近端专题

近端安全互联样例使用指导
样例介绍 本样例基于rk3568开发板,通过封装openharmony安全子系统deviceauth组件提供的能力,实现了一组可用于设备间快速建立可信认证和连接的接口,通过预先定义关系网,在设备初始化阶段完成端端设备间的认证,构建安全的数据传输通道。 场景介绍 本样例可以作为一个SDK集成到设备版本中,供上层业务APP或IOT SDK使用,具体应用场景可参考下图: 场景1:在城市鸿蒙的
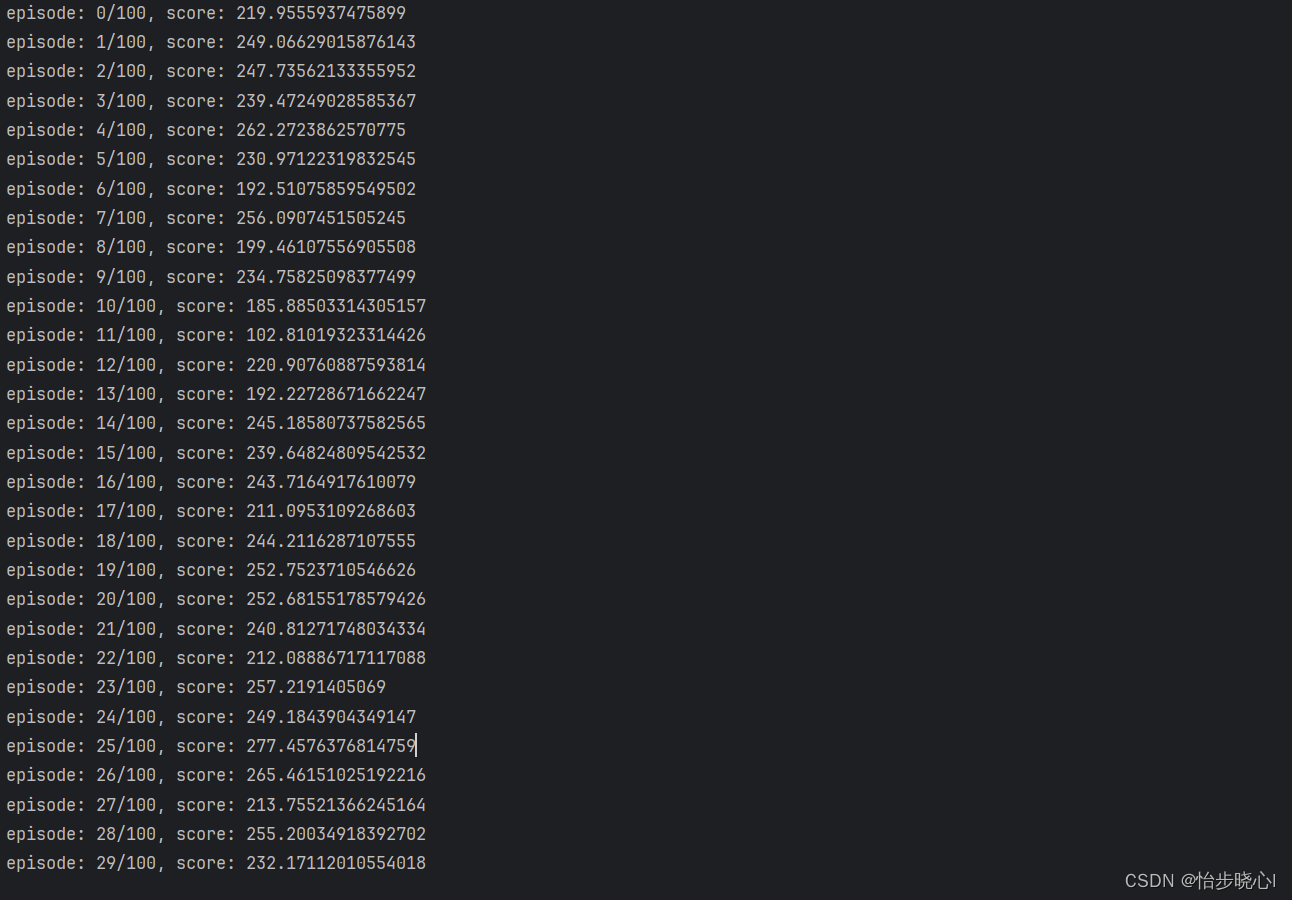
13、近端策略优化Proximal Policy Optimization (PPO) 算法:从原理到实践
基于LunarLander登陆器的PPO强化学习(含PYTHON工程) PPO对标的是TRPO算法,改进了其性能。也有学者认为其理论性不强,但实践效果往往不错。 TRPO的缺点: 无法处理大参数矩阵:尽管使用了共轭梯度法,TRPO仍然难以处理大的 Fisher矩阵,即使它们不需要求逆近似值可能会违反KL约束,从而导致分析得出的步长过大,超出限制要求我们不能利用一阶随机梯度优化器,例如ADAM

【论文阅读】强化学习—近端策略优化算法(Proximal Policy Optimization Algorithms, PPO)
(一)Title 写在前面: 本文介绍PPO优化方法及其一些公式的推导。原文中作者给出了三种优化方法,其中第三种是第一种的拓展,这两种使用广泛,且效果好,第二种方法在实验中验证效果不好,但也算一个trick,作者也在文中进行了分析。 (二)Abstract 深度强化学习在训练过程中难以避免效果容易发生退化并且很难恢复这类问题,导致训练不稳定。自然策略梯度[1](NPG,Natural