重点难点专题

Flink重点难点:维表关联理论和Join实战
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》《Flink重点难点:网络流控和反压》 Flink官方文档中公开的信息 1 Join 的概念 在阅读之前请一定要先了解: 数据流操作的另一个常见需求是对两条数据流中的事件进行联结(connect)或Join。Flink DataStream API中

Flink重点难点:Flink任务综合调优(Checkpoint/反压/内存)
在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》 《Flink重点难点:网络流控和反压》 《Flink重点难点:维表关联理论和Join实战》 《Flink重点难点:内存模型与内存结构》 《Flink重点难点:Flink Table&SQL必知必会(一)》 Flink重点难点:Flink Table&SQL必知必会(二) CheckPoint调优

Flink重点难点:状态(Checkpoint和Savepoint)容错与两阶段提交
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》《Flink重点难点:网络流控和反压》《Flink重点难点:维表关联理论和Join实战》《Flink重点难点:内存模型与内存结构》《Flink重点难点:Flink Table&SQL必知必会(一)》Flink重点难点:Flink Table&SQL必
针对Android开发中Java语言的重点难点分享
很多的做过,或者正在做Android开发的朋友们都知道,Java语言在开发中所占的比例是非常大的。但是往往越是重要的东西,就越很少有人弄清楚它的原理。今天在这儿就为大家带来一个免费课程的分享: http://www.microoh.com/04/01/2/2/ 主要是讲解Java语言在Android开发中的一些重点和难点。 市面上各类Java语言课程充斥,因此这套课程不是从零开始

Python编程:从入门到实践 —学习笔记1(重点难点归纳)(第一章到第五章)
学习记录:2018.11.06开始学习Python语言,网上看了一些博客和豆瓣书评,推荐基础较薄弱的同学,从《Python编程:从入门到实践》这本书开始学习效果较好。 学习期间,将文中的重点,难点,易忘点做了电子笔记,发现很多知识点时间久了容易忘记,因此,整理归纳后发到博客,便于以后查询学习。 目录: 1.变量 2. 合并拼接,空白 3. 列表 4. 操作列表 5. If语句 **
二.java基础-java重点难点整理学习这一篇就够了(详细)
目录 一、java入门到精通学习笔记二、java基础重点难点整理 一、java入门到精通学习笔记 超链接:java入门到精通学习笔记 二、java基础重点难点整理 1.String类详解 String类详解1 String类详解2 String类解析 2.正则表达式 正则表达式 3.类内容初始化顺序 类初始化顺序 4.引用传递与值传递 java值传递与引用传递 注:S
2324. 生活的艰辛(网络流,最小割,最大密度子图)#困难,重点难点
活动 - AcWing 约翰是一家公司的 CEO。 公司的股东决定让他的儿子斯科特成为公司的经理。 约翰十分担心,儿子会因为在经理岗位上表现优异而威胁到他 CEO 的位置。 因此,他决定精心挑选儿子要管理的团队人员,让儿子知道社会的险恶。 已知公司中一共有 n 名员工,员工之间共有 m 对两两矛盾关系。 如果将一对有矛盾的员工安排在同一个团队,那么团队的管理难度就会增大。 一个团队的
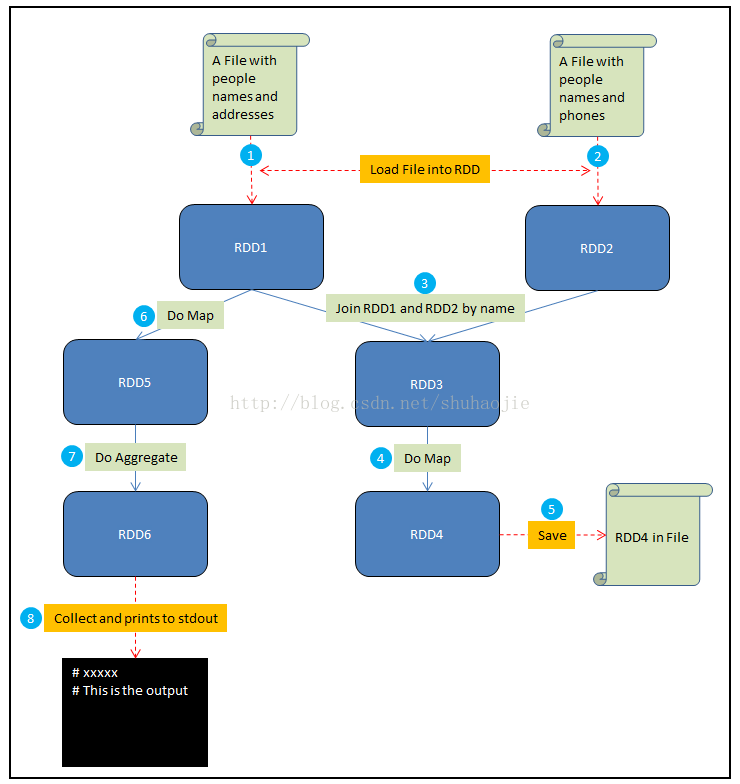
Spark重点难点知识总结(一)
本博客是个人在学习Spark过程中的一些总结,方便个人日后查阅,同时里面出现的一些关键字也可以作为后来一些读者学习的材料。若有问题,欢迎评论,一定知无不言。 1.Tuple:Tuple就是用来把几个数据放在一起的比较方便的方式,注意是“几个数据”,因此没有Tuple1这一说。 val scores=Array(Tuple2(1,100),Tuple2(2,90),Tuple2(3,100),

Spark重点难点知识总结(二)
1.join:join函数主要用来拼接字符串,将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串。 var rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)var rdd2 = sc.makeRDD(Array(("A","a"),("C","c"),("D","d")),2)scala> rdd1.jo
Hadoop重点难点:Hadoop IO/压缩/序列化
Hadoop – IO 输入文件从HDFS进行读取.输出文件会存入本地磁盘.Reducer和Mapper间的网络I/O,从Mapper节点得到Reducer的检索文件.使用Reducer实例从本地磁盘回读数据.Reducer输出- 回传到HDFS. 序列化 序列化是指将结构化对象转化为字节流以便在网络上传输或写到磁盘进行永久存储的过程。反序列化是指将字节流转回结构化对象的逆过程。 序列化用于分布