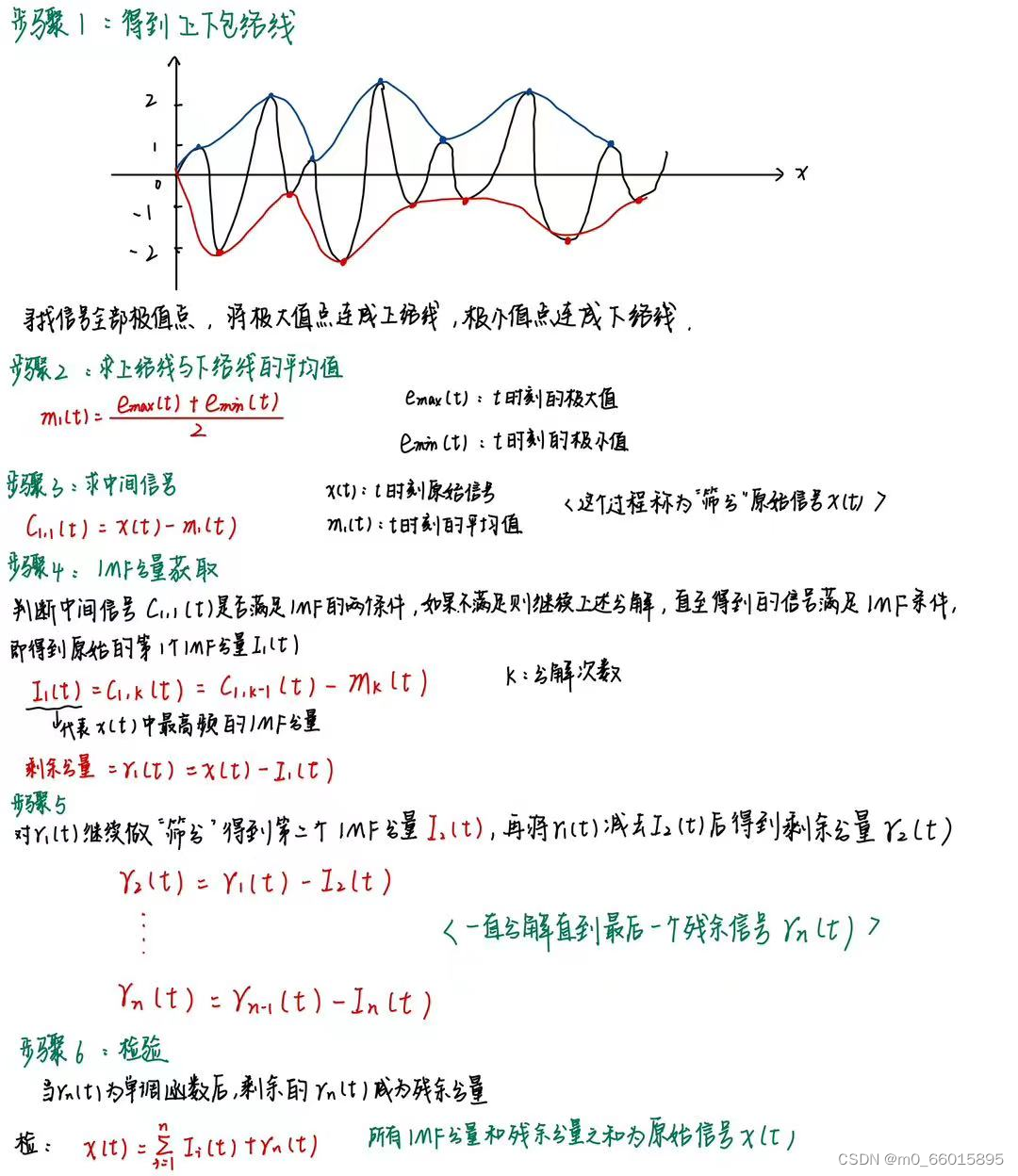
它可以根据数据的局部特征将非平稳序列分解为多个光滑IMF和一个残差序列,下图显示了从600小时PM2:5数据的经验模态分解获得的多个IMF和残差(即RES)。
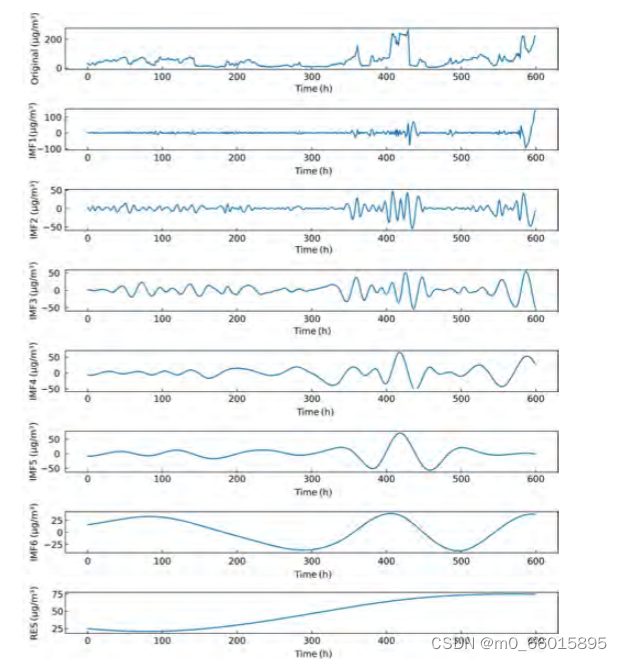
下图为同时段PM2.5分解结果,由于不同序列数据的特征和分布不同,因此EMD得到的IMF的个数也不同,这将导致我们的矩阵序列的大小不一致,这不能用ARIMA建模。通过限制分解的数量,可以解决不同数量的组件的问题。我们将其设置为分解三次后停止,以确保所有分解矩阵的大小保持不变,都扩展到其初始大小的三倍,并且通过EMD分解的矩阵序列可以通过ARIMA建模和预测。

现实情况是,对于某些序列,EMD得到的分量个数小于3个,甚至不满足EMD的初始条件。对于这种情况,我们添加一个或两个0值系列,以便所有系列满足三个分量的要求。然而,这种方法相当于引入噪声数据,而截断SVD的引入可以解决这个问题。
3、截断奇异值分解(SVD)
截断奇异值分解(SVD)在这里的应用主要是数据降维和去噪,通过保留数据矩阵中最大的若干个奇异值及其对应的奇异向量,截断SVD能够去除那些可能由测量误差或其他非本质变动引起的噪音部分,从而使模型聚焦于数据的主要变动趋势。
截断SVD为原始矩阵提供了最佳的低秩矩阵近似,可用于降低矩阵维数,提取数据的主要特征,并去除数据噪声。对于给定的任意m行n列矩阵 ,矩阵Z的奇异值分解如下所示:
其中对角矩阵 是奇异值矩阵。矩阵的对角元素表示
的奇异值,并按从大到小的顺序排列。P和V是酉矩阵,其每行和列分别表示矩阵
的左奇异向量和右奇异向量。选择V的前r列来构造
个特征矩阵,其中
然后可以压缩原始空气质量矩阵Z的列。
SE-ARIMA模型
其中IMF1,IMF2和IMF3表示EMD的子系列,它们是固有模式函数。
- 首先将多个监测站在当前时段的七项空气质量指标作为一个矩阵。因此,将最近T个时隙中的历史数据视为矩阵序列。
- 使用EMD分解矩阵序列中的每个元素序列分解成三个光滑的子序列。
- 再使用截断SVD去除数据中的噪声,
- 然后将压缩矩阵送入扩展ARIMA模型对三个序列进行预测。
- 最采用逆EMD,即将对应于每个空气质量指标的三个子信号相加以获得最终结果。


研究实验
1、数据集
实验使用了北京市环境保护监测中心网站上的空气质量数据,包括北京市35个空气质量监测站的历史空气质量公共数据集。空气质量数据包括AQI和PM2:5、PM10、SO2、NO2、O3和CO六种浓度的小时数据。由于植物园监测站中的大部分数据缺失,直接剔除了这个监测站的数据,选取剩下的34个监测站的数据作为最终实验的数据。
2、评估指标
采用均方根误差(RMSE)和平均绝对误差(MAE)作为评价指标来衡量SE-ARIMA的准确性。该等估值指标的公式如下:

3、实验过程
实验部分详细地验证了混合模型在多个方面的性能,首先通过与传统ARIMA模型的比较,展示了扩展ARIMA模型在处理空间相关数据时的优越性。随后,通过将EMD和SVD引入模型,对比了处理前后的预测结果,确证了这些方法在提高预测准确性和数据处理效率方面的贡献。
4、实验结果
一、性能比较
为了证明SE-ARIMA的性能,我们将其与几种性能良好的预测方法进行了比较,包括线性回归(LR),SVR,LSTM和ARIMA。
1、验证多步预测性能
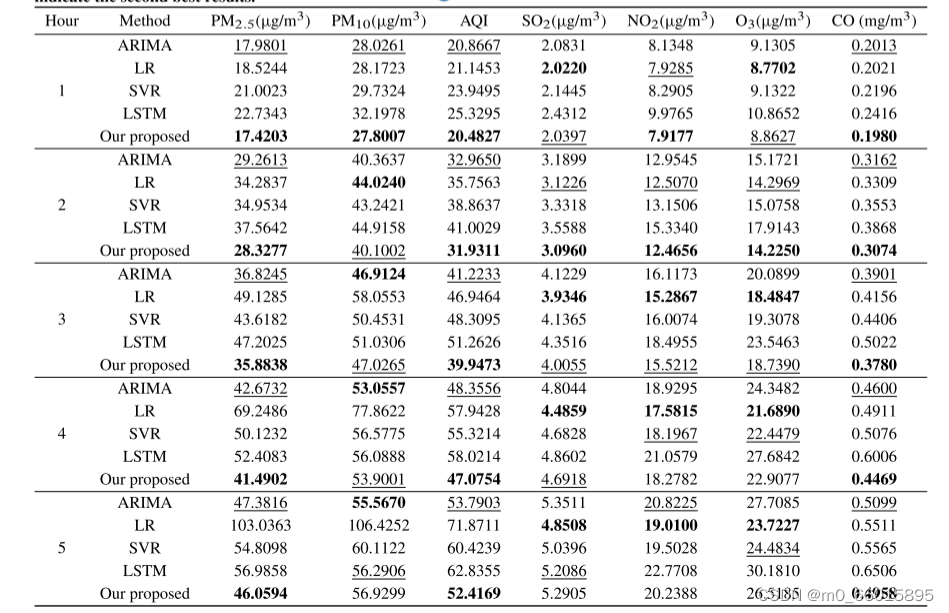
为了证明我们提出的多步预测方法的性能,我们对数据集进行了未来5小时的空气质量预测。表列出了在接下来的5小时内与其他方法的准确度比较。这些值是七个空气质量指标的评价指标的平均值。可以看出,我们提出的SE-ARIMA取得了最好的结果。与传统的ARIMA模型相比,该方法的RMSE和MAE分别降低了1.51%~ 2.81%和0.51%~ 2.47%。


可以发现深度学习网络LSTM的效果很差,这可能是由于深度模型的参数太多而导致模型过度拟合。ARIMA模型比LR模型有上级的优越性,特别是对未来的多步预测。这是因为ARIMA模型不仅考虑了过去时间的滞后,还考虑了过去误差的滞后。
结果说明ARIMA可以在经验模态分解后应用于更平滑的数据,这正是ARIMA模型所需要的。此外,由于SVD消除了噪声数据对最终结果的一些影响,并隐含地捕捉了不同位置空气质量之间的相关性,因此与传统的ARIMA相比,我们的模型更准确。
2、验证对不同指标的预测性能
表为方法对不同空气污染指标的预测性能的评估结果,与其他方法相比,提出的方法预测的AQI,PM2:5,NO2和CO在1-2小时内的RMSE和MAE最小。前两步预测的平均MAE值分别下降了1.10%、1.35%、3.20%和2.43%。预测未来3-5小时的RMSE和MAE最小。可以看出,我们提出的方法可以提高AQI,PM2:5和CO的预测精度,取得了最好的结果,可用于长期和短期预测。

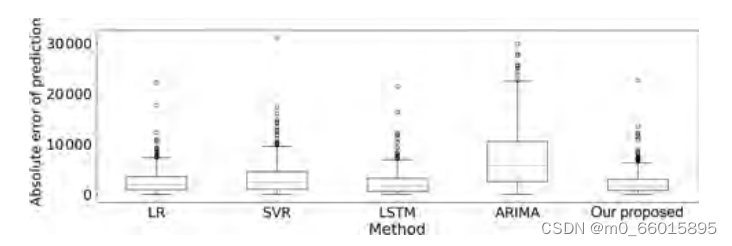
3、预测精度的绝对误差
图为提出模型和比较方法的绝对误差的箱形图,,每种方法的误差是34个监测站的7项空气质量指标的预测值与实际值的绝对误差之和。可以清楚地观察到,我们提出的方法在所有方法中具有最小的绝对误差,并且其分布在一个小范围内。表明该方法预测的绝对误差的异常值相对于基线值较小,预测结果能够更准确地反映真实情况。
4、成本损耗验证
验证每种方法的时间是在34个监测站对7个空气质量指标进行300次预测的平均成本,其中方法的计算时间是所有比较方法中最短的,仅为LR的60.20%,比传统的ARIMA方法减少了43.66%。综上所述,我们的方法可以有效地提高预测的整体精度,减少计算时间成本。
二、消融实验
三个部分:(1)建议-1:删除用于平稳数据的EMD部分和用于去噪数据的截断SVD部分;(2)建议-2:删除EMD部分;(3)建议-3:删除截断SVD部分。在所有参数设置相同的情况下,将所提出的方法与上述三种情况进行了比较。预测结果的RMSE和MAE见表,没有EMD分量,预测误差略有增加,因为数据不够稳定。在没有截断SVD部分的情况下,性能降低更多,这表明截断SVD可以导致模式性能的更大改善。因此说明SE-ARIMA的每个部分都可以提高整体预测的性能。
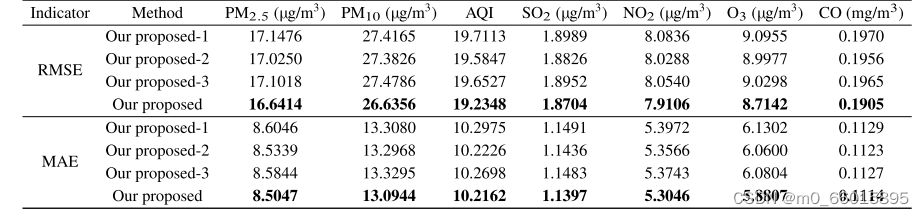
具体来说,使用EMD处理后的时间序列数据在预测精度上有显著提升,因为EMD帮助模型更有效地识别和利用数据中的周期性和趋势性信息。而SVD的应用则显著减少了模型运算时间和提高了数据处理的效率,验证了其在大规模数据处理中的实用价值。
代码实现
EMD分解
from PyEMD import EMD
import numpy as np
import matplotlib.pyplot as plt# 对数据进行EMD分解
def do_emd(y):"""将输入序列y进行EMD分解:param y: 一维数组,array/list,将要分解的数据:return:多维数组,分解后的结果"""emd = EMD.EMD()IMFs = emd(y)N = IMFs.shape[0] + 1return IMFs, N# 对原数据及分解后的数据进行绘制
def do_plot(N, IMFs, x, y):plt.subplot(N, 1, 1)plt.plot(x, y, 'r')for n, imf in enumerate(IMFs):plt.subplot(N, 1, n + 2)plt.plot(x, imf, 'g')plt.title("IMF " + str(n + 1))plt.tight_layout()plt.show()if __name__ == "__main__":# 1.生成随机数序列y,及序号序列xy = np.random.random(100)x = [i for i in range(100)]# 2.分解IMFs, N = do_emd(y)# 3.绘制原序列及分解结果do_plot(N, IMFs, x, y)SVD
def svd(A):# 计算矩阵A的转置矩阵和AA^T矩阵的特征值和特征向量A_T = np.transpose(A)A_A_T = np.dot(A, A_T)eig_value_AA_T, eig_vector_AA_T = np.linalg.eig(A_A_T)# 将特征向量进行正交化处理得到左奇异向量矩阵UU = np.dot(A_T, eig_vector_AA_T)U_norms = np.array([np.linalg.norm(u) for u in U.T])U = (U.T / U_norms).T# 计算矩阵A的转置矩阵和A^TA矩阵的特征值和特征向量A_T = np.transpose(A)A_T_A = np.dot(A_T, A)eig_value_A_T_A, eig_vector_A_T_A = np.linalg.eig(A_T_A)# 将特征向量进行正交化处理得到右奇异向量矩阵VV = eig_vector_A_T_AV_norms = np.array([np.linalg.norm(v) for v in V.T])V = (V.T / V_norms).T# 计算奇异值矩阵Sigma,按照降序排列eig_value_sort_idx = np.argsort(eig_value_AA_T)[::-1]eig_value_sort = eig_value_AA_T[eig_value_sort_idx]Sigma = np.zeros_like(A, dtype=np.float64)Sigma[:len(eig_value_AA_T), :len(eig_value_AA_T)] = np.sqrt(np.diag(eig_value_sort))# 返回左奇异向量矩阵U、奇异值矩阵Sigma和右奇异向量矩阵Vreturn U, Sigma, V.TARIMA
# 加载时间序列数据
# 示例数据
date_rng = pd.date_range(start='2022-01-01', end='2022-12-31', freq='D')
data = pd.DataFrame(date_rng, columns=['date'])
data['value'] = np.random.randn(len(date_rng))#可视化原始时间序列
plt.figure(figsize=(10, 6))
plt.plot(data['date'], data['value'], label='Original Time Series')
plt.title('Original Time Series Data')
plt.xlabel('Date')
plt.ylabel('Value')
plt.legend()
plt.show()# 差分操作,使序列平稳
differenced_data = data['value'].diff().dropna()#确定ARIMA模型的阶数
# 绘制ACF图
plot_acf(differenced_data)
plt.title('Autocorrelation Function (ACF)')
plt.show()# 绘制PACF图
plot_pacf(differenced_data)
plt.title('Partial Autocorrelation Function (PACF)')
plt.show()# 拟合ARIMA模型
p, d, q = 1, 1, 1 # 根据ACF和PACF的结果设置p和q的值
arima_model = ARIMA(data['value'], order=(p, d, q))
arima_result = arima_model.fit()#模型诊断
print(arima_result.summary())# 模型预测
forecast_steps = 10
forecast = arima_result.get_forecast(steps=forecast_steps)
forecast_index = pd.date_range(data['date'].iloc[-1], periods=forecast_steps + 1, freq='D')[1:]
forecast_values = forecast.predicted_mean# 绘制原始数据和预测结果
plt.figure(figsize=(12, 8))
plt.plot(data['date'], data['value'], label='Original Time Series')
plt.plot(forecast_index, forecast_values, color='red', label='ARIMA Forecast')
plt.title('ARIMA Model Forecast')
plt.xlabel('Date')
plt.ylabel('Value')
plt.legend()
plt.show()总结
综合论文内容和实验结果,可以看出该混合模型通过结合扩展的ARIMA模型、EMD和SVD,有效地提升了空气质量预测的准确性和效率。该模型不仅能处理多变量和高波动性的数据,还能通过其分解和压缩机制有效减少计算资源的消耗。这一新方法为城市空气质量的动态预测提供了一种可行且高效的技术路径,特别是在资源受限的环境中具有重要的实用价值。通过对该文献的学习,我更加明确了在进行时间序列分析时,综合使用多种方法和技术的重要性,以及在处理实际问题时对方法进行适当调整和优化的必要性。
这篇关于第五十四周:文献阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!