本文主要是介绍[技术报告]InternLM2 Technical Report,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
像ChatGPT和GPT-4这样的大型语言模型(llm)的进化引发了人们对人工通用智能(AGI)出现的讨论。然而,在开源模型中复制这种进步一直是一个挑战。本文介绍了InternLM2,这是一个开源的大语言模型,通过创新的预训练和优化技术,在6个维度和30个基准的综合评估、长上下文建模和开放式主观评估方面优于之前的研究。InternLM2 的预训练过程非常详细,重点介绍了包括文本、代码和长上下文数据在内的各种数据类型的准备。InternLM2 有效地捕捉了长期依赖关系,在预训练和微调阶段,最初在 4k tokens 上进行训练,然后逐步增加到 32k tokens,在 200k 的“Needle-in-a-Haystack”测试中表现出色。InternLM2 通过监督微调 (SFT) 和一种新颖的条件在线人类反馈强化学习 (COOL RLHF) 策略进一步对齐,该策略解决了人类偏好冲突和奖励黑客问题。通过发布不同训练阶段和模型大小的 InternLM2 模型,我们为社区提供了模型演变的见解。
1.介绍
自从 ChatGPT 和 GPT-4(OpenAI,2023)推出以来,大型语言模型(LLMs)在学术界和工业界的受欢迎程度激增。训练了数十亿个标记的模型表现出深刻的共情能力和解决问题的能力,这导致了人们普遍猜测人工通用智能(AGI)时代可能即将到来。尽管人们充满热情,但开发出具备与 ChatGPT 或 GPT-4 相当能力的模型的道路依然难以捉摸。开源社区一直在努力弥合专有 LLM 和其开源对应模型之间的差距。在过去的一年里,几个值得注意的开源 LLM,如 LLaMA(Touvron 等,2023a;b)、Qwen(Bai 等,2023a)、Mistral(Jiang 等,2023)和 Deepseek(Bi 等,2024),取得了显著的进展。在本文中,我们介绍了 InternLM2,一种新的大型语言模型,它优于前述的模型。
大型语言模型(LLMs)的开发包括几个主要阶段:预训练、监督微调 (SFT) 和来自人类反馈的强化学习 (RLHF)(Ouyang 等,2022)。预训练主要利用大量自然文本语料库,积累数万亿个标记。此阶段旨在为 LLMs 配备广泛的知识库和基本技能。在预训练期间,数据质量被认为是最关键的因素。然而,过去关于 LLMs 的技术报告(Touvron 等,2023a;b;Bai 等,2023a;Bi 等,2024)很少涉及预训练数据的处理。InternLM2 详细说明了如何为预训练准备文本、代码和长上下文数据。
如何有效地扩展大型语言模型(LLMs)的上下文长度是当前的一个热点研究课题,因为许多下游应用,如基于检索的生成(RAG)(Gao 等,2023)和代理(Xi 等,2023),依赖于长上下文。InternLM2 首先采用组查询注意力(GQA),以在推理长序列时实现更小的内存占用。在预训练阶段,我们最初用4k上下文文本训练 InternLM2,然后将训练语料转换为高质量的32k文本进行进一步训练。完成后,通过位置编码外推(LocalLLaMA,2023),InternLM2 在200k上下文中的“ “Needle-in-a-Haystack”测试中表现出色。
在长上下文预训练之后,我们利用监督微调 (SFT) 和来自人类反馈的强化学习 (RLHF) 来确保模型很好地遵循人类指令并与人类价值观保持一致。值得注意的是,在这些过程中,我们还构建了相应的32k数据,以进一步提升 InternLM2 的长上下文处理能力。此外,我们引入了条件在线 RLHF (COOL RLHF),该方法采用条件奖励模型来调和多样但可能存在冲突的偏好,并在每个阶段通过多轮执行近端策略优化 (PPO) 来缓解新出现的奖励黑客问题。为了阐明 RLHF 在社区中的影响,我们还发布了 RLHF 之前和之后的模型,分别命名为 InternLM2-Chat-{size}-SFT 和 InternLM2-Chat-{size}。
我们的贡献是双重的,不仅突出了模型在不同基准上的卓越性能,也突出了我们在不同阶段开发模型的全面方法。要点包括:
-
开源性能卓越的 InternLM2:我们开源了不同规模的模型,包括1.8B、7B和20B,这些模型在主观和客观评估中均表现良好。此外,我们还发布了不同阶段的模型,以便社区分析 SFT 和 RLHF 训练后的变化。
-
设计有 200k 上下文窗口:InternLM2 展现了令人印象深刻的长上下文性能,在200k上下文的“Needle-in-a-Haystack”实验中几乎完美地识别出所有“针”。此外,我们提供了在所有阶段(包括预训练、SFT 和 RLHF)中训练长上下文 LLMs 的经验。
-
全面的数据准备指南:我们详细说明了 LLMs 的数据准备,包括预训练数据、特定领域增强数据、SFT 数据和 RLHF 数据。这些细节将有助于社区更好地训练 LLMs。
-
创新的 RLHF 训练技术:我们引入了条件在线 RLHF (COOL RLHF) 来协调各种偏好,显著提升了 InternLM2 在各种主观对话评估中的性能。我们还对 RLHF 的主观和客观结果进行了初步分析和比较,为社区提供关于 RLHF 的见解。
2.基础设施
在这部分中,我们介绍了在预训练,SFT和RLHF阶段中使用的训练框架InternEvo。
2.1InternEvo
我们使用 InternEvo来进行模型训练,这是一种高效且轻量级的预训练框架。该框架使我们能够在数千个 GPU 上扩展模型训练。这是通过结合数据并行(Shoeybi 等,2019)、张量并行、序列并行(Korthikanti 等,2023)和流水线并行(Huang 等,2019)来实现的。为了进一步提高 GPU 内存效率,InternEvo 集成了各种零冗余优化器 (ZeRO)(Rajbhandari 等,2020)策略,显著减少了训练所需的内存占用。此外,为了提高硬件利用率,我们引入了 FlashAttention 技术(Dao,2023)和 BF16 混合精度训练(Narang 等,2017)。
InternEvo 在跨数千个 GPU 训练 InternLM 时展示了强大的扩展性能。如图 1 所示,当在 8 个 GPU 上训练 InternLM-7B 并使用全局批处理大小为 400 万标记时,InternEvo 实现了 64% 的模型 FLOPs 利用率(MFU)。将训练规模扩大到 1024 个 GPU,InternEvo 在相同的全局批量规模下保持了令人印象深刻的 53% 的 MFU。达到这种扩展性能水平尤其具有挑战性,因为批处理大小保持不变,且计算与通信的比率随着 GPU 数量的增加而降低。相比之下,当使用 ZeRO-1(Rajbhandari 等,2020)和 MiCS(Zhang 等,2022)在 1024 个 GPU 上训练 InternLM-7B 时,DeepSpeed(Rasley 等,2020)仅能实现约 36% 的 MFU。

InternEvo 也显示出很强的序列长度扩展能力,在训练不同大小的 LLM 时支持 256,000 个令牌。例如,当训练序列长度为 256,000 个令牌的 InternLM-7B 模型时,InternEvo 可以实现近 88% 的模型 FLOPs 利用率(MFU)。相比之下,DeepSpeed-Ulysses 和 Megatron-LM 的 MFU 仅达到约 65%。这种训练性能的提高在更大规模的 LLM 中也得到了体现,例如具有 300 亿或 700 亿参数的模型。
减少通信开销 在分布式 LLM 训练中,内存利用率与通信成本之间存在权衡。最初,通过减少通信规模可以有效降低通信成本。这包括将通信限制在较小的 GPU 组内,可能在同一节点内,从而减轻整体通信成本。在此原则基础上,InternEvo 通过实施一套自适应分片技术来解决通信挑战,以实现强大的扩展性能(Chen 等,2024b)。这些技术包括全复制、全分片和部分分片,使模型状态的每个组件——参数、梯度和优化器状态——能够独立选择最适合的分片方式和设备网格配置。这种灵活性有助于在 GPU 基础设施上更精细地分配模型状态。InternEvo 还引入了一个优化框架,旨在识别最有效的分片因素,在遵循 GPU 内存限制的同时尽量减少通信开销。
通信-计算重叠为了进一步减少通信开销,InternEvo战略性地协调通信和计算,以优化整体系统性能。在采用参数分片时,模型的所有参数分布在多个GPU上,以节省GPU内存。在每个训练步骤的前向和后向传播过程中,InternEvo通过AllGather高效预取即将计算的层的完整参数集,同时计算当前层。生成的梯度在参数分片组内通过ReduceScatter同步,随后在参数分片组之间通过AllReduce同步。这些通信过程巧妙地与后向计算重叠,从而最大限度地提高训练流水线的效率。在优化器状态分片的情况下,GPU通过Broadcast在分片组内广播更新的参数,InternEvo在下一训练步骤的前向计算过程中战略性地进行重叠。这些创新的重叠方法有效地平衡了通信开销和计算执行时间,从而显著提升了整体系统性能。
长序列训练长序列训练的主要挑战之一是计算速度和通信开销之间的权衡。InternEvo将GPU内存管理分解为具有四个并行维度(数据、张量、序列和流水线)和三个分片维度(参数、梯度和优化器状态)的分层空间(Chen et al., 2024a)。我们对每个维度的内存和通信成本进行了深入分析,利用执行模拟器来识别和实施最佳并行化策略。基于训练规模、序列长度、模型大小和批量大小,最佳执行计划可以自动搜索。通过这一执行计划,InternEvo在训练过程中能够处理长上下文(最多100万个token)。InternEvo还实施了内存管理技术,以减少长序列训练场景中常见的GPU内存碎片化问题。它使用一个内存池进行统一的内存管理,并引入了一种碎片整理技术,主动整合小内存块以防止内存不足错误。
容错性我们还解决了在GPU数据中心高效训练大规模语言模型(LLM)时面临的挑战,这些数据中心经常遇到频繁的硬件故障、复杂的并行化策略和资源利用不均衡等问题。为了解决这些问题,我们对GPU数据中心的六个月LLM开发工作负载跟踪进行了深入的特征研究(Hu et al., 2024)。这项研究识别了LLM与以前的深度学习工作负载之间的差异,探讨了资源利用模式和作业失败的影响。基于我们的分析,我们引入了两项系统努力:一个通过LLM参与的故障诊断和自动恢复来增强容错性的预训练系统,以及一个为评估任务提供及时模型性能反馈的解耦调度系统。在我们的实现中,我们采用了一种异步保存机制,定期将模型权重和优化器状态归档到分布式文件和对象存储中。在整个训练过程中,每个GPU首先将其模型状态保存到本地存储,随后异步将这些数据上传到远程分布式存储系统。这种双步骤过程确保在我们的系统自动检测到偶发的硬件或网络故障时,只有最少的训练进度会丢失。为了优化存储空间,我们系统地将这些临时模型检查点从热存储转移到成本效益高的冷存储中。此外,我们的系统设计能够在并行化配置发生变化时无缝恢复模型训练,提供训练流水线中的灵活性和连续性。
交互式训练 InternEvo的效率在基于人类反馈的强化学习(RLHF)阶段也得到了成功验证,此时多个大规模语言模型(LLM)被部署进行交互式训练。例如,在近端策略优化(PPO)过程中,我们利用四个等大小的模型并训练其中两个;InternEvo使每个模型都能在其最佳配置下执行。为了增强多个模型的协调性,我们开发了一个基于InternEvo和Ray的创新RLHF框架。该框架具有灵活性和可扩展性,能够在大规模下有效运行。它能够与各种LLM执行引擎集成,并支持多种算法设计。有关“对齐”概念的详细描述,请参见第4节。
2.2模型结构
Transformer(Vaswani et al., 2017)由于其出色的并行化能力,一直是以往大型语言模型(LLMs)的主要支柱,该能力能够充分利用GPU的强大性能(Brown et al., 2020; Chowdhery et al., 2023; Zeng et al., 2023)。LLaMA(Touvron et al., 2023a)在变压器架构的基础上进行了改进,用RMSNorm(Zhang & Sennrich, 2019)替换了LayerNorm(Ba et al., 2016),并将激活函数设置为SwiGLU(Shazeer, 2020),从而提高了训练效率和性能。自从LLaMA(Touvron et al., 2023a)发布以来,社区积极参与扩展围绕LLaMA架构构建的生态系统。这包括在高效推理(lla, 2023)和操作优化(Dao, 2023)等方面的进展。为了确保我们的模型InternLM2与这个成熟的生态系统以及其他著名的LLMs(例如Falcon(Almazrouei et al., 2023)、Qwen(Bai et al., 2023a)、Baichuan(Yang et al., 2023)、Mistral(Jiang et al., 2023))无缝对接,我们选择遵循LLaMA的结构设计原则。为了提高效率,我们整合了Wk、Wq和Wv矩阵,在预训练阶段实现了超过5%的训练加速。此外,为了更好地支持多样化的张量并行(tp)转换,我们重新配置了矩阵布局。我们没有简单地堆叠Wk、Wq和Wv矩阵,而是采取了每个头部的Wk、Wq和Wv交错排列的方法,如图2所示。这种设计修改便于通过沿最后一个维度分割或连接矩阵调整张量并行大小,从而增强了模型在不同分布式计算环境中的灵活性。InternLM2旨在推理超过32K的上下文,因此,InternLM2系列模型都采用了分组查询注意力(GQA)(Ainslie et al., 2023),使其能够在处理非常长的上下文时既保持高速也节省GPU内存。

3 预训练
在这部分中,我们将介绍预训练数据、预训练设置以及三个预训练阶段。
3.1 预训练数据
大语言模型(LLMs)的预训练在很大程度上受到数据的影响,这呈现出多方面的挑战。这包括处理敏感数据、涵盖全面的知识以及平衡效率和质量。在本节中,我们将描述我们的数据处理流程,用于准备通用领域文本数据、与编程语言相关的数据以及长文本数据。
3.1.1 文本数据
我们的预训练数据集中的文本数据可以根据来源分为网页、论文、专利和书籍。为了将这些来源转换为预训练数据集,我们首先将所有数据标准化为特定格式,按类型和语言分类,并以JSON Lines(jsonl)格式存储。然后,对所有数据应用几个处理步骤,包括基于规则的过滤、数据去重、安全过滤和质量过滤。这导致了一个丰富、安全且高质量的文本数据集。
数据源分布:我们根据来源对预训练数据集中的文档数量、数据存储大小和数据字节比例进行了统计分析,如表1所示。其中,来自网页的中英文数据占总量的86.46%,是主要来源。尽管来自其他来源的数据量相对较小,例如书籍和技术文献(简称为techlit),但平均文档长度更长且内容质量相对较高,这使得它们同样重要。

数据处理流程本工作使用的数据处理流程如图3所示。整个数据处理流程首先从不同来源标准化数据以获得格式化数据。然后,使用启发式统计规则进行数据过滤以获得干净数据。接下来,使用局部敏感哈希(LSH)方法进行数据去重,以获得唯一数据。
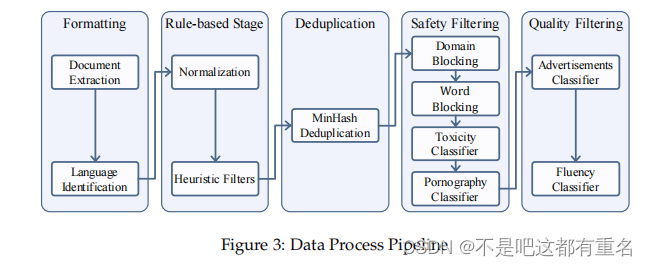
去重后的数据然后,我们应用综合安全策略过滤数据,得到安全数据。针对不同来源的数据,我们采用了不同的质量过滤策略,最终获得高质量的预训练数据。
数据格式化我们将以网页数据为例,详细介绍数据处理流程。我们的网页数据主要来自Common Crawl。首先,我们需要解压原始的Warc格式文件,并使用Trafilatura(Barbaresi, 2021)进行HTML解析和主文本提取。然后,我们使用pycld2库进行主文本的语言检测和分类。最后,我们为数据分配一个唯一标识符,并将其存储为jsonl(JSON lines)格式,从而获得格式化数据。
基于规则的阶段从互联网上随机提取的网页数据通常包含大量低质量数据,如解析错误、格式错误和非自然语言文本。常见的做法是设计基于规则的正则化和过滤方法来修改和过滤数据,如Gopher(Rae et al., 2021)、C4(Dodge et al., 2021)和RefinedWeb(Penedo et al., 2023)中所见。基于我们对数据的观察,我们设计了一系列启发式过滤规则,重点关注分隔符和换行中的异常、异常字符的频率以及标点符号的分布。通过应用这些过滤器,我们获得了干净数据。
去重互联网上存在大量重复文本,这会对模型训练产生负面影响。因此,我们采用了一种基于局部敏感哈希(LSH)的方法对数据进行模糊去重。更具体地说,我们使用了MinHash方法(Broder, 1997),在文档的5-gram上建立了128个哈希函数的签名,并使用0.7作为去重阈值。我们旨在保留最新的数据,即优先考虑具有较大CC转储编号的数据。在LSH去重后,我们获得了去重数据。
安全过滤互联网上充斥着有害和色情内容,使用这些内容进行模型训练会对性能产生负面影响,并增加生成不安全内容的可能性。因此,我们采用了综合安全策略,结合**“域名屏蔽”、“词语屏蔽”、“色情分类器”和“毒性分类器”**来过滤数据。具体来说,我们构建了一个包含大约1300万个不安全域名的屏蔽域名列表和一个包含36,289个不安全词语的屏蔽词列表,用于初步数据过滤。鉴于词语屏蔽可能会无意中排除大量数据,我们在编制屏蔽词列表时采取了谨慎的方法。
为了进一步提高不安全内容的检测率,我们使用Kaggle的“Toxic Comment Classification Challenge”数据集微调了BERT模型,得到一个毒性分类器。我们从去重数据中抽取了一些数据,并使用Perspective API进行了标注,创建了一个色情分类数据集。然后,我们用这个数据集微调了BERT模型,得到了一个色情分类器。最后,我们使用这两个分类器对数据进行二次过滤,过滤掉得分低于阈值的数据,从而获得安全数据。
质量过滤与书籍、论文和专利等来源相比,互联网来源的数据包含大量低质量内容。根据我们的观察,这些低质量内容的主要原因有两个:1. 互联网上充斥着营销广告,这些广告往往是重复的,信息量很少。2. 许多网页由文章摘要或产品描述列表组成,导致提取的文本难以阅读且缺乏逻辑连贯性。
为了过滤掉这些低质量内容,我们首先组织了人工数据标注。对于广告分类任务,标注员被要求识别一段数据是否包含广告内容(无论是整体广告还是部分广告都被标记为低质量)。对于流利度分类任务,标注员被要求从一致性、噪音、信息内容和语法四个维度对数据进行评分,从而得到一个综合的流利度评分。然后,我们使用手动标注的数据微调了BERT模型,得到一个广告分类器和一个流利度分类器。最后,我们使用这两个分类器对数据进行二次过滤,过滤掉得分低于阈值的数据,从而获得高质量的预训练数据。
3.1.2代码数据
编程对于大型语言模型(LLM)来说是一项关键技能,它支持各种下游应用,如代码辅助、软件开发和构建工具使用代理。此外,Groeneveld等人(2024)指出,通过训练代码数据有可能增强推理能力,因为代码通常比自然语言更结构化、严谨和可预测。
数据源分布:我们从各种来源收集数据,包括直接从GitHub爬取、公共数据集以及与编码和编程相关的在线资源,如问答论坛、教程网站和API文档,统计数据如图4所示。表2反映了基于我们训练的评分模型的数据质量评估。高质量数据将具有较高的采样权重,并且可以在预训练阶段进行多次训练迭代。中等质量的数据具有正常的采样权重,通常只训练一次。低质量数据被排除,因为我们的实验证实,尽管它们的比例相对较小,但去除它们对于优化模型性能和确保训练稳定性至关重要。
格式清理:所有数据都转换为统一的Markdown格式。然而,仍有极小部分数据表现出损坏的HTML或XML格式。我们应用了一套启发式规则以尽量减少这些情况,尽管我们没有投入太多精力在格式净化上。选择Markdown是因为其简单性——最小化了格式化的token开销——以及它与交错代码和自然语言的兼容性。


用于预训练的实际格式更加复杂,涉及基于依赖关系连接多个代码文件。主要思想是利用交错数据,这对于教授模型编程至关重要。这一点在最近的研究中也有提及(Guo et al., 2024)。
数据去重:代码数据的去重与处理自然语言类似,但在分词方面有所不同,这会影响超参数选择。例如,Python示例使用两个空格、四个空格或制表符来表示缩进。传统的空白分词器或为自然语言定制的分词器可能会错误地将这些样本评估为不同的数据,这是不准确的。我们的见解是,一个有效的分词器对于应用通用去重策略至关重要。尽管最近的研究探索了在段落或行级别进行细粒度去重,我们的方法仍然保持在文件级别,以保持上下文的完整性。
质量过滤质量是大型语言模型(LLM)研究中的一个关键但模糊的方面,主要是因为难以量化其对模型性能的影响。我们采用了混合的多阶段过滤过程,包括基于规则和基于模型的评分器。基于规则的评分器是启发式的并且多种多样,尽管我们发现代码风格不是一个可靠的质量指标,因为它可能会错误地将太多代码归类为低质量。对于基于模型的评分,我们评估了几个主干模型,用大约50,000个标记样本对它们进行了训练。然而,我们观察到评分器评估与人工判断之间的相关性在不同语言中有所不同,并且扩大训练集并未显著提高评分器的准确性。因此,我们仅在模型预测与人工评估在人工标注的验证集上高度一致的语言中使用基于模型的评分。
为了获得可靠的基于模型评分器的注释,我们引入了一个迭代注释过程(如图5所示),以解决代码质量数据定义模糊的问题。识别对LLM教学有帮助的代码对于人类专家来说也并非易事,例如,一个广泛认可的代码库可能对初学者来说过于复杂。提出的迭代工作流程允许注释者验证模型预测并相应地细化指南。为了提高注释效率,我们只要求注释者检查评分器高置信度标记为高质量和低质量的样本。此外,每次迭代都有一个自动验证过程,以确保之前标注的样本被评分器正确分类,如图中黄色虚线所示。实际上,我们进行了三次迭代来最终确定我们的评分模型。

依赖排序 InternLM2的训练上下文窗口已扩展至32,000个token,允许利用代码库的整个上下文。由于在之前的数据处理步骤中,如按扩展名过滤代码文件和去重,代码库的结构可能已被破坏。因此,我们首先重新组合来自同一代码库的代码文件,并执行依赖排序,以建立这些文件的连接顺序。因此,一个代码库将被视为一个包含代码块的长Markdown文件,这使得模型能够学习跨文件的依赖关系。
我们使用正则表达式来检测各种编程语言中的“import”关系,并使用拓扑排序来确定文件的连接顺序。在实践中,文件的排列可能会打破文件夹边界,导致来自多个子文件夹的文件交错排列。非代码文件,如Markdown和其他文档文件,被放置在同一子文件夹中的第一个代码文件之前。对于像多个路径连接祖先和后代以及“import”关系图中的循环这样的特殊情况,我们对前者采取较短路径,对于后者使用字母顺序决定起始点。在寻找“import”关系时的一个技巧是解决批量导入,例如“init.py”或“#include xx.h”。这些文件可能导入了一堆未使用的依赖项,因此我们应用启发式规则来优化“import”关系的检测,确保我们在更细的层面上准确识别和处理这些关系。
3.1.3 长上下文数据
处理超长上下文(>32K个token)的能力在大型语言模型(LLMs)的研究中越来越受欢迎,拓宽并促进了应用,如书籍摘要、支持长期对话以及处理涉及复杂推理步骤的任务。预训练数据是扩展模型上下文窗口的一个关键因素。我们遵循了Lv等人(2024)中提到的准备长文本预训练数据的过程,并进行了额外的实验和讨论。以下文本仅概述了用于InternLM2的数据准备过程。
数据过滤流程我们的数据处理流程旨在过滤掉低质量的长文本数据。它包含三个阶段:
a) 长度选择:一个基于规则的过滤器,选择超过32K字节的数据样本;
b) 统计过滤器:利用统计特征识别和去除异常数据;
c) 困惑度过滤器:利用困惑度差异评估文本段落之间的连贯性,过滤掉具有干扰性上下文的样本。需要注意的是,所有用于长上下文训练的数据都是标准预训练语料库的子集,这意味着长上下文数据将在预训练期间至少学习两次。
统计过滤器我们采用了各种词汇和语言特征来构建我们的统计过滤器。不符合既定规则的数据样本将被排除在预训练语料库之外。所有这些过滤器的完整列表可在Lv等人(2024)中找到。一个显著的过滤器是连接词和其他暗示话语结构的词语的存在,如“尤其”、“正式”等。设计这些过滤器的总体指导原则是过滤掉无意义的数据,而不是选择最高质量的数据。统计过滤器在长文本数据中特别有效,因为统计特征比短文本数据更加一致。例如,一个20个token的文本可能不会产生可靠的统计数据,但一个32K token的文本将具有更清晰的统计特征分布。
困惑度过滤器困惑度通常被视为文本序列概率P(X)的估计器,我们稍微改变其用法,以估计两个文本段落之间的条件概率P(S2|S1),其中S1在S2之前。当S1和S2高度相关时,条件概率应高于单独估计S2的概率,这也意味着负的困惑度差异。相反,如果概率反向变化,意味着S1是一个干扰性上下文,则应将其从预训练语料库中删除。理想情况下,增加更多上下文不应对后续文本的可预测性产生负面影响。然而,我们观察到在某些不适当连接文本的情况下存在例外,如失败的HTML解析、随机社交媒体片段以及源自复杂布局的识别错误等。需要注意的是,我们仅基于困惑度差异过滤数据,而不是困惑度本身,这可以大大减轻估计器本身引入的偏差(使用哪个模型计算困惑度)。困惑度估计器的偏差已在Wettig等人(2024);Sachdeva等人(2024)中讨论。
阈值选择选择适当的阈值是数据过滤过程中一个具有挑战性但至关重要的部分,这一挑战因为我们建立了许多过滤器而变得更加严峻。我们在设置阈值时有两条经验:
- 为每个领域量身定制阈值,而不是寻求通用解决方案。例如,连接词的统计过滤器不适用于长代码数据,因为代码通常没有任何连接词。同样,教科书、研究论文、小说和专利各自表现出独特的特征。通用阈值可能会错误分类大量数据。同样的逻辑也适用于为不同语言设置阈值;因此,我们为每个领域单独调整阈值。
- 使用验证集来简化过程,仅关注边界案例。与基于学习的特征提取器或评分器不同,我们的统计和困惑度过滤器在同一领域内产生平滑的结果。这使我们能够专注于接近阈值的样本,简化阈值的调整,因为我们只需要确定是降低还是提高它们。Lv等人(2024)展示了数据集群及其来自特定过滤器的评分,展示了我们提出的过滤器的可解释性。
图6展示了应用所有提出的过滤器前后的数据分布。整个过滤过程消除了大量网页数据(Common Crawl)和专利数据,而大部分书籍和论文数据得以保留。

3.2预训练设置
在这部分我们展示了标记化和预训练的超参数。
3.2.1分词
我们选择使用GPT-4的分词方法,因为它在压缩各种文本内容方面具有卓越的效率。我们的主要参考是cl100k词汇表,该词汇表主要包含英文和编程语言的tokens,总计100,256个条目,另外还包括少于3,000个中文tokens。为了在处理中文文本时优化InternLM的压缩率,同时保持整体词汇量在100,000以下,我们仔细选择了cl100k词汇表中的前60,004个tokens,并整合了32,397个中文tokens。此外,我们还包括了147个备用tokens,最终的词汇量与256的倍数对齐,从而促进高效训练。
3.2.2预训练超参数
表3列出了基本的超参数。在训练过程中,使用AdamW(洛什奇洛夫& Hutter,2019)和β1 = 0.9、β2 = 0.95、ϵ= 1e−8和重量衰减= 0.1对模型进行优化。我们使用余弦学习率衰减和学习率衰减到其最大值的10%。
3.3预训练阶段
用于预训练1.8B、7B和20B模型的总tokens数量范围为2.0T到2.6T,预训练过程分为三个不同的阶段。在第一阶段,我们使用长度不超过4K的预训练语料。在第二阶段,我们包括了50%长度不超过32K的预训练语料。在第三阶段,我们使用了特定能力增强数据。在每个阶段,我们混合了英文、中文和代码数据。
3.3.1 4k上下文训练
在大约90%的训练步骤中,我们使用长度最多为4096个tokens的数据进行训练。如果数据长度超过4096个tokens,我们会强制截断并使用剩余部分进行训练。
3.3.2 长上下文训练
扩展上下文窗口的使用显著增强了大型语言模型(LLMs)在各种应用中的性能,例如检索增强生成(Gao et al., 2023)和智能代理(Xi et al., 2023)。受训练长上下文的最新进展(Rozière et al., 2023;Xiong et al., 2023;Liu et al., 2023b)启发,我们的InternLM2训练过程从4K上下文语料开始,随后过渡到32K上下文语料。与仅使用32K语料不同,50%的数据仍然短于4096个tokens。这一长上下文训练阶段占总步骤的约9%。在适应这些更长的序列时,我们将旋转位置编码(RoPE)的基数从50,000调整到1,000,000,以确保对长上下文进行更有效的位置编码(Liu et al., 2023b)。由于InternEvo(Chen et al., 2024a)和闪存注意力(Dao, 2023)的良好可扩展性,将上下文窗口从4K更改为32K时训练速度仅降低了40%。
3.3.3 特定能力增强训练
推理、数学问题解决和知识记忆等能力是对大型语言模型的关键期望。然而,在预训练过程中,与能力相关的高质量数据在整个语料库中分布稀疏,这使得模型难以在这些能力上熟练。之前的工作,如Qwen(Bai et al., 2023a)、GLM-130B(Zeng et al., 2023)、Nemotron-4(Parmar et al., 2024),尝试在预训练阶段结合基于指令或高质量数据来增强这些能力。在InternLM2中,我们收集了一个丰富的数据集,该数据集精心策划了高质量检索数据和来自Huggingface数据集平台的各种开源数据的混合。总共我们在这个数据集中收集了240亿个tokens,语料库的详细信息如表4所示。我们过滤掉了与测试集相关的数据,并按照第5.4节所述进行了污染测试。为了使模型更好地适应这些数据,我们采用了较小的学习率和批量大小。

在这个增强训练阶段之后,InternLM2模型在编码、推理、问答和考试等方面表现出显著的性能提升,详细的评估结果将在后续的评估部分中展示。为了帮助研究社区,我们发布了增强训练前后的检查点,分别命名为InternLM2-{size}-Base和InternLM2-{size}。
4.对齐
预训练阶段为大型语言模型(LLMs)提供了解决各种任务所需的基础能力和知识。我们进一步微调LLMs,以充分发挥其能力,并引导LLMs作为有用且无害的AI助手。这一阶段通常被称为“对齐”,通常包含两个阶段:监督微调(SFT)和基于人类反馈的强化学习(RLHF)。在SFT阶段,我们通过高质量的指令数据微调模型,使其能够遵循各种人类指令(见4.1节)。然后,我们提出了条件在线RLHF(COnditionalOnLine RLHF),它应用了一种新颖的条件奖励模型,可以调和不同类型的人类偏好(例如,多步推理的准确性、有用性、无害性),并进行三轮在线RLHF以减少奖励操纵(见4.2节)。在对齐阶段,我们通过在SFT和RLHF过程中利用长上下文预训练数据,保持LLMs的长上下文能力(见4.3节)。我们还介绍了提高LLMs工具使用能力的实践(见4.4节)。
4.1监督微调
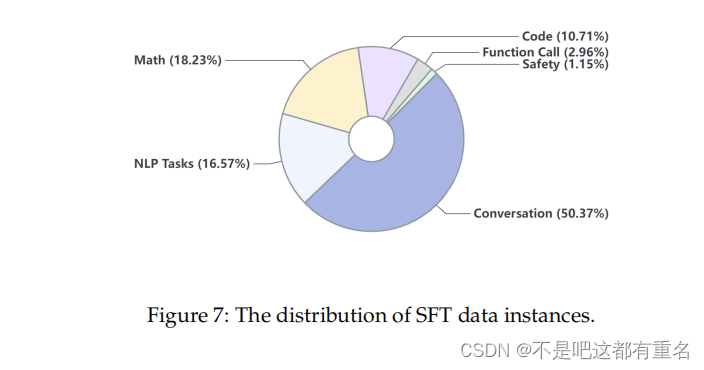
在监督微调(SFT)阶段,我们使用了一个包含1000万个指令数据实例的数据集,这些数据已被筛选以确保其有用性和无害性。数据集涵盖了广泛的主题,包括一般对话、NLP任务、数学问题、代码生成和函数调用等。图7显示了SFT数据主题的详细分布。为了便于表示各种任务,我们将数据样本转换为ChatML(Cha)格式。7B和20B模型都使用AdamW优化器进行一个epoch的训练,初始学习率为4e-5。
4.2 COOL Reinforcement Learning from Human Feedback
基于人类反馈的强化学习(RLHF)(Christiano et al., 2017;Ouyang et al., 2022)是大型语言模型领域的一种创新方法。通过结合人类反馈,RLHF创建奖励模型,作为人类偏好的代理,从而为大型语言模型(LLMs)提供奖励信号,通过使用近端策略优化(PPO)(Schulman et al., 2017)进行学习。这种方法使模型能够更好地理解和执行难以通过传统方法定义的任务。
尽管RLHF取得了显著成就,但在实际应用中仍存在一些问题。首先是偏好冲突。例如,在开发对话系统时,我们希望它提供有用的信息(有用性),同时不产生有害或不适当的内容(无害性)。然而,这两种偏好在实践中往往不能同时满足,因为提供有用信息可能在某些情况下涉及敏感或高风险内容。现有的RLHF方法(Touvron et al., 2023b;Dai et al., 2023;Wu et al., 2023)通常依赖多个偏好模型进行评分,这也引入了更多的模型到训练流程中,从而增加了计算成本并减慢了训练速度。其次,RLHF面临奖励操纵的问题,尤其是当策略随着规模增加而变得更强大时(Manheim & Garrabrant, 2018;Gao et al., 2022),模型可能会通过捷径“欺骗”奖励系统以获得高分,而不是真正学习期望的行为。这导致模型以非预期的方式最大化奖励,显著影响了LLMs的有效性和可靠性。
为了解决这些问题,我们提出了条件在线RLHF(COOL RLHF)。COOL RLHF首先引入了条件奖励机制,以调和多种偏好,使奖励模型能够根据特定条件动态分配其注意力到各种偏好,从而最佳地整合多种偏好。此外,COOL RLHF采用多轮在线RLHF策略,使LLM能够及时适应新的人工反馈,减少奖励操纵的发生。
4.2.1条件奖励模型
条件奖励模型代表了对之前RLHF方法中偏好建模挑战的创新解决方案。与传统方法通常依赖多个偏好模型来解决不同领域中的偏好冲突(图8(a))不同,条件奖励模型为不同类型的偏好引入了不同的系统提示,从而在一个单一的奖励模型中有效地建模各种偏好。
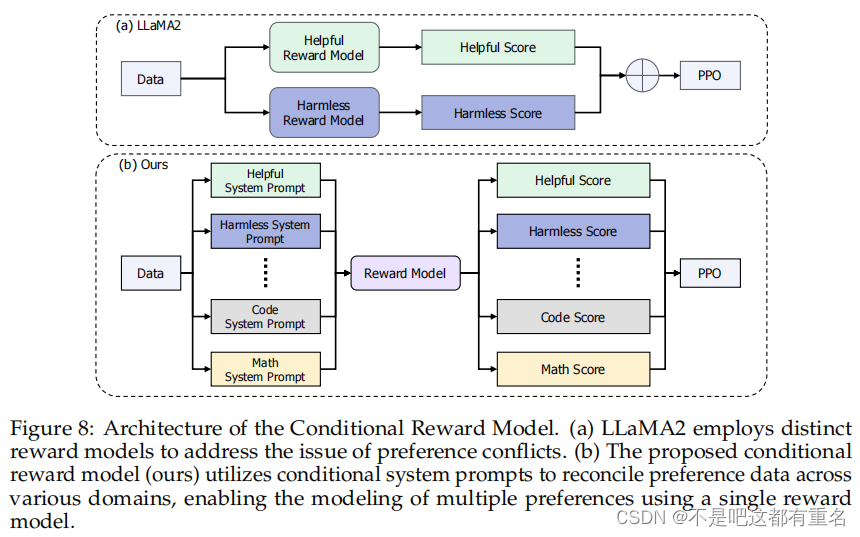
具体来说,如图8(b)所示,条件奖励模型采用不同的系统提示来无缝融合来自各个领域的数据。由于奖励模型是从一个已经学会遵循各种人类指令的SFT模型初始化的,我们也让奖励模型遵循不同的系统提示,以适应不同场景的多样化偏好。在条件奖励模型中,系统提示不仅是其输入的一个组成部分,还是指导奖励分数在不同场景中与特定偏好对齐的重要工具。这种整合有助于在一个统一的奖励模型中管理矛盾和复杂的人类偏好,而不会牺牲准确性。
数据组成条件奖励模型的训练过程涉及一个广泛的数据集,涵盖了对话、文章写作、诗歌、摘要、编码、数学和格式化输出等各个领域,包含多达240万个二值化偏好对。这一综合数据集确保了模型的广泛适应性,并增强了其在更广泛和复杂的情况下进行强化学习的能力。因此,通过采用条件系统提示方法,奖励模型可以响应复杂的人类需求,在PPO阶段提供更细致的奖励分数控制。
损失函数此外,为了减少数据集中简单样本和困难样本之间的不平衡影响,我们借鉴Focal Loss(Lin et al., 2017)对原始排序损失函数(Burges et al., 2005)进行了修改。我们在排序损失中添加了一个难度衰减系数,使得对困难样本的损失值更大,对简单样本的损失值更小,从而防止在大量简单样本上过拟合。焦点排序损失的公式如下:
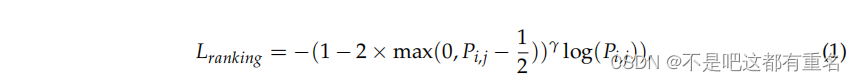
其中, P i , j = σ ( r i − r j ) P_{i,j} = \sigma(r_i - r_j) Pi,j=σ(ri−rj) 表示rewardi大于rewardj的概率。难度衰减系数仅在模型正确预测训练样本的偏好时生效,即 P i , j > 0.5 P_{i,j} > 0.5 Pi,j>0.5,否则等于1。参数 γ \gamma γ表示一个用于调节难度衰减比率的超参数,这里我们默认将其设置为2。同时,为了确保奖励模型在不同训练过程中输出分数的稳定性和一致性,我们引入了对奖励分数的对数障碍惩罚,将分数分布限制在-5到5的范围内,其定义如下:
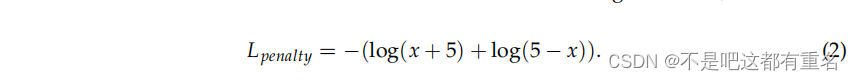
这个约束非常关键,因为它避免了在PPO阶段由于不同奖励模型的奖励分数分布变化而需要修改额外的奖励相关超参数。总体而言,奖励模型的损失函数如下:

参数 λ \lambda λ 是一个权重系数,用于平衡 L ranking L_{\text{ranking}} Lranking 和 L penalty L_{\text{penalty}} Lpenalty 的贡献。基于我们在初步实验结果中的观察,我们将其默认设置为0.02。这些改进提高了奖励模型的鲁棒性和一致性,特别是在简单和困难样本不平衡的数据集上下文中。
训练细节在我们的实验中,我们将奖励模型的大小与PPO中使用的行为模型的大小对齐。按照InstructGPT(Ouyang et al., 2022)中描述的方法,我们使用SFT模型的权重初始化奖励模型,并将输出层修改为一个一维的线性映射层,该层随机初始化。我们的批次构建策略侧重于将每个批次的偏好数据总长度固定在16384个tokens,而不是限制偏好对的数量,以避免由于数据填充导致的训练效率低下。最大上下文长度设置为8192。每个序列的末尾附加一个特殊token,其输出值用作奖励分数。
我们采用AdamW作为优化器。学习率遵循余弦退火调度,从1e-5降低到5e-6,权重衰减设置为0.01。为了防止过拟合,模型训练一个epoch。
4.2.2 在线RLHF
在获得条件奖励模型后,我们进行近端策略优化(PPO),以使LLMs与奖励模型所建模的人类偏好对齐(Ouyang et al., 2022)。为了应对PPO阶段的奖励操纵挑战,我们引入了一种在线RLHF方法,分为两个不同的路径:快速路径和慢速路径。快速路径用于即时、针对性的改进,而慢速路径用于奖励模型的长期、全面优化。这两个路径相辅相成,提供了一个自适应框架,以减轻奖励操纵并提高通过人类反馈训练的LLMs的性能和可靠性。
快速路径在线RLHF中的快速路径侧重于通过针对性修补快速识别和纠正奖励操纵事件,以提高奖励模型的可靠性。随着PPO训练的进行,LLMs倾向于向高奖励区域靠拢,这通常会暴露更多容易检测到的奖励操纵场景。在每轮RLHF后识别出操纵模式后,我们通过比较当前轮次中早期和晚期PPO模型生成的响应来构建偏好对,这些偏好对突出了这些模式。将20到100个这样的偏好对纳入训练过程,足以显著防止奖励模型对应的操纵模式。这一过程允许快速修正奖励模型对新出现的操纵行为,从而增强奖励模型的可靠性和对预期结果的遵循。
慢速路径与快速路径专注于修复奖励操纵不同,慢速路径旨在通过覆盖LLMs的最新和最有能力模型生成的响应,全面提升奖励模型的上限,特别是在高奖励区域的可靠性和鲁棒性,参考了之前的工作(Bai et al., 2022)。为此,使用训练不同阶段的模型(包括SFT模型、早期PPO模型和晚期PPO模型)生成的响应来形成成对比较。然后呈现给专业的人类标注员来标注他们的偏好。
这种过程为奖励模型提供了更细致和彻底的改进,但需要大量的人类标注时间。为了提高在线RLHF的效率,我们仅使用实验开始时所有先前模型的累积人类偏好数据(即,由于人类标注的时间成本,可能不包括当前轮次模型生成的响应的偏好数据)。通过基于人类反馈的持续更新,慢速路径确保奖励模型与人类偏好的复杂性和微妙性同步发展。
实现在我们的在线RLHF实现中,我们进行了三轮优化。在这些循环中,我们在快速路径中收集了数千个偏好补丁和在线偏好数据以更新奖励模型,并使用了先前模型响应的所有现有人类偏好数据。每轮在线RLHF都提供了宝贵的见解,使我们能够动态调整和优化奖励模型,从而提高通过人类反馈训练的语言模型的整体性能和可靠性。
4.2.3 PPO训练细节
在RL对齐阶段,我们采用了标准的PPO(近端策略优化)算法,并对其进行了几项调整,以确保更稳定的训练过程。该框架涉及四个模型:行为模型、评论模型、参考模型和奖励模型。在训练过程中,后两个模型是冻结的,只有前两个模型是主动训练的。值得注意的是,这些模型的大小都是相同的,以确保它们在处理和生成数据时的一致性。我们在大约400次迭代中遍历了约20万个多样化的查询,并在验证集上选择最佳检查点进行发布。
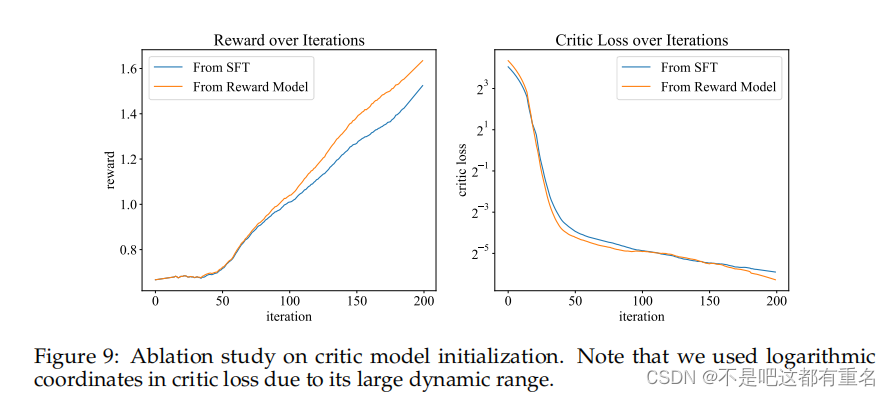
模型初始化与常见做法一样,我们从SFT模型权重初始化参考模型和行为模型。评论模型从奖励模型(不包括线性头)初始化,并经历50次迭代的预训练阶段,在此期间行为模型被冻结。这个阶段对于稳定早期训练中的价值估计至关重要,从而防止不稳定价值的潜在有害影响。我们进行了消融研究,比较了从奖励模型和SFT模型初始化评论模型的效果,如图9所示。结果表明,从奖励模型初始化的评论模型在PPO训练的前几次迭代中经历了更大的损失,但在大约20次迭代后,它表现出更低的损失,并为行为模型带来了更高的奖励。我们假设在初始阶段观察到的更高损失可能揭示了奖励建模任务和评论建模任务之间的根本差异。随后更低的损失可能归因于对世界知识的更一致的内部理解和对评估原则的更好把握。
条件奖励如前所述,我们的奖励模型经过训练能够适应各种条件。因此,对于来自不同领域的查询,在计算奖励分数之前,我们在每个采样响应前添加适当的条件系统提示,如图10所示。这一做法确保了模型的响应与不同领域的各种需求在上下文上保持一致。

预训练梯度为了减轻在PPO阶段发生灾难性遗忘的风险,我们引入了预训练损失,遵循InstructGPT的方法。预训练损失的系数设置为0.5,预训练数据的量约为PPO训练数据的50%。这种添加有助于保留模型在初始训练阶段获得的知识,确保模型在适应新反馈和通过PPO学习的过程中保留其基础能力和知识库。
超参数我们将KL散度系数设置为0.01。行为模型和评论模型的学习率分别设置为1e-6和5e-6。我们发现,PPO中的较大λ值在我们的案例中会带来更高的奖励,因此我们将其设置为0.99。我们采用了稍微保守的采样策略,top_p设置为0.9,以平衡采样多样性和收敛速度。与一些传统方法不同,我们没有应用价值损失剪裁或优势归一化。尽管采用了大量RL技巧,训练仍然非常稳定,这部分归功于我们细致的在线RLHF工作。
4.3 长上下文微调
为了在微调后保持LLMs的长上下文能力,我们在SFT和RLHF中继续使用长上下文预训练数据,这受到之前采用长上下文预训练语料在SFT中的工作的启发(Xiong et al., 2023)。具体来说,我们利用两种类型的数据:一种是来自书籍的长上下文数据,另一种是从GitHub代码库中获得并通过特定范式连接的长上下文数据,描述如下。
为了增强InternLM2的数据分析能力,我们选择了DS-1000(Lai et al., 2023)中使用的代码库作为核心代码库,这些代码库包括Pandas、Numpy、Tensorflow、Scipy、Scikit-learn、PyTorch和Matplotlib。然后,我们在GitHub上搜索了引用这些核心代码库并拥有超过10,000颗星的代码库,并进行了与预训练相同的过滤和数据清理过程。对于每个代码库,我们首先使用深度优先方法对获取的原始数据进行排序,同时生成简要描述文件内容的必要提示,如图11所示。随后,我们按顺序连接处理后的数据,直到达到32k的长度。实验结果表明,长上下文代码数据不仅提高了LLMs的长上下文能力,还提高了代码能力。

4.4 Tool-Augmented LLMs
通用工具调用我们采用了修改版的ChatML格式,通过引入“环境”角色来实现通用工具调用。这种修改在聊天场景中采用相同的格式,但在采用代理时为模型提供了更清晰的信号。此外,我们定义了两个特定关键词来支持AI代理的多样化用途,即代码解释器(<code_interpreter>)和外部插件(<external_plugin>)。这使我们能够采用统一的流式格式来处理各种类型的插件扩展和AI环境,同时兼容普通聊天。图17展示了流式聊天格式的具体示例。为了充分发挥InternLM2的代理能力,我们将代理语料库与聊天领域对齐,并按照语言模型的基本能力进行细化训练,如Agent-FLAN(Chen et al., 2024c)中所述。
代码解释器我们还通过代码解释器增强了InternLM2-Chat解决数学问题的能力,将Python代码解释器视为一种特殊工具,使用与工具学习中描述的相同模式。我们采用了与编码交错的推理(RICO)策略,并以迭代的困难样本挖掘方式构建数据,如InternLM-Math(Ying et al., 2024)中所述。
5.评估与分析
5.1概览
在本节中,我们将对语言模型在各个领域和任务中的表现进行全面评估和分析。评估分为两个主要类别:(a)下游任务和(b)对齐。对于每个类别,我们进一步细分为具体子任务,以提供对模型优势和劣势的详细了解。最后,我们讨论语言模型中的数据污染问题及其对模型性能和可靠性的影响。除非另有明确说明,所有评估均使用OpenCompass(Contributors, 2023b)进行【6】。
5.2 下游任务的表现
我们首先详细介绍多个NLP任务的评估协议和性能指标。我们介绍数据集,解释实验设置,然后展示结果并进行深入分析,与最先进的方法进行比较,以展示我们模型的有效性。性能评估将通过六个关键维度进行剖析:(1)综合考试,(2)语言和知识,(3)推理和数学,(4)多编程语言编码,(5)长上下文建模,(6)工具使用。
5.2.1 综合考试
我们在一系列与考试相关的数据集上进行了基准测试,这些数据集包括:
- MMLU(Hendrycks et al., 2020):一个包含57个子任务的多选题数据集,涵盖人文学科、社会科学、STEM等主题。我们报告5-shot结果。
- CMMLU(Li et al., 2023a):一个特定于中国的多选题数据集,包含67个子任务。除了人文学科、社会科学、STEM等,它还包括许多特定于中国的任务。我们报告5-shot结果。
- C-Eval(Huang et al., 2023):一个包含52个子任务和4个难度级别的多选题数据集,涵盖人文学科、社会科学、STEM等主题。我们报告5-shot结果。
- AGIEval(Zhong et al., 2023):一个以人为中心的基准测试,包含多选题和开放性问题。这些问题来自20个官方、公开和高标准的入学和资格考试,针对普通人类考生,并报告0-shot结果。
- GAOKAO-Bench(Zhang et al., 2023):一个包含2010年至2022年中国高考(Gaokao)的数据集,包括主观题和客观题。我们只评估了客观题数据集,并报告0-shot结果。

评估结果
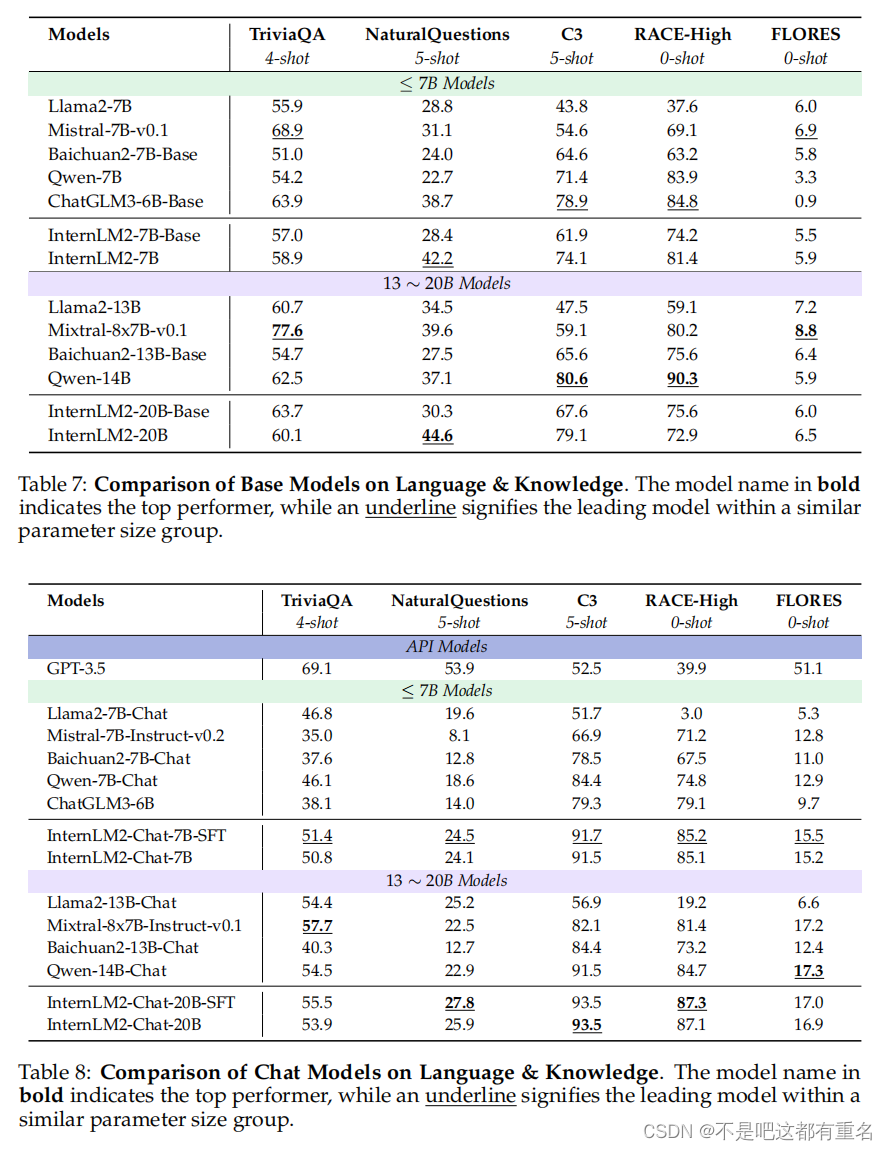
我们在表5中报告了基础模型的结果,在表6中报告了聊天模型的结果。
对于基础模型,InternLM2系列在参数数量相似的模型中表现良好。在7B和20B模型上,InternLM2相对于InternLM2-Base显示出显著提升,这证明了在通用领域数据和领域增强语料库上的预训练在综合考试中具有优势。对于AGIEval和GAOKAO任务,这些任务来自专门为人类设计的考试,InternLM2相对于InternLM2-Base相比其他数据集显示出更大的提升。
对于聊天模型,InternLM2系列在参数数量相似的模型中也表现出色。通过比较InternLM2-Chat-7B-SFT和InternLM2-Chat-7B模型,可以看出COOL RLHF对综合考试性能影响不大。
5.2.2 语言和知识
- TriviaQA(Joshi et al., 2017):一个包含阅读理解和开放域问答的数据集。平均每个问题有6个可能的答案。我们使用了数据的开放域问答子集,并报告0-shot结果。
- NaturalQuestions(Kwiatkowski et al., 2019):一个问答数据集,问题来自用户,答案由专家验证。我们报告0-shot结果。
- C3(Sun et al., 2020):一个自由形式多选题的中文机器阅读理解数据集。我们报告0-shot结果。
- RACE(Lai et al., 2017):一个阅读理解数据集,包括中国初中和高中学生(12至18岁)的英语阅读理解考试问题。我们使用高中生子集,并报告0-shot结果。
- FLORES(Team et al., 2022):一个从维基百科提取的翻译数据集,涵盖101种语言。我们评估了从英语到其他100种语言及其反向翻译的结果。对于每对翻译任务,我们选择100个样本并使用BLEU进行评估。我们报告8-shot结果。
评估结果
我们在表7中报告了基础模型的结果,在表8中报告了聊天模型的结果。得益于其严格和高质量的训练语料库,InternLM2在涉及语言理解和知识应用的任务中表现出了显著的竞争优势。因此,它成为在多个现实世界应用中依赖强大语言理解和广泛知识的绝佳选择。
5.2.3 推理与数学
在本节中,我们主要验证InternLM2在推理和数学方面的性能,重点关注以下两个部分的测试集:
推理数据集:
- WinoGrande(Sakaguchi et al., 2020):一个常识推理数据集,包含44,000道二选一的多选题。它要求模型根据场景选择描述性文本中代词的适当实体词。
- HellaSwag(Zellers et al., 2019):一个用于评估常识自然语言推理的具有挑战性的数据集,包含70,000道多选题。每个问题都呈现一个场景和四个可能的结果,要求选择最合理的结论。
- BigBench Hard (BBH)(Suzgun et al., 2023):一个针对大型语言模型的测试集合,BBH从BIG-Bench中提取了23个具有挑战性的任务,当时的语言模型尚未超过人类表现。
数学数据集:
- GSM8K-Test(Cobbe et al., 2021):一个包含约1,300道小学水平的情境数学问题的数据集。这些问题的解决涉及2到8个步骤,主要使用基本算术运算(加、减、乘、除)进行一系列基本计算以得出最终答案。
- MATH(Hendrycks et al., 2021):一个包含12,500道具有挑战性的高中水平竞赛数学问题的数据集,涵盖从代数到微积分的多个领域。每个问题都包括一个完整的逐步解决方案。
- TheoremQA(Chen et al., 2023a):一个以定理驱动的STEM问答数据集,包含800对问答对,涵盖数学、电气与计算机工程、物理和金融领域的350多个定理。它测试了大型语言模型在应用定理解答具有挑战性的大学水平问题上的局限性。
- MathBench(Anonymous, 2024b):MathBench包含3709个问题,具有逐渐增加挑战的多个阶段。每个阶段包括双语的理论和应用导向问题,每个问题都精确标记了一个三级标签,以指示其细粒度的知识点。
在推理和数学问题的评估中,对于多选题,我们主要采用零样本方法。对于开放性问题,如GSM8k、MATH和MathBench的开放性部分,我们主要采用少样本方法,以增强模型遵循指令的能力,从而促进答案的提取。为了确保评估结果的一致性,对于基础模型,我们主要使用困惑度(PPL)评估作为评估多选题的主要方法。
推理
推理能力反映了模型理解、处理和操作抽象概念的能力,这对于涉及复杂问题解决和决策的任务至关重要。我们在表9中分别从基础模型和聊天模型两个方面比较并展示了InternLM2的性能。
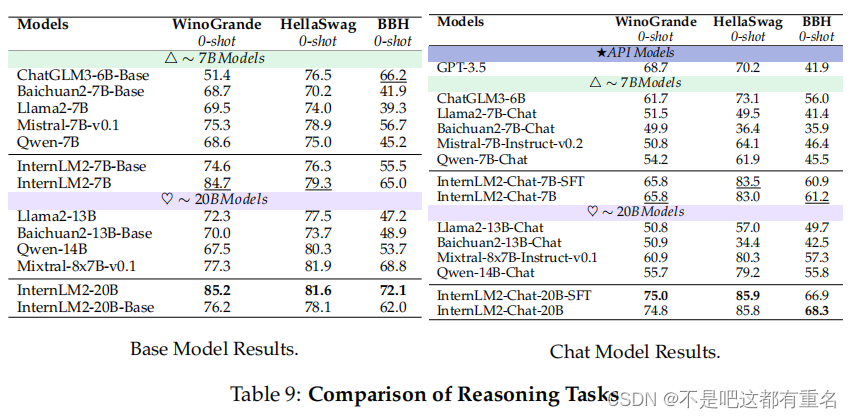
评估结果
基础模型:对于大约7B的模型,InternLM2-7B在大多数数据集(除BBH外)上表现优异。特别是其在WinoGrande上的表现(84.7)显著超越了Mistral-7B-v0.1(75.3)9.4分,仅次于其系列的InternLM2-20B(85.2)不到一分。这展示了InternLM2-7B的强大常识推理能力。在所有测试的基础模型中,InternLM2-20B取得了最佳整体表现。与InternLM2-20B-Base相比,包含领域增强知识的InternLM2-20B在常识推理方面显示出显著提升,平均在测试的推理数据集中提高了10.4%。
聊天模型:在聊天模型的推理能力方面,InternLM2继续领先,无论是在7B阶段还是在13∼20B阶段。RL模型和SFT模型在显著提升的推理能力基础上表现相似。其中,7B参数模型在三个测试集中甚至超越了大多数13∼20B模型,如Mixtral-8x7B-Instruct-v0.1和Qwen-14B-Chat,InternLM2-Chat-20B在多个推理测试集方面显著优于GPT-3.5,例如在HellaSwag上的情景推理(↑ 15.6)和BBH上的具有挑战性的综合推理(↑ 26.4),展示了InternLM2在较小规模模型中的卓越推理能力。
数学
数学能力是模型认知和计算能力的重要组成部分。在表10中,我们展示了基础模型在多个难度不同的数学评估集上的表现。在7B参数规模下,InternLM2-7B处于领先地位。具体而言,在基础算术GSM8k集中,InternLM2-7B(70.8)显著优于其他模型,超越ChatGLM3-6B-Base(60.7)10.1个百分点,几乎是InternLM2-7B-Base(36.0)表现的两倍,展示了在引入领域增强数据后,InternLM2-7B强大的基础算术能力。对于更复杂的问题解决任务,如MATH和TheoremQA中的定理证明,尽管InternLM2-7B在MATH中稍微落后,但在TheoremQA中的得分(10.5)甚至超过了更大的Qwen-14B-Base(10.4),这表明InternLM2-7B不仅在计算任务中表现出色,而且在复杂的定理证明中也表现优异。在双语数学数据集MathBench中,InternLM2在英语和中文中都表现出色。

在13∼20B参数规模阶段,InternLM2-20B在基础算术和定理证明方面优于所有测试的基础模型,而Qwen-14B-Base在问题解决任务以及MathBench的英语和中文测试中表现出色。
聊天模型
对于表11中的聊天模型,InternLM2-Chat在基础算术GSM8K、复杂应用数学MATH和理论问题TheoremQA上在7B和20B参数规模中均表现最佳。值得注意的是,经过COOL RLHF训练的InternLM2-Chat-20B在所有指标上全面领先,优于API模型GPT-3.5和MoE模型Mixtral-8x7B-Instruct-v0.1。在MathBench的双语测试中,InternLM2-Chat-20B也表现出色。
5.2.4 编码
Python编码任务
- HumanEval(Chen et al., 2021):这是一个广泛认可的数据集,用于评估代码生成模型的性能。它由164个精心设计的编程任务组成,每个任务包含一个Python函数和一个提供上下文和规格说明的文档字符串。这个数据集以人类编写的代码为特色,在评估大型语言模型(LLMs)生成或完成程序的能力方面起着关键作用。
- MBPP(Austin et al., 2021):这个数据集包含974个适合入门级程序员解决的编程任务。这些任务范围从简单的数值操作到需要外部知识的更复杂的问题,如定义特定的整数序列。我们使用MBPP的消毒版本,该版本仅包括由作者手工验证的数据子集。
多编程语言编码任务
- HumanEval-X(Zheng et al., 2023b):这是原始HumanEval基准的多语言扩展,旨在评估代码生成模型在多种编程语言中的能力。它包含164个手工制作的编程问题,每个问题被翻译成五种主要语言:C++、Java、JavaScript、Go和Python。这总共形成了820对问题解决方案,支持代码生成和代码翻译任务。HumanEval-X允许评估模型生成功能正确代码以及在不同语言之间翻译代码的能力,并使用测试用例验证生成代码的正确性。这个基准有助于更全面地理解预训练的多语言代码生成模型及其在实际编程任务中的潜在应用。
为了评估InternLM2的编码能力,我们利用广泛认可的基准MBPP(Austin et al., 2021)和HumanEval(Chen et al., 2021)进行了一系列实验。此外,为了评估代码生成模型在多种编程语言中的适应能力,我们扩展了评估范围,包括MBPP-CN,这是MBPP的中文改编版,以及HumanEval-X,这是原始HumanEval基准的多语言扩展。
如图13所示,InternLM2模型系列在这些基准测试中取得了领先表现,尤其是在HumanEval、MBPP和MBPP-CN上,InternLM2-Chat-20B模型超过了之前的最新水平10%以上,突显了InternLM2系列在代码生成任务中的卓越能力。此外,InternLM2-Chat-20B模型在MBPP-CN基准测试中相对于InternLM2-Chat-7B模型表现出显著改进,但在HumanEval-X上的表现略有下降。这种现象可能源于InternLM2-Chat-20B模型在为中文进行微调时,牺牲了其在其他语言中的有效性。
5.2.5 强化培训前后的表现
从之前部分的结果中,我们可以清楚地看到,通过特定能力增强训练的InternLM2在各方面表现均优于其对应版本。图12展示了这一阶段前后模型性能的整体比较,其中各种能力的得分来自多个评估集的平均值。
- 编码:HumanEval和MBPP。
- 推理:MATH、GSM8k、SummEdits(Laban et al., 2023)和BBH。
这些结果表明,特定能力增强训练显著提升了InternLM2在各类任务中的表现,使其在编码和推理能力方面均展现出卓越的性能。
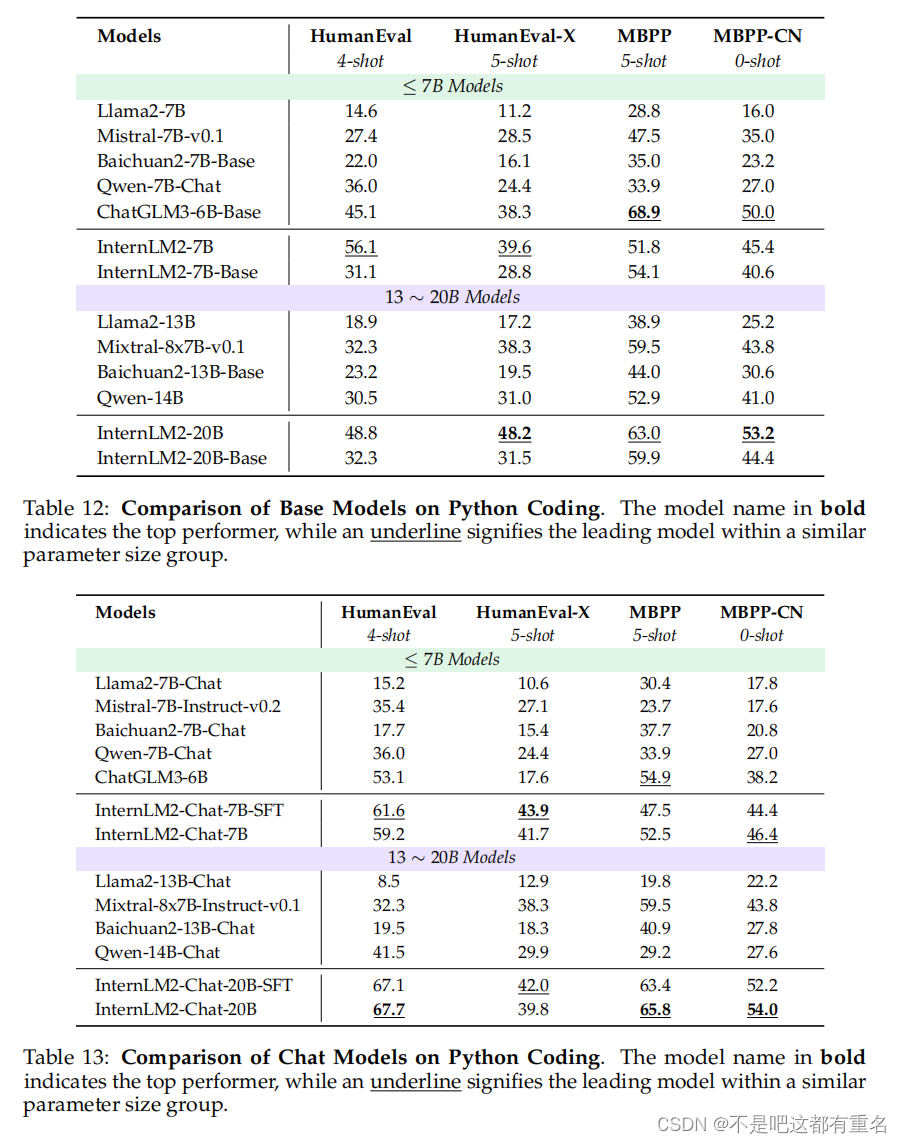
- 问答:HellaSwag、PIQA(Bisk et al., 2020)、WinoGrande、OpenBookQA(Mihaylov et al., 2018)、NaturalQuestions和TriviaQA。
- 考试:MMLU、AGIEval和C-Eval。
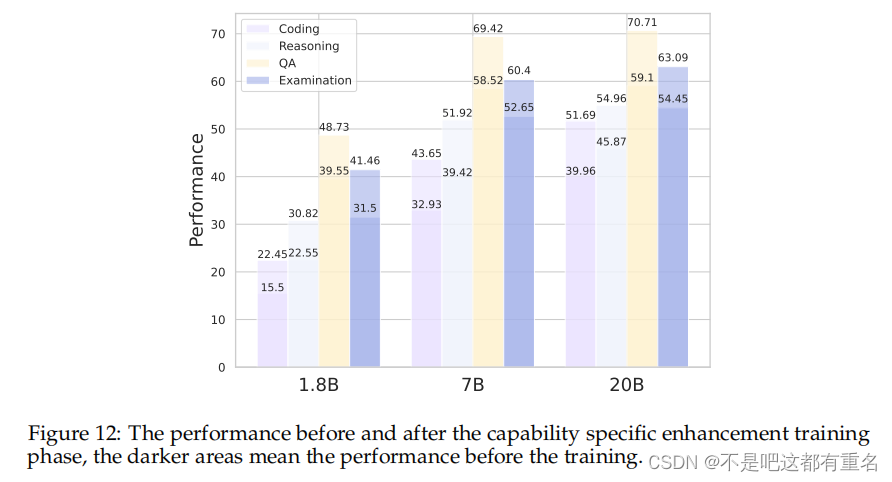
很明显,这些能力有了显著提升。此外,我们还在表14中比较了基础模型在进行特定能力增强训练前后,经过监督微调(SFT)后的性能。能力维度与OpenCompass中采用的分类一致【7】。可以观察到,经过特定能力增强训练的SFT模型在各个能力维度上都表现得更好。本报告其他部分的SFT性能基于增强训练前的基础模型。
5.2.6 长上下文建模
长上下文理解和推理我们主要在以下两个基准上评估InternLM2的长上下文建模能力:L-Eval(An et al., 2023)和LongBench(Bai et al., 2023b)。
- L-Eval:L-Eval是一个长上下文基准,包含18个子任务,涵盖法律、经济和技术等各个领域的文本。L-Eval由411个文档和超过2000个测试案例组成,平均文档长度为7217个单词。该数据集中的子任务可以分为两类:5个封闭式任务和13个开放式任务。封闭式任务使用基于精确匹配的准确率进行评估,而开放式任务采用Rouge得分作为指标。
- LongBench:LongBench是一个长上下文基准,包含21个子任务,共4750个测试案例。它是第一个双语长上下文基准,平均英语文本长度为6711个单词,平均中文文本长度为13386个字符。这21个子任务分为6种类型,提供了对模型在各个方面能力的更全面评估。
评估结果:我们在表15中报告了InternLM2在长上下文基准上的评估结果。InternLM2的所有变体在这两个基准上都表现出强大的长上下文建模性能。InternLM2-Chat-20B-SFT在L-Eval上取得了最佳表现,并大幅超越了其对比模型。在LongBench上,InternLM2-Chat-7B-SFT在6个子任务类别中的4个上优于其他≤7B模型,获得了48.1的总分,仅略低于ChatGLM3-6B的48.4总分。同时,我们注意到对于InternLM2,不同参数规模在长上下文性能上没有显著差异,这将进一步研究。
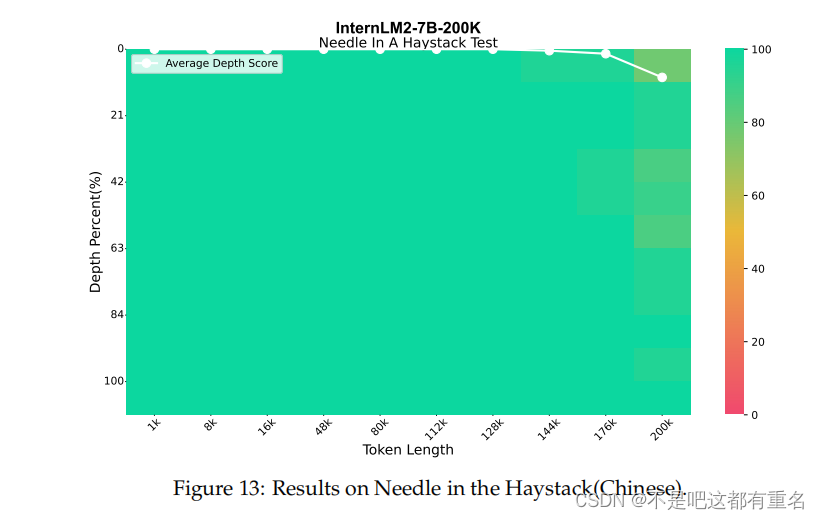
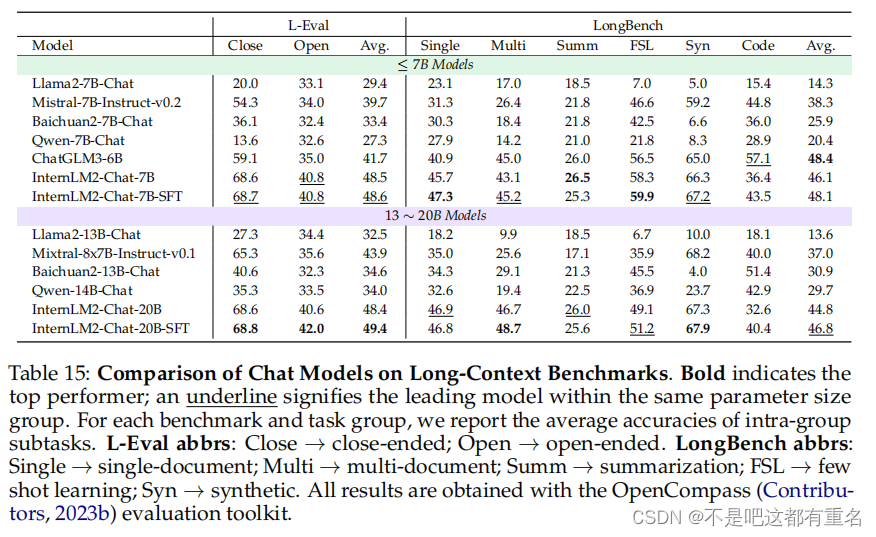
Needle-in-the-Haystack“Needle-in-the-Haystack”是一个单针检索任务,旨在测试大型语言模型(LLMs)回忆单一关键信息的能力。通过在目标长度的干草堆文本中的不同位置插入一个关键信息,然后在提示的末尾查询模型关于这个关键信息的方法,可以精确展示LLMs在不同位置和不同长度的长文本中回忆能力。我们根据原始理念设计了一个中文干草堆,并利用了由Wei等人(2023)发布的Skywork/ChineseDomainModelingEval数据集,确保了中文文本来源的多样性和质量。该数据集涵盖从金融到技术的广泛领域,提供高质量、最新的中文文章,为评估不同模型处理特定领域长文本的能力提供了一个稳定的基准。在这个实验中,我们利用了LMDeploy10 Contributors(2023a)推理引擎来加速推理过程。图13展示的结果有效地展示了InternLM2在长上下文建模方面的能力。
5.2.7 工具使用
众所周知,外部工具和API可以显著增强LLMs处理复杂现实世界问题的能力(Qin et al., 2023a;b; Schick et al., 2023)。为了分析InternLM2在工具利用方面的能力,我们在多个基准数据集上进行了实验:GSM8K(Cobbe et al., 2021)、MATH(Hendrycks et al., 2021)、最近引入的MathBench(Anonymous, 2024b)、T-Eval(Chen et al., 2023b)和CIBench的模板子集(Anonymous, 2024a),这些实验均采用ReAct协议(Yao et al., 2023),LLMs在生成思维过程和执行动作之间交替进行。特别是,MathBench包含3709个问题,涵盖从小学到高中的数学概念。该数据集使得能够全面评估LLM解决数学问题的能力。T-Eval(Chen et al., 2023b)提供了人工验证的高质量问题指令和相应的逐步解决方案,测量LLM在使用Google搜索和高德地图等日常工具中的熟练程度。CIBench由我们的团队开发,使用交互式Jupyter笔记本模拟真实数据分析场景。它包括多个连续任务,涵盖数据分析中最常用的Python模块,如Pandas、Numpy和Pytorch。这个定制的基准允许对LLM在数据分析中的综合能力进行全面评估。
GSM8K、MATH和MathBench我们使用外部代码解释器并遵循ReAct协议来评估LLM解决编码和数学问题的能力。如图14所示,使用代码解释器后,特别是在MATH数据集上,表现出了显著的改进。如图15所示,在最近引入的MathBench数据集上,使用代码解释器在大多数情况下提高了InternLM2的性能,少数情况下的性能下降可能是由于代码解释器的误用。此外,在知识领域,InternLM2-20B-Chat表现出显著的改进,而在应用部分,InternLM2-7B-Chat表现优异。这些差异可能源于它们各自训练数据集构成的不同。
T-Eval和CIBench如图16所示,InternLM2模型在各个基准上的表现始终优于或与现有模型相当。特别是,在相同规模的模型中,InternLM2-Chat-7B在T-Eval和CIBench上表现最佳。同时,InternLM2-Chat-20B在T-Eval上取得了竞争性的结果,在CIBench上获得了最高分。此外,InternLM2系列模型在中文中也取得了令人印象深刻的成绩,展示了其多语言的熟练程度。
5.3 Performance on Alignment
虽然LLMs的客观能力通过预训练和监督微调(SFT)得到了提升,但它们的回答风格可能并不符合人类的偏好,因此需要通过RLHF进一步增强对齐能力。因此,评估对齐能力对于确定LLMs是否真正满足人类需求至关重要。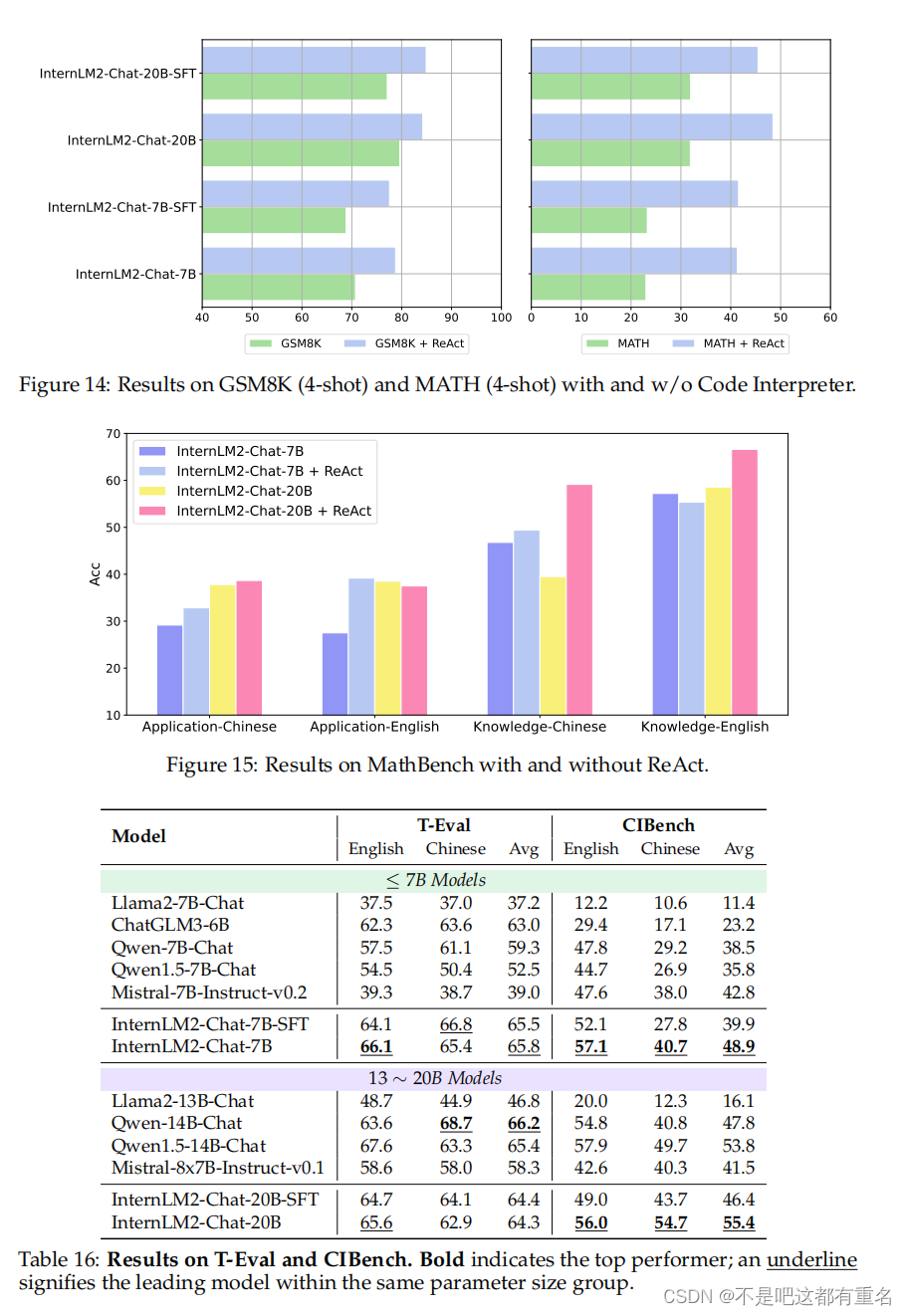
在本节中,我们评估了InternLM2在多个流行的主观对齐数据集上的表现,并比较了SFT和RLHF模型的表现。如表17所示,InternLM2在对齐任务中的整体表现达到了SOTA或接近SOTA的水平,展示了InternLM2系列模型的主观输出与人类偏好的高度一致性。我们在下文中详细介绍了每个数据集上的模型表现。此外,各数据集上用于主观对齐任务的提示模板在附录中展示。
5.3.1 英语主观评价
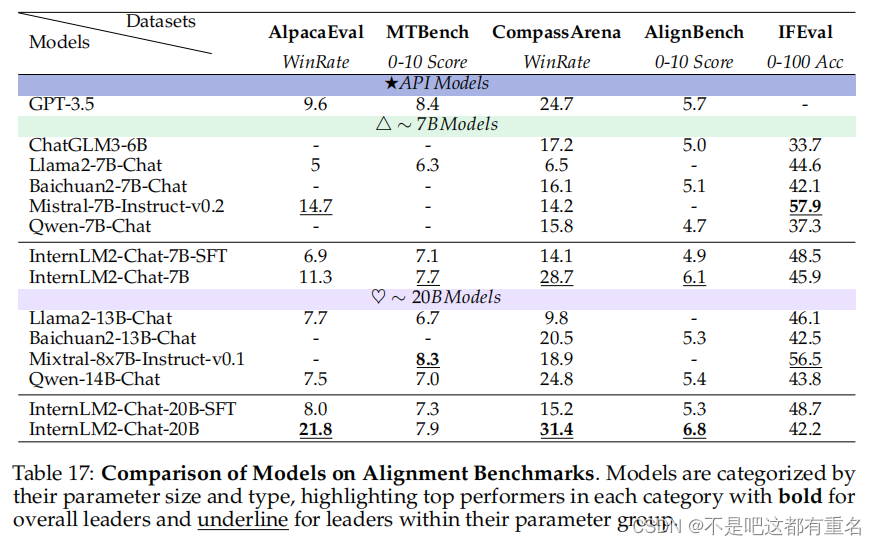
AlpacaEval AlpacaEval(Li et al., 2023b)是一个包含805个问题的单轮问答数据集。其主要目的是评估模型响应对人类的帮助程度,通过对抗性评估反映与人类意图的对齐程度。AlpacaEval(v2)建立了一个基线模型,并使用GPT4-Turbo作为评估模型,比较基线模型的答案与待评估模型的答案。它选择更符合人类偏好的模型,并计算胜率。AlpacaEval(v2)不直接收集评估模型的响应,而是使用logit概率来统计分析评估模型的偏好。这些偏好然后作为加权因子用于计算加权胜率。如表17所示,InternLM2-20B取得了21.8的胜率,在比较的模型中达到了最高的SOTA结果,展示了其卓越的对齐性能。此外,表中显示RLHF模型在胜率方面优于SFT模型,这突显了对齐策略的有效性。
MTBench MTBench(Zheng et al., 2023a)是一个包含80个问题的两轮对话数据集,涵盖八个维度:推理、角色扮演、数学、编码、写作、人文学科、STEM和信息提取。每个维度包含10个问题,需要进行两轮提问。最初测试模型回答基本问题的能力;随后,它必须遵循额外的特定指示来完善其先前的回答。评分由评估模型按1-10分进行打分。如表17所示,InternLM2在7B和20B版本中分别取得了7.7和7.9的领先分数,展示了其可靠的多轮对话能力。
5.3.2 中文主观评价
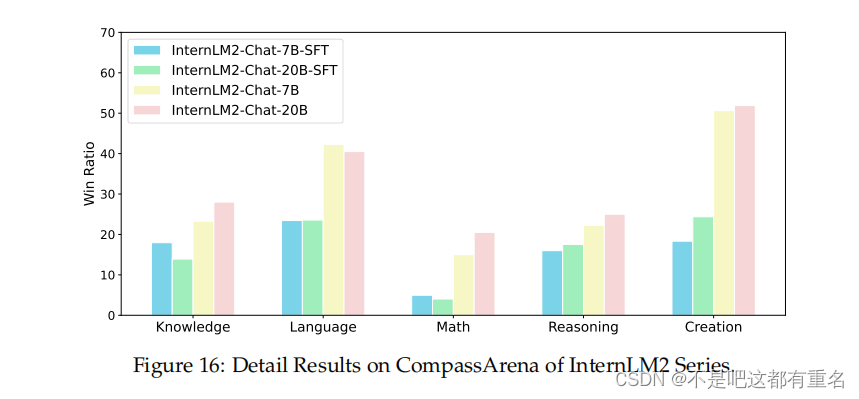
CompassArena CompassArena包括520个中文问题,涵盖知识、语言、数学、推理和创造力。与AlpacaEval类似,它计算由GPT4-Turbo评估的两个模型的胜率,并通过交换模型顺序进行双盲测试,以减轻位置偏差。如表17所示,InternLM2在7B版本(28.7)和20B版本(31.4)中均取得了最高胜率。需要注意的是,InternLM2的7B和20B版本之间的性能差距相对较小。然而,与SFT模型相比,InternLM2的RLHF模型在性能上有显著提升。这表明RLHF策略显著增强了InternLM2与人类偏好的对齐,而不仅仅是增加模型规模。此外,图16中的按类别划分的结果显示,InternLM2系列在中文创造力和语言能力方面表现出色,胜率与GPT4-Turbo相当。
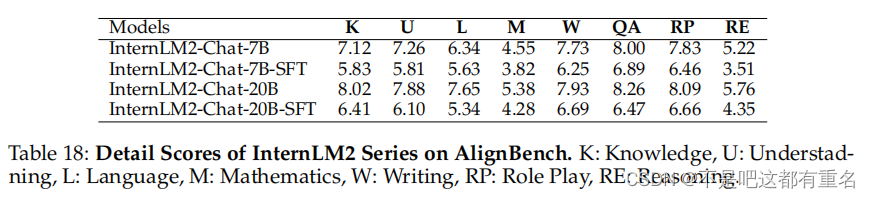
AlignBench AlignBench(Liu et al., 2023a)是一个包含683个问答对的中文主观数据集,分为八个领域,包括基本语言能力、高级中文理解、任务导向的角色扮演等,涵盖物理、历史、音乐和法律等各种场景。该数据集使用一个内部评估模型CritiqueLLM(Ke et al., 2023)进行评估。CritiqueLLM在各个维度为每个问题提供1到10的评分,并发布最终得分。我们在表17中展示了CritiqueLLM提供的这些最终得分,并在表18中展示了不同类别的详细得分。如表17所示,InternLM2在7B和20B版本中均取得了SOTA得分,分别为6.1和6.8,超过了GPT-3.5的5.7分。此外,InternLM2的7B和20B版本在RLHF后的表现相较于SFT模型有显著提升,强调了我们RLHF策略在提高模型与人类偏好的对齐方面的有效性。详细得分分析显示,数学和推理能力有待改进;然而,InternLM2在问答和角色扮演任务中表现出色,提供了强大的主观性能。
5.3.3 Instruct Following Evaluation
IFEval IFEval(Zhou et al., 2023)旨在测试模型的指令遵循能力,要求响应遵循特定模式,如字母大小写限制和关键词限制。IFEval包含25种不同类型的指令,构建了541个遵循指令的问题,并采用基于规则的评估方法来评估模型对每个问题的响应的正确性。使用各种统计方法,IFEval提供了四种准确率得分:提示级严格、提示级宽松、实例级严格和实例级宽松。我们在表17中展示了这四种得分的平均结果。虽然基于英语的模型如Llama2和Mistral在IFEval上通常优于基于中文的模型,但InternLM2在7B阶段(48.5)和13-20B阶段(48.7)分别排名第二和第三。这表明,尽管指令遵循任务具有挑战性,InternLM2在类似规模的模型中仍然保持领先地位。
5.3.4 Ablation Study of Conditional Reward Model

为了验证条件系统提示的影响,我们比较了在不同领域的异构数据混合训练的奖励模型,在使用和不使用条件系统提示时的性能。如表19所示,在多个公共数据集(包括有用和无害对话场景(Bai et al., 2022)、内容摘要(Stiennon et al., 2020)、数学问题(Lightman et al., 2023)和Reddit回复(Ethayarajh et al., 2022))中,不使用系统提示会导致精度显著下降。相反,包含系统提示在这些领域中会显著提高精度。
5.4 关于数据污染的讨论
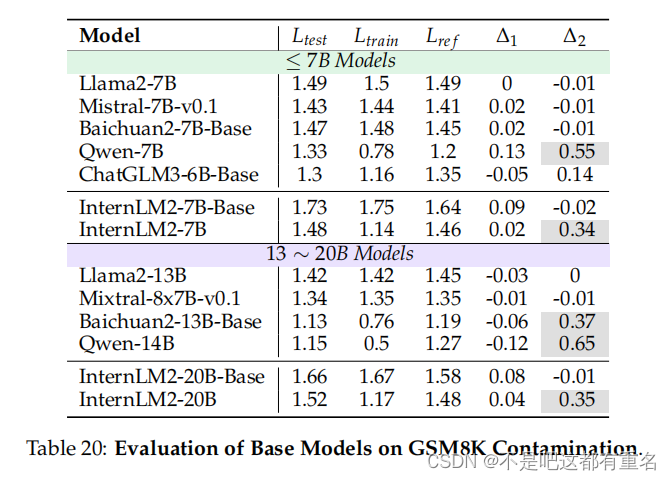
我们对多个基础模型在GSM8K数据集样本(一个样本是问题和答案的串联)上的语言建模(LM)损失进行了评估,结果如表20所示。对于每个LLM,我们比较了训练集(Ltrain)、测试集(Ltest)和由GPT-4生成的特定参考集(Lref)上的LM损失。该参考集旨在模拟GSM8K数据集。我们还报告了两个关键指标:∆1 = Ltest − Lref,用于指示LLM训练过程中可能的测试数据泄漏,即较低的值表示可能存在泄漏;以及∆2 = Ltest − Ltrain,用于衡量数据集训练集上的过拟合程度。∆2值越高,表示过拟合越严重。对于∆1和∆2的异常值在表中以灰色突出显示。表20展示了这些结果。
6 总结
在本报告中,我们介绍了InternLM2大型语言模型,该模型在主观和客观评估中均表现出色。InternLM2经过超过2万亿高质量预训练语料的训练,涵盖1.8B、7B和20B的模型规模,适用于各种场景。为了更好地支持长上下文,InternLM2采用了GQA以降低推理成本,并且经过了长达32k上下文的额外训练。除了开源模型本身,我们还提供了训练过程中各阶段的检查点,以便未来研究者进行研究。
除了开源模型外,我们还详细描述了InternLM2的训练过程,包括训练框架、预训练文本数据、预训练代码数据、预训练长文本数据和对齐数据。此外,为了解决RLHF过程中遇到的偏好冲突问题,我们提出了条件在线RLHF,以协调各种偏好。这些信息可以为如何准备预训练数据以及如何更有效地训练更大的模型提供见解。
这篇关于[技术报告]InternLM2 Technical Report的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







