除以专题

高精度加、减、乘、除(高精除以低精)
高精度加法 法1:P1601 A+B Problem(高精) #include <bits/stdc++.h>using namespace std;char s1[510], s2[510];int a[510], b[510], sum[510];int lena, lenb, lens;int main(){cin >> s1 >> s2;lena=strlen(s1);le
PTA L1-037 A除以B
L1-037 A除以B(10分) 真的是简单题哈 —— 给定两个绝对值不超过100的整数A和B,要求你按照“A/B=商”的格式输出结果。 输入格式: 输入在第一行给出两个整数A和B(−100≤A,B≤100),数字间以空格分隔。 输出格式: 在一行中输出结果:如果分母是正数,则输出“A/B=商”;如果分母是负数,则要用括号把分母括起来输出;如果分母为零,则输出的商应为Error。输出的商

numpy除以0时赋值100
在NumPy中,默认情况下,当你尝试除以0时,会引发一个错误,因为数学上除以0是未定义的。但是,如果你想要定义除以0的行为,可以通过自定义数学函数来实现,或者使用条件语句来处理异常情况。 下面是一个例子,展示了如何在NumPy数组中处理除以0的情况,使得结果为100: # 定义一个处理除以0的函数def safe_divide(x, y):with np.errstate(divide

transfomer中attention为什么要除以根号d_k
简介 得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下: A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=Softmax(dk
为什么self-attention要除以一个根号dk
简单说法是为了让方差到1,推公式也好推。但是没几个人说为什么方差要到1. 如果不除以根号dk,显然QK有可能很大,这就让softmax更有能力得到接近one-hot的结果。这本应是好的,但是从实践来看,我们并不要求一定要输出one-hot,这有点over-fitting的感觉了。差不多就行。 还有更重要的理由。softmax求导是 a − a 2 a-a^2 a−a2, a a a是softmax

PAT B1017 -- A除以B
牛客网PAT乙级第七题,A除以B,题目描述大致如下: 计算A/B,输入A,B,以空格分隔,A是不超过1000位的正整数,B是1位正整数,输出余数Q和商R,空格分离,使得A=B*Q+R成立。 题目要求的输入输出如下: 代码如下: #include <iostream>#include <string>using namespace std;int main(){string

用python分析处理药店销售数据:得到以下三个指标:月消费次数,即总消费次数除以月份数,往往是销售部门重要的指标值之一。月均消费金额,总的消费金额除以月份数,主要作为部门收益的一个指标。(3
项目背景与目标 零售药店行业现状分析 药品零售作为一个传统行业,正受到新零售方式崛起、医改不断深化、行业监管逐步提升等挑战,零售药店位居医药产业链下游,是医药零售的重要终端。在中国,药店是指面向消费者销售医药产品和各类健康产品的零售门店,近年来也发展出网上药店这类线上终端。而中国药店渠道仅占药品总销售约2成,如将我国药品销售分为医院、药店和基层医疗机构三大终端,药品在药店渠道销售占比约为22
高精度之高精度除法(高精除以高精)
好像NOIP并不会用到,但是作为强迫症的我还是坚持学了。高精度除以高精度我所知道的有两个思路: 手动模拟法 还是手动模拟除法过程,但是注意在截取了被除数的正确片段之后应该试商,即枚举k从1到9看当k等于多少才合适,但是如果每次循环都试一边的话时间复杂度必定会很高,优化的方法就是在开始时就把k乘以除数的值记录下来,程序执行时只要二分比较确定K值就行了。 但是这种方法实现起来太过麻烦,比较大小时
高精度之高精度除法(高精除以低精)
一.整除版高精度除法: 思路,手动模拟除法过程,包括余数用X记录,每次读到新位计算出被除数,然后计算。 //高精度除法 整除版 #include<iostream>#include<cstdio>#include<cstdlib>#include<algorithm>#include<functional>#include<vector>#include<iterator>us

1017 A除以B (20 分) ( JAVA )
1017 A除以B (20 分) 本题要求计算 A/B,其中 A 是不超过 1000 位的正整数,B 是 1 位正整数。你需要输出商数 Q 和余数 R,使得 A=B×Q+R 成立。 输入格式: 输入在一行中依次给出 A 和 B,中间以 1 空格分隔。 输出格式: 在一行中依次输出 Q 和 R,中间以 1 空格分隔。 输入样例: 123456789050987654321 7 输出

self-attention为什么要除以根号d_k
一、因为softmax的输入很大时,其梯度会变的很小,趋近于0; 二、除以根号Dk的目的就是使得,QK/Dk满足方差稳定到1,使得softmax的梯度不至于太小 参考: transformer中的attention为什么scaled? - 知乎 注意力机制在softmax时除以一个根号d的作用_samuelzhoudev的博客-CSDN博客 self-attention为什么要
PTA1017 A除以B
题目: 本题要求计算 A/B,其中 A 是不超过 1000 位的正整数,B 是 1 位正整数。你需要输出商数 Q 和余数 R,使得 A=B×Q+R 成立。 输入格式: 输入在一行中依次给出 A 和 B,中间以 1 空格分隔。 输出格式: 在一行中依次输出 Q 和 R,中间以 1 空格分隔。 输入样例: 123456789050987654321 7 输出样例: 17636684

fn除以10007的余数
#include<stdio.h>int main(){int n,f1=1,f2=1,f3=2,s=0;scanf("%d",&n);if(n>=1&&n<=1000000)for(s=3;s<=n;s++){f3=(f1+f2)%10007;f1=f2;f2=f3;}printf("%d",f3);}
L1-037 A除以B(Java)
真的是简单题哈 —— 给定两个绝对值不超过100的整数A和B,要求你按照“A/B=商”的格式输出结果。 输入格式: 输入在第一行给出两个整数A和B(−100≤A,B≤100),数字间以空格分隔。 输出格式: 在一行中输出结果:如果分母是正数,则输出“A/B=商”;如果分母是负数,则要用括号把分母括起来输出;如果分母为零,则输出的商应为Error。输出的商应保留小数点后2位。 输入样例1:
PTA团体程序设计天梯赛-练习集L1-037 A除以B
L1-037 A除以B 题目要求 真的是简单题哈 —— 给定两个绝对值不超过100的整数A和B,要求你按照“A/B=商”的格式输出结果。 输入格式: 输入在第一行给出两个整数A和B(−100≤A,B≤100),数字间以空格分隔。 输出格式: 在一行中输出结果:如果分母是正数,则输出“A/B=商”;如果分母是负数,则要用括号把分母括起来输出;如果分母为零,则输出的商应为Error。输出的商应保留
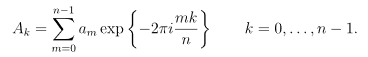
FFT之频率与幅值为何要除以(N/2)
FFT之后获得的是啥? FFT之后得到的一系列复数,是波形对应频率下的幅度特征,注意这个是幅度特征(特征值)不是幅值。 进行FFT变换,获取频率: FFT傅里叶变换并没对频率进行任何计算,频率只与采样率和进行傅里叶变换的点数相关,注意这里是进行傅里叶变换的点数而不一定是信号的长度。 FFT变换完: 第一个数是0Hz频率,0Hz就是没有波动,没有波动有个专业一点的说法,叫直流分量。 第二
Python案例89:加密数字,输入四位数字,每位数字都加上5,除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换
加密数字,list的处理方法 题目代码和结果分析 题目 题目:某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。 原题参考如下网站 https://www.runoob.com/python/python-exercise-example89.htm
SQL解决除以零错误的两种方法
在实际项目中,我们可能会遇到求百分比,比值等带除法的sql语句。这时,我们也许会遇到分母为零的情况。 下面给出解决的2种方法: 1. 用NULLIF函数。 首先说一下NULLIF函数的语法: NULLIF(expr1,expr2) 意思是说:如果expr1<>expr2的话,则传回expr1;如果expr1=expr2的话,则返回NULL。 2.用case when语句。
32位除以10,打印10进制字符串代码
根据这段代码调试而来: MOV BX,11H ;BX为除数 MOV DX,5678H ;DX存高位 MOV AX,1234H ;AX存低位 MOV DI,AX ;先保存好低位 ;先计算高位,所得商AX即为最后商的高位

java除以0的异常_打破你的认知,java,除以0一定会崩溃吗?
System.out.println("1/0=" + 1/0); 大叔的灵魂拷问: 上面的代码会崩溃吗?假如不会,会输出什么呢? 上面的代码会崩溃吗?假如不会,会输出什么呢? 上面的代码会崩溃吗?假如不会,会输出什么呢? 运行直接崩溃。 ## 代码2 我们再来看一行代码: System.out.println("1.0/0=" + 1.0/0); 大叔的灵魂拷问: 会崩溃吗?假如不会,会输出
基础算法:大数除以除以13
基础算法:大数除以一个数 信息学奥赛:1175:除以13 时间限制: 1000 ms 内存限制: 65536 KB 【题目描述】 输入一个大于0的大整数N,长度不超过100位,要求输出其除以13得到的商和余数。 【输入】 一个大于0的大整数,长度不超过100位。 【输出】 两行,分别为整数除法得到的商和余数。 【输入样例】 2132104848488485 【输出样例】 164008065

冠达管理:市盈率除以市净率是什么意思?
市盈率(Price-to-Earnings Ratio,简称P/E)和市净率(Price-to-Book Ratio,简称P/B)是股票商场中常用的两个评价目标。市盈率衡量的是一家公司的市值与其盈余才能的联系,而市净率则是衡量其市值与净资产的联系。在剖析一家公司的估值和投资决策时,许多投资者会将两者进行归纳考虑,即将P/E除以P/B,这便是市盈率除以市净率的意思。 从盈余才能的视点来看,市

我校进行讲演比赛共有10名评委php,c语言答案。有支队伍参加比赛,评分规则是从10名评委中去掉最高分和最低分,计算总分,并除以8是没队得分....
c语言答案。有支队伍参加比赛,评分规则是从10名评委中去掉最高分和最低分,计算总分,并除以8是没队得分. 关注:206 答案:3 mip版 解决时间 2021-01-31 12:07 提问者等妳¬硪唯一鍀执念 2021-01-31 01:21 c语言答案。有支队伍参加比赛,评分规则是从10名评委中去掉最高分和最低分,计算总分,并除以8是没队得分. 最佳答案 二级知识专家寄出个心动 202
1017.A除以B(大整数运算)
本题要求计算A/B,其中A是不超过1000位的正整数,B是1位正整数。你需要输出商数Q和余数R,使得A = B * Q + R成立。 输入格式: 输入在1行中依次给出A和B,中间以1空格分隔。 输出格式: 在1行中依次输出Q和R,中间以1空格分隔。 输入样例: 123456789050987654321 7 输出样例: 17636684150141093474 3