酱浦菌专题
【酱浦菌-爬虫项目】python爬取彼岸桌面壁纸
首先,代码导入了两个库:requests和parsel。这些库用于处理HTTP请求和解析HTML内容。 然后,它定义了一个变量url,指向网站’樱花2024年4月日历风景桌面壁纸_高清2024年4月日历壁纸_彼岸桌面’。 接下来,设置了一个HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。 通过requests.get()方法,发送一个GET请求到指定的URL,并将响应内容保存在

【酱浦菌-爬虫项目】四种方法爬取百度首页信息
项目原理: 首先,定义了四个函数,每个函数都有不同的功能: func1():发送一个GET请求到百度网站,并获取响应内容,演示如何使用`requests`库来获取网页内容。 func2():发送一个GET请求到百度网站,并获取响应内容。然后将响应内容保存为名为“baidu.png”的图片文件。 func3():使用Splash执行Lua脚本,加载百度网站并等待2秒,然后返回HTML内容。
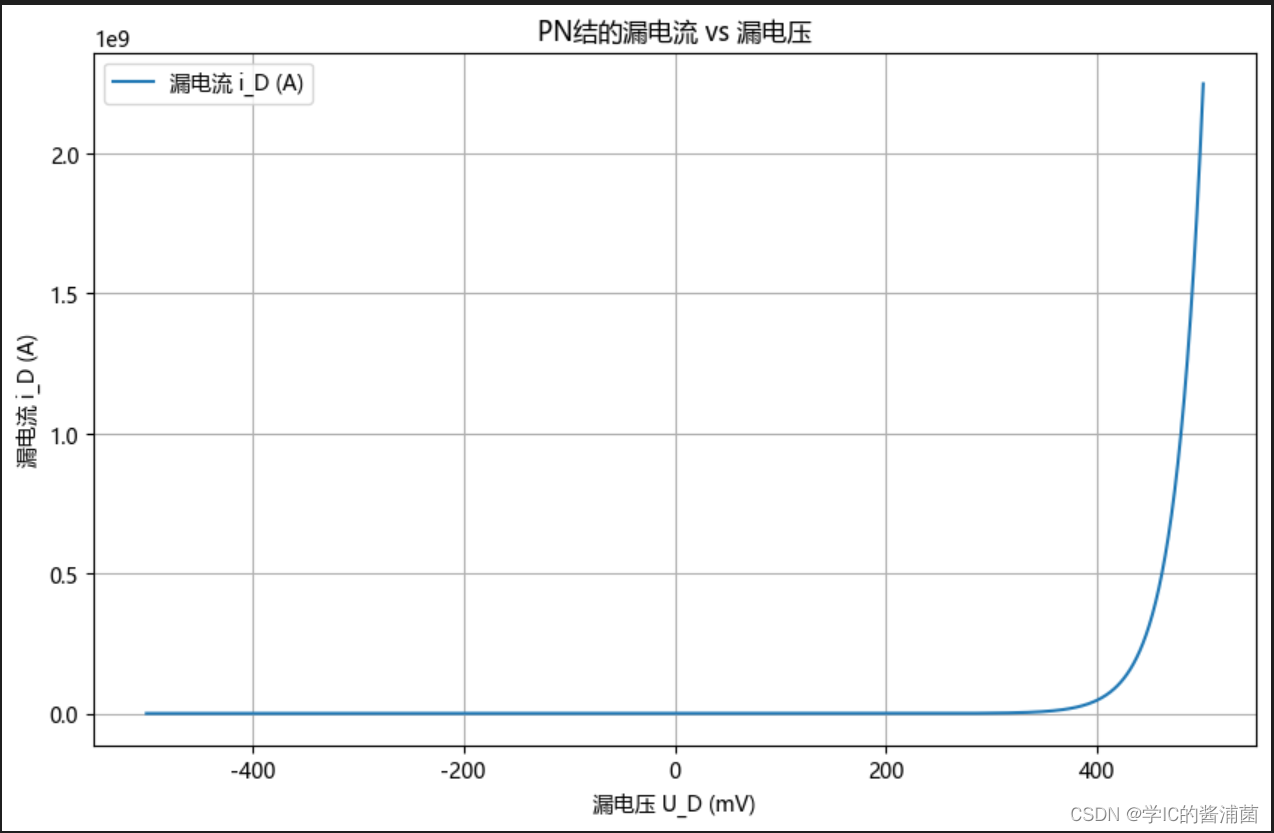
【酱浦菌-模拟仿真】python模拟仿真PN结伏安特性
PN结的伏安特性 PN结的伏安特性描述了PN结在外部电压作用下的电流-电压行为。这种特性通常包括正向偏置和反向偏置两种情况。 正向偏置 当外部电压的正极接到PN结的P型材料,负极接到N型材料时,称为正向偏置。在这种情况下,外加的正向电压会削弱PN结的内建电场,使得耗尽区内的正负离子数量减少,内建电场和势垒电压降低,从而允许电流通过PN结。随着正向电压的增加,耗尽区进一步缩小,内建电场进一步削
【酱浦菌-爬虫项目】爬取百度文库文档
1. 首先,定义了一个变量`url`,指向百度文库的搜索接口 ‘https://wenku.baidu.com/gsearch/rec/pcviewdocrec’。 2. 然后,设置了请求参数`data`,包括文档ID(`docId`)和查询关键词(`query`)。 3. 定义了HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。 4. 使用`requests.get()`方法,发送一个
【酱浦菌-爬虫项目】爬取学术堂论文信息
1. 首先,代码定义了一个名为 ``` url ``` 的变量,它是一个包含三个网址的集合(或者说是一个集合的字典)。这些网址分别是: - ‘http://www.xueshut.com/lwtimu/127966.html’ - ‘http://www.xueshut.com/lwtimu/127966_2.html’ - ‘http://www.