0spark专题
5.4.0Spark和Hive集成(Derby)
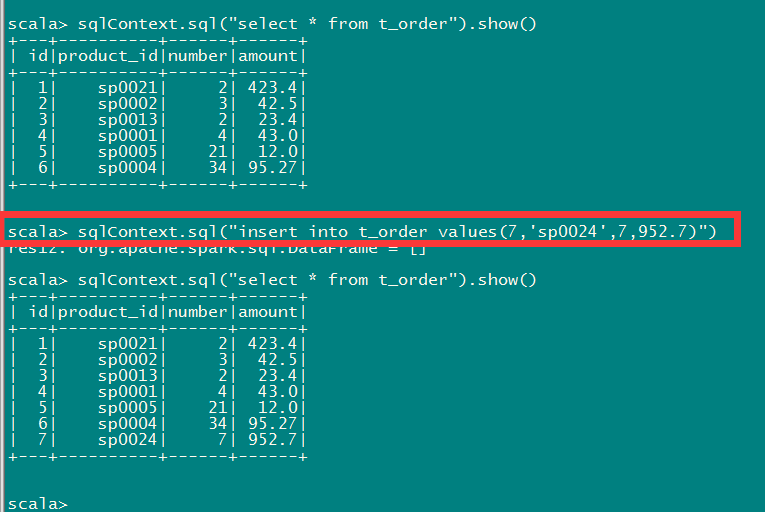
Spark和Hive集成(Derby) 一、 更改Hive安装目录conf下的hive-site.xml文件 <property><name>hive.metastore.uris</name><value>thrift://master:9083</value><description>Thrift URI for theremote metastore. Used by me
5.3.0Spark_SQL入门
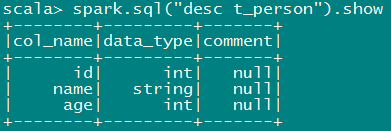
Spark_SQL入门 一、 Spark SQL概述 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。 二、 Spark SQL 作用 Hive是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapRe
5.2.0Spark计算模型RDD
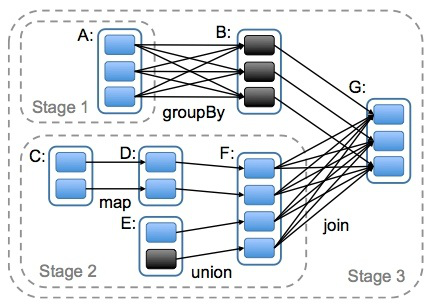
Spark计算模型RDD 一、 RDD概述 1. RDD的定义 RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓