本文主要是介绍k8s节点亲和性配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Kubernetes中,你可以使用节点亲和性(Node Affinity)来控制Pod调度到特定的节点上。节点亲和性是通过Pod的spec.affinity.nodeAffinity属性来设置的。
以下是一个配置节点亲和性的YAML示例:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: your-node-label-key
operator: In
values:
- your-node-label-value
containers:
- name: my-container
image: nginx
在这个例子中,nodeAffinity 指定了一个规则,要求Pod在调度时必须匹配指定的节点标签。requiredDuringSchedulingIgnoredDuringExecution 表示在Pod调度时必须满足这个规则,但在执行期间忽略。your-node-label-key 和 your-node-label-value 需要替换为实际的节点标签键和值。
要使用节点亲和性,你需要先在节点上设置标签,使用 kubectl label nodes <node-name> <label-key>=<label-value> 命令。例如:
kubectl label nodes node1 app=frontend
然后,你可以像上面展示的那样在Pod规范中配置节点亲和性,以确保Pod被调度到标签为 app=frontend 的节点上。
在k8s中,你可以约束一个 Pod 以便 限制 其只能在特定的节点上运行, 或优先在特定的节点上运行。有几种方法可以实现这点,推荐的方法都是用 标签选择算符来进行选择。 通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上, 而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制 Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上, 或者将来自两个不同的服务且有大量通信的 Pod 被放置在同一个可用区。
你可以使用下列方法中的任何一种来选择 Kubernetes 对特定 Pod 的调度:
- 与节点标签匹配的 nodeSelector
- 亲和性与反亲和性
- nodeName 字段
- Pod 拓扑分布约束
环境配置
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 11d v1.24.4
k8s-slave1 Ready <none> 11d v1.24.4
k8s-slave2 Ready <none> 11d v1.24.4
[root@k8s-master ~]#
nodeName
nodeName:
在 Kubernetes 中,NodeName 是每个 Node 节点的唯一标识符,它是一个字符串,通常是节 点的主机名(hostname)。在创建 Pod 时,可以通过指定 nodeName 字段来将 Pod 调度到特定的 Node 节点上。
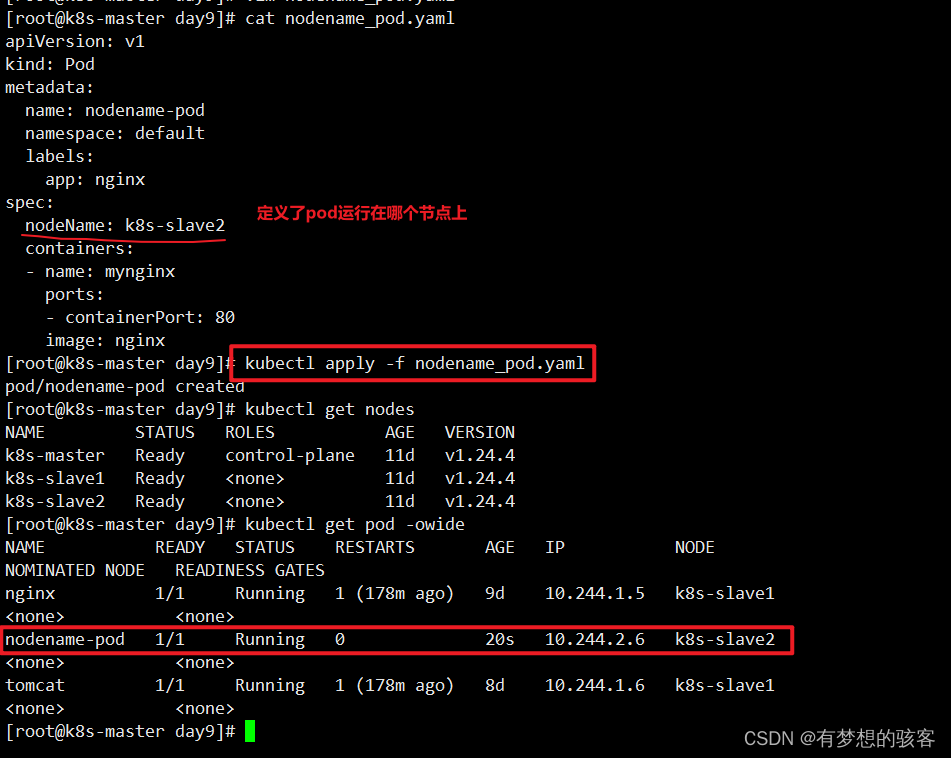
指定pod运行在哪个节点上
[root@k8s-master day9]# cat nodename_pod.yaml
apiVersion: v1 kind: Pod metadata: name: nodename-pod namespace: default labels: app: nginx spec: nodeName: k8s-slave2 containers: - name: mynginx ports: - containerPort: 80 image: nginx
nodeSelector
在 Kubernetes 中,Node 节点选择器(NodeSelector)是用来将 Pod 调度到特定节点的一种机 制。它基于 Node 节点的标签(Node Labels)来进行筛选和匹配,从而使 Pod 能够被分配到满足其要 求的节点上。
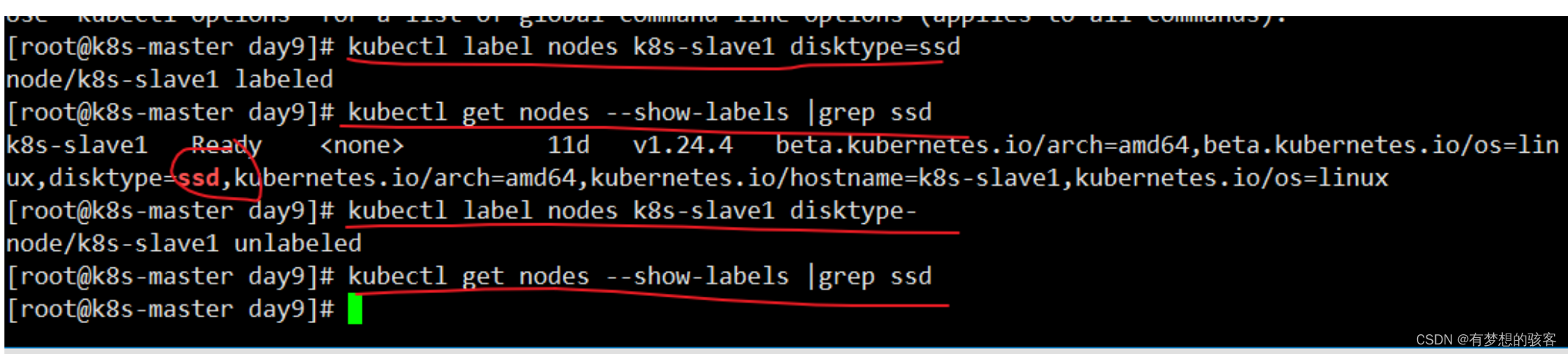
具体来说,Node 节点选择器允许用户为 Node 节点打上一组键值对标签,例如: nodeType=compute、diskType=ssd 等等。当用户在创建 Pod 时指定一个或多个 Node Selector 时,Kubernetes 调度器会根据这些选择器的键值对与 Node 节点的标签进行匹配,最终将 Pod 分配到 匹配的节点上。
例如,如果用户定义了一个 Pod 需要一个节点具有标签“nodeType=compute”,那么 Kubernetes 调度器将只会将该 Pod 调度到具有此标签的节点上。如果没有节点具有该标签,则 Pod 将 保持处于 Pending 状态直到有符合条件的节点出现。
例子展示:创建一个pod, nodeSelector选择要带ssd标签的。

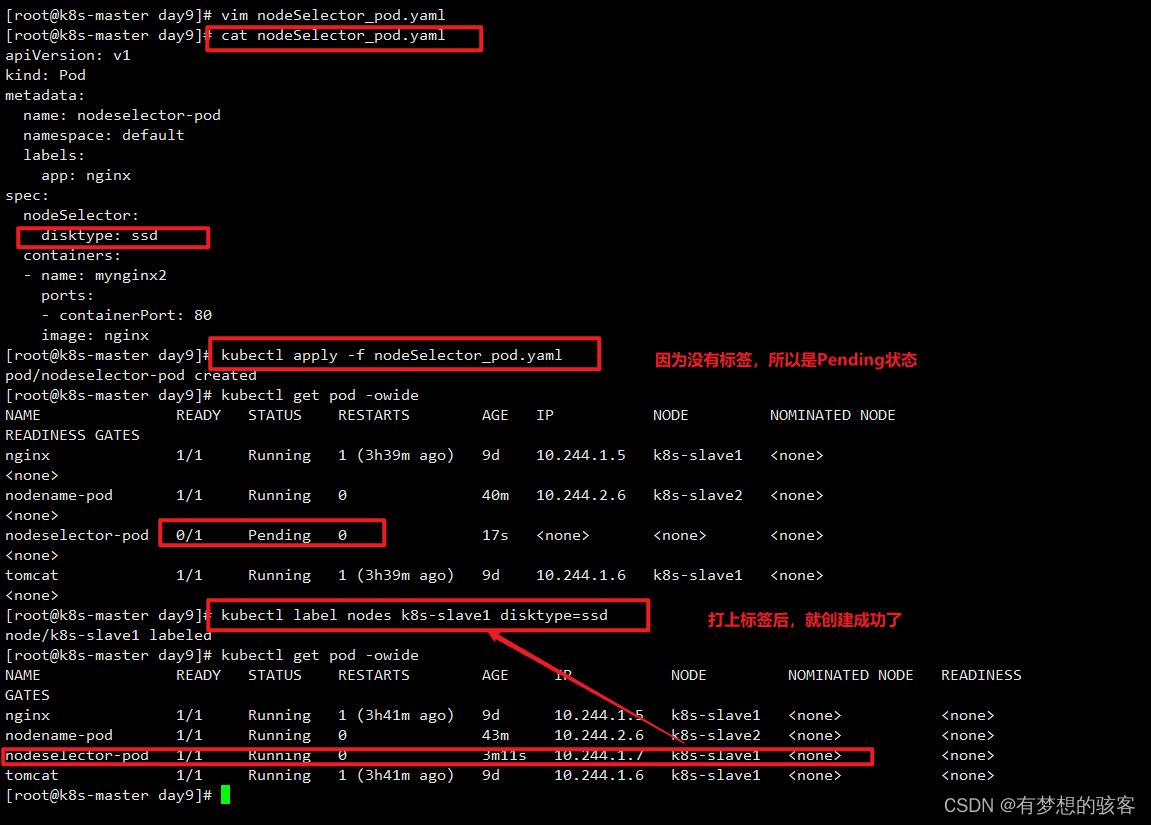

这篇关于k8s节点亲和性配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







