读点专题

【读点论文】Scene Text Detection and Recognition: The Deep Learning Era
Scene Text Detection and Recognition: The Deep Learning Era Abstract 随着深度学习的兴起和发展,计算机视觉发生了巨大的变革和重塑。场景文本检测与识别作为计算机视觉领域的一个重要研究领域,不可避免地受到了这波革命的影响,从而进入了深度学习时代。近年来,该社区在思维方式、方法论和性能方面取得了长足的进步。本综述旨在总结和分析深度学

【读点论文】YOLOX: Exceeding YOLO Series in 2021,无锚框单阶段目标检测方案,解耦检测头的分类和回归分支,优化标签分配策略
YOLOX: Exceeding YOLO Series in 2021 Abstract 在本报告中,我们介绍了YOLO系列的一些经验改进,形成了一种新的高性能探测器—YOLOX。我们将YOLO检测器切换到无锚方式,并进行其他先进的检测技术,即去耦头和领先的标签分配策略SimOTA,以在大规模的模型范围内实现最先进的结果:对于只有0.91M参数和1.08G FLOP的YOLONano,我们在

python 读点画图
#!/usr/bin/python# -*- coding: UTF-8 -*-import pylab as plimport osimport numpy as npmark = ['or','vb','>g','<c','sm','py','hk','+w','*']x = []y = []z = []#root = 'result/all/'root = 'result

202435读书笔记|《半小时漫画中国史》——读点经济学与历史,生活更美好,趣味烧脑土地制度、商鞅变法、华丽丽的丝绸之路这里都有
202435读书笔记|《半小时漫画中国史》——读点经济学与历史,生活更美好,趣味烧脑土地制度、商鞅变法、华丽丽的丝绸之路这里都有 1. 土地政策、度量衡及税收2. 商鞅变法3. 西汉经济4. 西汉盐铁大辩论5. 西汉丝绸之路 《半小时漫画中国史:经济篇》陈磊·半小时漫画团队著。混子哥出品,必属精品,简直不要太有意思的一本书,有趣好玩,看的很快乐的一本书。 中间夹杂了一些经济学里

【读点论文】MobileDets: Searching for Object Detection Architectures for Mobile Accelerators,适配不同硬件平台的搜索方案
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators Abstract 建立在深度方向卷积上的反向瓶颈层已经成为移动设备上的最新对象检测模型中的主要构件。在这项工作中,本文通过重新考察常规卷积的有效性,研究了这种设计模式在各种移动加速器上的最优性。本文发现,常规卷积是一个有效的组件,可以

【读点论文】A Survey of Quantization Methods for Efficient Neural Network Inference
A Survey of Quantization Methods for Efficient Neural Network Inference Abstract 一旦抽象的数学计算适应了数字计算机的计算,在这些计算中如何有效地表示、处理和传递数值的问题就出现了。与数字表示问题密切相关的是量化问题:一组连续的实值数应该以何种方式分布在一组固定的离散数字上,以最小化所需的位数,并最大化随之而来的计

【读点论文】Searching for MobileNetV3 集合了多项热门技术通道注意力,神经网络搜索,V1,V2。建议深度学习MnasNet和NetAdapt两篇论文
Searching for MobileNetV3 MobileNet v3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。 Abstract 本文提出了基于互补搜索技术的组合以及新颖的架构设计的下一代移动互联网。MobileNetV3通过硬件网
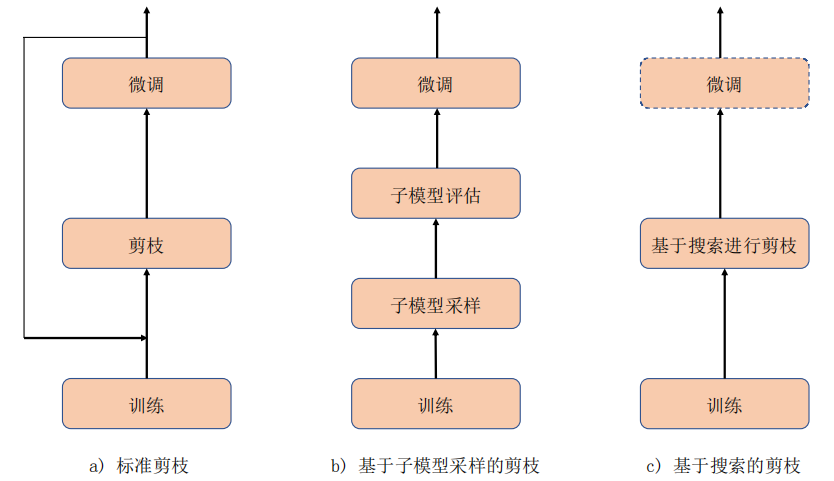
【读点论文】结构化剪枝
结构化剪枝 在一个神经网络模型中,通常包含卷积层、汇合层、全连接层、非线形层等基本结构,通过这些基本结构的堆叠,最终形成我们所常用的深度神经网络。 早在 1998 年,LeCun 等人使用少数几个基本结构组成 5 层的 LeNet-5 网络,并在 MNIST 数据集上得到了 98.9%的分类精度,但此时的深度神经网络还相对简单,并且只能用于简单的任务上;在 2012 年的 ImageNet

【读点论文】VanillaNet: the Power of Minimalism in Deep Learning,在浅层网络中加入更丰富的非线性元素加上提出的网络训练技巧得到了一些惊讶的效果
VanillaNet: the Power of Minimalism in Deep Learning Abstract 基础模型的核心理念是“多而不同”,计算机视觉和自然语言处理领域的惊人成功就是例证。然而,优化的挑战和transformer模型固有的复杂性要求范式向简单性转变。在这项研究中,我们介绍了VanillaNet,一个包含优雅设计的神经网络架构。通过避免高深度、残差方式和复杂的

【读点论文】ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,规则分组,有序混洗
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices Abstract 本文介绍了一种称为ShuffleNet的计算效率极高的CNN架构,它是专门为计算能力非常有限(例如10-150 MFLOPs)的移动设备设计的。新架构利用两种新操作,逐点组卷积和信道混洗,在保持精度的同时大大降低

【读点论文】Learned Queries for Efficient Local Attention(QnA)Transformer新理解,学习好Query,更好的结合局部理解,提升语义理解的效率
Learned Queries for Efficient Local Attention Abstract (Vision transformer, ViT)是一种强大的视觉模型。与前几年主导视觉研究的卷积神经网络不同,ViT具有捕获数据中的长期依赖关系的能力。尽管如此,任何transformer体系结构的一个组成部分,即自注意力机制,都存在高延迟和低效的内存利用问题,这使得它不太适合高分

【读点论文】Separable Self-attention for Mobile Vision Transformers,通过引入隐变量将Q矩阵和K矩阵的算数复杂度降低成线性复杂度,分步计算注意力。
Separable Self-attention for Mobile Vision Transformers Abstract 移动视觉transformer(MobileViT)可以在多个移动视觉任务中实现最先进的性能,包括分类和检测。虽然这些模型的参数较少,但与基于卷积神经网络的模型相比,它们具有较高的延迟。MobileViT的主要效率瓶颈是transformer中的多头自我注意(MH

【读点论文】DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution Abstract 许多现代的物体探测器都是通过观察和思考两遍的机制表现出出色的性能。在本文中,本文在目标检测的主干设计中探讨了这种机制。在宏观层面,本文提出了递归特征金字塔,它将特征金字塔网络的额外反馈连接