计算能力专题

GPU显卡计算能力怎么算?
GPU的算力指的是什么? GPU的计算能力可以使用FLOPS表示,FLOPS是floating-point operations per second的缩写,表示“每秒所执行的浮点运算次数”。是被用来估算处理的计算能力 1 MFLOPS = 每秒可以执行一百万(10^6)次浮点运算 1 GFLOPS = 每秒可以执行十亿(10^9)次浮点运算 1 TFLOPS = 每秒可以执行一万亿(10
显卡计算能力profile文件修改
CUDA深度学习显卡算力文件修改 参考:aiuai 目的:在使用Pytorch进行深度学习训练的时候,在setup时需要对算力进行设置,根据机器使用的不同的GPU型号,需要改写nvcc编译使用的参数。 例如: #!/usr/bin/env python3import osimport torchfrom setuptools import setup, find_pack

CUDA 12.4文档3 内存层次异构变成计算能力
5.3 内存层次 Memory Hierarchy CUDA线程在执行过程中可能会访问多个内存空间的数据,如图6所示。每个线程都有自己的私有本地内存。 每个线程块都有一个对块内所有线程可见的共享内存,并且其生命周期与块相同。线程块集群中的线程块可以对彼此的共享内存执行读、写和原子操作。所有线程都可以访问同一块全局内存。 此外,还有两个只读内存空间可以被所有线程访问:常量内存空间和纹理内存空间

NVIDA CUDA显卡计算能力 GeForce RTX 2060 compute_capability
2060的计算能力:compute_capability = 750,GPU: GeForce RTX 2060 下图为在测试训练数据时 打印的日志

Angel 3.2.0新版本出炉!图计算能力再次加强
Angel项目的3.2.0版本发布啦! Angel是腾讯首个AI开源项目,经过多个版本迭代,于2019年在Linux基金会顺利毕业。作为面向机器学习的第三代高性能计算平台,Angel提供了全栈的机器学习能力,并致力于解决高维稀疏大模型训练以及大规模分布式图计算的问题。 在3.1.0的版本中,Angel首次引入了图计算能力,提供了大量开箱即用的图算法,得到了业界广泛的关注和使用。
机器学习 | 深入探索Numpy的高性能计算能力
目录 初识numpy numpy基本操作 数组的基本操作 ndarray运算 数组间运算 矩阵 初识numpy Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。 Numpy使用ndarray对象来处理多维数组

Google 的计算能力仍是独步武林
从 Greg Linden 的文章看到的数据:Google 的 MapReduce 平均每天处理 20 Petabytes 的数据。每天能跑完 10 万个工作任务。光是 07 年 9 月,就用掉了 11081 个"机器年" ,跑了 220 万个 Mapreduce 任务。这个计算能力是惊人的。 Yahoo! 也用 Hadoop 实现了 Mapreduce , 我个人感觉和 Google 可能还有
树莓派以及一些常见的硬件设备的浮点计算能力
http://web.eece.maine.edu/~vweaver/group/green_machines.html https://github.com/deater/performance_results
人工神经网络太简陋了,《Science》揭露,神经元树突也隐含计算能力
本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在学习摘录和笔记专栏: 学习摘录和笔记(13)---《人工神经网络太简陋了,《Science》揭露,神经元树突也隐含计算能力》 人工神经网络太简陋了,《Science》揭露
人工神经网络太简陋了,《Science》新作揭露,神经元树突也隐含计算能力
2020-01-19 16:10 导语:树突也能执行XOR计算 雷锋网(公众号:雷锋网)AI科技评论按:人类某些神经元的树突,可以执行之前认为需要整个神经网络才能完成的逻辑运算。 目前对于计算机科学家来讲,人工神经网络构建,往往基于这样一个概念:神经元是一个简单的、非智能的开关,神经网络的信息处理来源于数万(数万亿)个神经元之间的连接。 然后神经科学家对于人脑的研究发现却并不是如此。在

mx250 计算能力_为mx250游戏测评啥mx250被称为笔记本上的智商检测卡?
帧数在左上角,所有测试游戏默认中等特效。 可以看出,第一场比赛的实时帧数在38帧左右,与市场默认的60帧流畅度标准相差甚远。玩游戏的时候波动很大。有些人多的场景会出现严重的掉帧,甚至只有十几帧。玩游戏基本不可能顺利。 看第二场《GTA5》 和第一次性能差不多,实时帧数还是只有31帧左右,离60帧的标准还很远。需要注意的是,玩游戏时帧数已经降到了个位数。我想知道我的笔记本是不是不能用了。位数都
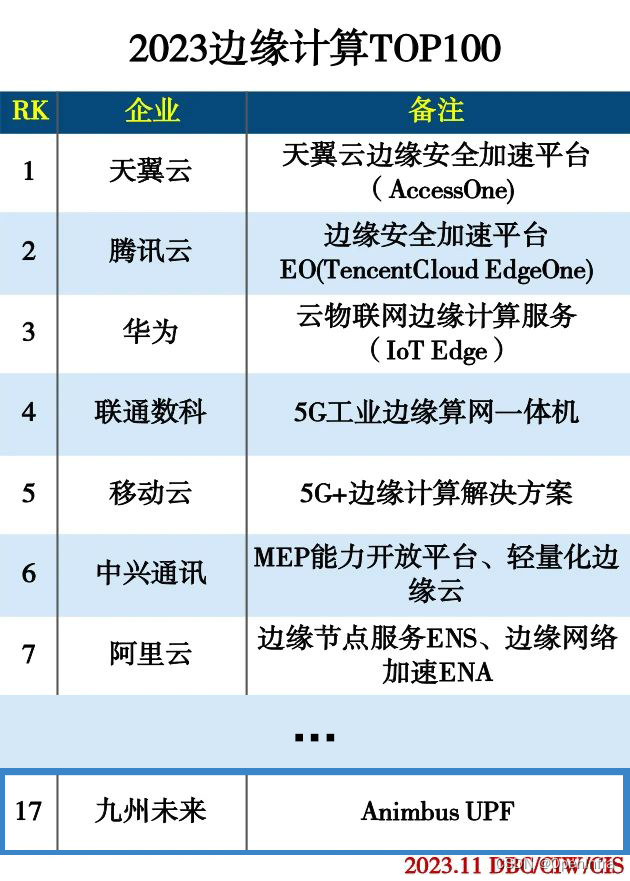
九州未来入选2023边缘计算TOP100,边缘计算能力再获认可
近日,德本咨询、互联网周刊、中国社会科学院信息化研究中心联合发布 “2023边缘计算TOP100”榜单,九州未来凭借领先的技术优势、产品服务能力、落地实践经验等综合实力入选。 数字时代,算力成为第一生产力。边缘计算凭借其低时延、节省带宽、本地计算、安全性高的特性,弥补了传统云计算中心的不足。“十四五”规划中明确提出要“协同发展云服务与边缘计算服务”,国务院《“十四五”数字经济发展规划》同时指

总计算能力 TPP (Total Processing Performance) 是个什么概念?
TPP = 2 * MacTOPS * bit length of the operation 所谓的MacTOPS,是指最大的相乘累加操作的能力,也就是D=A*B+C,算作一次操作。前面要乘一次2,是因为乘和加,一次操作实际上是两次运算。该操作的比特长度,我看有很多媒体误解为什么显存位宽了,这是错误的。这意思是说,比如FP32就要乘上32,FP16就乘以16,INT 8就乘以8。 PD=

阅面科技发布堪比服务器的终端视觉模块,将云端计算能力搬至终端
撰文 | 王艺、藤子 11 月 1 日,阅面科技在深圳举办了创立两年来的首次新品发布会,共发布了三款产品:跨模态人脸识别引擎 UniFace、基于 Uniface 的「繁星」AI 芯片视觉模块、以及基于「繁星」的智能客群分析摄像机——「阅客」。 在发布会后,阅面科技 CEO 赵京雷对机器之能透露道,发布会后两天时间内,他们就收获了一百余份订单,此时的赵京雷内心难掩兴奋之情。

Jetson TX2的计算能力
TX2的GPU算力 GPU的浮点计算理论峰值能力公式如下: 理 论 峰 值 = G P U 芯 片 数 量 * G P U B o o s t 主 频 * 核 心 数 量 * 单 个 时 钟 周 期 内 能 处 理 的 浮 点 计 算 次 数 理论峰值 = GPU芯片数量*GPU Boost主频*核心数量*单个时钟周期内能处理的浮点计算次数 理论峰值=GPU芯片数量*GPUBoost主频*核