本文主要是介绍Kubernetes中 Requests 和 Limits 的初步理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 灵魂拷问
我们在使用 Kubernetes 时是否遇到以下情况:
- 你会不会部署负载的时候将 CPU requests/limits 设置得过低或过高?
- 你会不会部署负载的时候将 内存 requests/limits 设置得过低或过高?
- 又或者你根本不设置 requests/limits?
- request表示什么意思?limits 又是什么意思?
- CPU 设置0.5表示啥意思?为啥又有人写 500m,这又是什么情况?
- 最佳实践又是什么?
2 什么是 requests 和 limits?
我们都知道 Kubernetes 中最小的原子调度单位是Pod,那么就意味着资源管理和资源调度相关的属性都应该Pod对象的字段,其中我们最常见的就是 Pod 的 CPU 和内存配置,而为了实现 Kubernetes 集群中资源的有效调度和充分利用,Kubernetes采用 requests 和 limits 两种限制类型来对CPU和内存资源进行容器粒度的分配。
resources: limits: cpu: "1"memory: "500Mi"requests: cpu: "100m"memory: "1000Mi"下面我们首先来了解一下上面这段 yaml 文件中字段的含义:requests 和 limits:
- requests 定义了对应的容器所需要的最小资源量。
- limits 定义了对应容器最大可以消耗的资源上限。
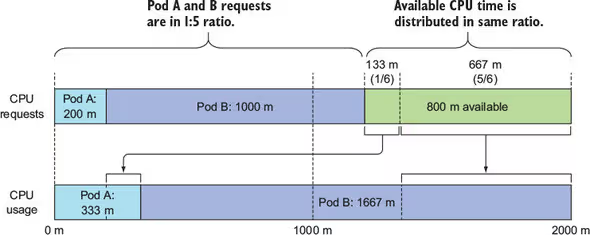
- cpu 等于1一般等同于1CPU 核心,1个VCPU或者一个超线程,具体要看服务器的CPU。而 limits 这里设置的 100m 则叫做100毫核,100m就表示0.1个核,所以这里也可以用0.1代替。
- memory 等于500Mi,(备注:1Mi=10241024;1M=10001000)
接下来我们来初步理解 requests 和 limits 这两个资源限制类型,在 Kubernetes 对 CPU 和内存资源限额的设计,通常是指用户在提交 Pod 时,可以声明一个相对较小的 requests 值供调度器使用,而 Kubernetes 真正设置给容器 Cgroups 的,则是相对较大的 limits 值。所以一般来说,在调度的时候 requests 比较重要,在运行时 limits 比较重要。
而对应实际的业务场景来说,以 java 应用为例,requests 对应的就是JVM虚拟机所需资源的最小值,而 limits 对应的就是 JVM 虚拟机所能够使用的资源最大值。以内存资源为例一般就是指:Xms 和 Xmx,如果 requests 值设置的小于JVM虚拟机 Xms 的值,那么就会导致 Pod 内存溢出,从而导致 Pod 被杀掉,而后重新创建一个Pod。
那么如果 CPU 资源使用超过了 limits,Pod会不会被杀掉呢?答案是不会,但是被限制。如果没有设置 limits ,Pod 可以使用全部空闲的资源。另外如果设置了 limits而没有设置 requests 时,Kubernetes 默认会将 requests 等于 limits。
这里通常还会将 requests 和 limits 描述的资源分为两类:可压缩资源(compressible resources) 和不可压缩资源(incompressible resources)。这里不难看出CPU这类型资源为可压缩资源,而内存这类型资源为不可压缩资源。所以合理设置不可压缩资源的limits值就相当重要了。
3 理解 Kubernetes 中 Pod 的 Qos
当我们理解 requests 和 limits了之后,我们来想一个问题:当某个 Node 上的内存还剩下 90Mi,这个时候就触发了 Kubernetes 的 Eviction,这个时候 kubelet 就会挑选 Pod 进行删除操作,那么这个时候 kubelet 挑选的依据是什么呢?
当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。
Eviction 的默认阈值如下:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%答案就是依据requests和limits值的设置方式来决定,Kubernetes会将Pod划分成3种不同的Qos级别里面去,根据Pod不同的Qos级别来挑选。
- 首当,其冲的就是删除BestEffort级别的Pod,这个级别的Pod完全没有做任何资源限制,即完全没有设置CPU/内存的requests和limits。
- 其次,是Burstable级别的Pod,这个级别的Pod至少设置了1个CPU或者内存的requests,但又不满足最高级别的Qos条件。
- 最后,才是 Guaranteed 级别的Pod,即Pod同时设置了CPU、内存的requests和limits,并且requests值等于limits的值。并且,Kubernetes 会保证只有当 Guaranteed 级别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态(当宿主机的 Eviction 阈值达到后,就会进入该状态)时,Guaranteed 级别的 Pod 才可能被选中进行 Eviction 操作。
可以看下面的表格,以更好的理解:
| CPU requests/limits | 内存 requests/limits | Qos级别 |
|---|---|---|
| 未设置 | 未设置 | BestEffort |
| 未设置 | requests < limits | Burstable |
| 未设置 | requests = limits | Burstable |
| requests < limits | 未设置 | Burstable |
| requests < limits | requests < limits | Burstable |
| requests < limits | requests = limits | Burstable |
| requests = limits | requests = limits | Guaranteed |
4 最佳实践
为 namespace 设置资源配额
- ResourceQuotas 限制主要是指该 namespace 下面的所有 Pod 指定一个 requests和limits的总和要小于设置的 requests 和 limits。
- 该 namespace 下每一个容器必须指定 requests 或 limits,否则将不允许创建。
这样子做的好处就是实现了一条隐含的规则,每个人都要遵守。
设置默认的 requests 和 limits
在生产环境中,很多负载 CPU 和内存的所需的资源基本相同,那么我们可以设置好默认的 requests 和 limits,当用户没有指定 requests 和 limits 值,直接使用默认值。
配置启用CPUSET
我们知道,在使用容器的时候,你可以通过设置 cpuset 把容器绑定到某个 CPU 的核上,而不是像 cpushare 那样共享 CPU 的计算能力。这种情况下,由于操作系统在 CPU 之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升。事实上,cpuset 方式,是生产环境里部署在线应用类型的 Pod 时,非常常用的一种方式。
那么如何启用 cpuset 呢?只需要遵循以下2条规则来设置 requests 和 limits 即可:
- 设置 CPU 的 requests 和 limits 的值相等且为整数值。
- 设置 Pod 的 CPU 和内存的 requests 和 limits 值相等,也就是该 Pod 是一个Guaranteed 级别的 Pod。
高负载Pod requests 和 limits 的设置
而对于负载,流量比较高的 Pod,requests 和 limits 的设置需要根据具体的情况分析,需要分析业务的多个维度。例如
- 该服务的容器是 CPU 密集型,还是吃内存型,亦或者是 IO 密集型。
- 该服务是个单点,还是高可用的。
- 这个服务的上下游都是谁?
- 这个服务的历史监控数据是怎么样的?
说了这么多,貌似还是不知道怎么设置。这就给大家一个“标准答案”:
- 根据历史的 CPU,内存,网络,存储等监控数据,一般 requests 值可以设定为历史数据均值。
- limits 则设置为历史数据均值再增加 30%-50%,当然实际设置还是要根据情况做些微调。
总结
本文主要为大家介绍了 Kubernetes 中 requests 和 limits 两种资源限制类型来对资源进行容器粒度的分配,从而实现 Kubernetes 集群中资源的有效调度和充分利用,还提供了一些我的一些实践。欢迎大家留言交流。
这篇关于Kubernetes中 Requests 和 Limits 的初步理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




