网页内容专题

Python结合requests和Cheerio处理网页内容的操作步骤
《Python结合requests和Cheerio处理网页内容的操作步骤》Python因其简洁明了的语法和强大的库支持,成为了编写爬虫程序的首选语言之一,requests库是Python中用于发送HT... 目录一、前言二、环境搭建三、requests库的基本使用四、Cheerio库的基本使用五、结合req

0基础学习爬虫系列:网页内容爬取
1.背景 今天我们来实现,监控网站最新数据爬虫。 在信息爆炸的年代,能够有一个爬虫帮你,将你感兴趣的最新消息推送给你,能够帮你节约非常多时间,同时确保不会miss重要信息。 爬虫应用场景: 应用场景主要功能数据来源示例使用目的搜索引擎优化 (SEO)分析关键词密度、外部链接质量等网站元数据、链接提升网站在搜索引擎中的排名市场研究收集竞品信息、价格比较电商网站、行业报告制定更有效的市场策略舆情

vue项目通过puppeteer做SEO,可以使用Puppeteer在Vue项目中进行SEO,通过服务端渲染获取渲染后的HTML内容,以便搜索引擎爬虫能够正确地索引您的网页内容。
正在使用的项目 https://manefuwu.com/ 下载vue-seo-puppeteer项目:https://github.com/lovelin0523/vue-seo-puppeteer npm install 查看puppeteer缺失的库 ldd node_modules/puppeteer/.local-chromium/linux-756035/chrome-lin
html乱码原因与网页乱码解决方法,浏览器浏览网页内容出现乱码符合解决篇
html乱码原因与网页乱码解决方法,浏览器浏览网页内容出现乱码符合解决篇 造成html网页乱码原因主要是html源代码内中文字内容与html编码不同造成。但无论是哪种情况造成乱码在网页开始时候都需要设置网页编码。 charset编码设置 html网页乱码效果截图 一、乱码造成原因 - TOP 1、比如网页源代码是gbk的编码,而内容中的中文字是utf-8编码

C#实现网页内容正文抓取
思路: 1、抓取远程网页源码,这里要实现自动判断网页编码,否则有可能抓到乱码。我是先看应答的 http头的chareset,一般这个很准,但像csdn的新闻比较变态http应答的头里的chareset和网页的meta里声明的 chareset不一致,所以我手工加了一下判断,如果不一致再在内存流里用网页声明的编码读取一遍源码 2、把网页分割成几大块。试用了一下tidy的.net包装及HtmlPars
C# .net 如何抓取网页内容
ASP.NET 中抓取网页内容是非常方便的,而其中更是解决了 ASP 中困扰我们的编码问题。 1、抓取一般内容 需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码: WebRequest 类的 Create 为静态方法,参数为要抓取的网页的网址; Encoding
利用javascript打印html网页内容中的指定内容
之前帮老师做一个小模块,需要有一个是打印功能,我就在网上找了很多材料,其中一个方法是通过javascript打印网页中的指定内容,这个方法相对来说比较简单,但是,只要能够完成需求,它就是一个好方法。 具体的代码如下,我是写在jsp页面中的,当然,也可以应用在其他例如html或者asp等。 <head><script language="JavaScript"><!--function
js网页内容抓取分析
jsoup网页内容抓取分析(2) 博客分类: java爬虫搜索 jsoup java搜索爬虫 java数据抓取 针对上一篇写的内容很简单,只是给大家抛出了有一个工具可以用来分析网页的内容,做java搜索爬虫使用,实际的使用并没有怎么介绍,现在这篇文章就来介绍一下用法,可能分析的不是很全面,欢迎批评。经过我的测试使用,jsoup分析网页结构和内容的功能远远强大于Ht

java中通过url获取网页内容,中文显示是乱码
URLConnection context = url.openConnection();InputStream in = context.getInputStream();BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8"));

Objective-C爬虫:实现动态网页内容的抓取
在当今的互联网时代,数据的获取和分析变得日益重要。无论是进行市场研究、用户行为分析还是产品开发,获取大量数据都是不可或缺的一环。然而,很多有价值的信息都隐藏在动态加载的网页中,这些网页通过JavaScript动态生成内容,传统的爬虫技术往往难以应对。本文将介绍如何使用Objective-C开发一个爬虫程序,实现对这类动态网页内容的抓取。 1. 理解动态网页的工作原理 动态网页通常使用Java

AI网络爬虫:用kimichat自动批量提取网页内容
首先,在网页中按下F12键,查看定位网页元素: 然后在kimi中输入提示词: 你是一个Python编程专家,要完成一个爬取网页内容的Python脚本,具体步骤如下: 在F盘新建一个Excel文件:提示词.xlsx 打开网页:https://lobehub.com/zh/assistants 定位class="layoutkit-flexbox css-15l7r2q ac
scrapy 使用Selenium与Scrapy处理动态加载网页内容的解决方法
引言 在爬虫技术领域,处理动态加载的网页内容常常是一项挑战,尤其是对于那些通过用户滚动或其他交互动态加载更多内容的网站。本文将介绍如何结合使用Selenium和Scrapy来有效处理这类网页。 初探Selenium与Scrapy的结合 首先,我们探索如何使用Selenium在Scrapy中间件中处理动态加载内容的网页。关键在于模拟用户滚动行为,以加载并捕获所有内容。 # Define here
复制网页内容自动添加版权信息的方法
现在很多网站都有复制网页内容自动添加版权信息,俗称小尾巴,比如:知乎,简书,CSDN等 经过查找和测试发现此代码真实有效,利用的是javascript的oncopy事件 本人对大神代码进行了改良,现记录如下: <!DOCTYPE html><html lang="zh-CN"><head><meta charset="UTF-8"><title>复制网页内容自动添加版权信息</title

用Langchain创建一个可以总结网页内容的Agent
去年的时候我写过一篇关于OpenAi Function Call的实践文章,就是用Function Call的功能实现抓取并总结网页内容的功能,具体可以参考ChatGPT函数调用初体验:让ChatGPT具备抓取网页文本的能力,当时写了还算比较多的代码,最近在学习了LangChain的使用后,发现LangChain封装的很好了,同样的功能几乎不需要写太多的代码了。 接下来我们还是以抓取并总

java爬取网页内容 简单例子(2)——附jsoup的select用法详解
来源:http://www.cnblogs.com/xiaoMzjm/p/3899366.html?utm_source=tuicool&utm_medium=referral 【背景】 在上一篇博文 java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表达式 对
Python基础12-爬虫抓取网页内容
在本文中,我们将学习如何使用 Python 的 requests 和 BeautifulSoup 库进行网页抓取。我们将从基本的网页请求开始,逐步扩展到更高级的主题,如处理分页、AJAX 请求、正则表达式和异步抓取。 1. 使用 requests 获取网页 要检索网页的内容,我们可以使用 requests 库。以下是一个简单的示例: import requestsurl = 'https:/
网页内容显示不全,TypeError: Cannot read property 'trace' of undefined错误
最近开发发现网页的部分内容不显示,控制台偶见 Error in event handler for (unknown): TypeError: Cannot read property 'trace' of undefined错误. 最后发现,是被广告拦截插件(Adblock Plus)拦截了..... 比较粗暴的解决方法是,添加白名单/关闭该插件
Python 爬虫基础:利用 BeautifulSoup 解析网页内容
1. 理解 Python 爬虫基础 在当今信息爆炸的时代,网络上充斥着海量的数据,而网络爬虫作为一种数据采集工具,扮演着至关重要的角色。网络爬虫是一种自动化的程序,可以模拟浏览器访问网页,获取所需信息并进行提取和整合。Python作为一种简洁、易学的编程语言,在网络爬虫领域备受青睐。 Python爬虫的优势主要体现在其丰富的爬虫库和强大的支持功能上。比如,Requests库可以帮助我们轻松实现
PHP 采集网页内容
1. phpQuery的用法 include 'phpQuery.php'; phpQuery::newDocumentFile('http://www.phper.org.cn'); echo pq("title")->text(); // 获取网页标题echo pq("div#header")->html(); // 获取id为header的div的html内容 上例中第一行引

挖掘网络宝藏:利用Scala和Fetch库下载Facebook网页内容
介绍 在数据驱动的世界里,网络爬虫技术是获取和分析网络信息的重要工具。本文将探讨如何使用Scala语言和Fetch库来下载Facebook网页内容。我们还将讨论如何通过代理IP技术绕过网络限制,以爬虫代理服务为例。 技术分析 Scala是一种多范式编程语言,它集成了面向对象编程和函数式编程的特点。Fetch库是一个轻量级的HTTP客户端库,用于在Scala项目中发送HTTP请求。结合使用
xcode 4.6 使用NSURLConnection 获取网页内容(iOS6.1,纯手工编码,无xib,无storyboard)
环境 iOS 6.1, xcode 4.6 一、创建新项目 1、打开 xcode,File --> New --> Project... -->Empty Application 2、项目名称 NSURLConnectionDemo,下面所有选项全部不选,完成创建。 二、创建视图控制器 3、File-->New-->File-->Objective-C class

网页内容复制粘贴出现方框空白格的解决
最近,需要对GEE网页中的代码复制到另一个网页中,却发现复制、粘贴后得到的是一个白色的矩形空白格。 例如,假如需要将下图红色圈内的GEE代码复制到CSDN博客编辑器中: 得到的结果却是“”样子的方框,如图: 刚开始以为是GEE为了防止代码抄袭所以不允许代码的复制粘贴,也就没当回事;今天偶然发现,在一些云笔记的网页端中,文字复制同样具有上面的问题。说明这应该就不是GEE网页的限
[技术翻译]Web网页内容是如何影响电池使用寿命的?
本周再来翻译一些技术文章,本次预计翻译三篇文章如下: 04.[译]使用Nuxt生成静态网站(Generate Static Websites with Nuxt) 05.[译]Web网页内容是如何影响电池功耗的(How Web Content Can Affect Power Usage) 06.[译]在现代JavaScript中编写异步任务(https://web.dev/off-mai
puppeteer设置cookie获取网页内容
使用puppeteer进行页面渲染的时候因为要登录才能获取到数据,我们不想走登录流程,想直接把cookie设置好,就需要设置cookies。 按照下面的方式进行设置 const cookies = {url: url,name: '',value: ''};await page.setCookie(cookies);await page.goto(url); 第一个参数是URL,也就是要增加
VC++中使用使用winnet类获取网页内容
微软提供的Winnet类是一个应用层的网络通信组件,它可以使你的应用程序很容易的实现http、ftp、gopher等协议而不需要你去深入的了解协议本身的规范。而之前,如果要想做类似的应用,我们必须了解socket编程并且要对协议本身非常熟悉,哪怕是一个非常非常简单的程序。 下面是codeguru上的一个使用wininet类的例子,它能够从给定的url地址中获取该文件。 这个例子
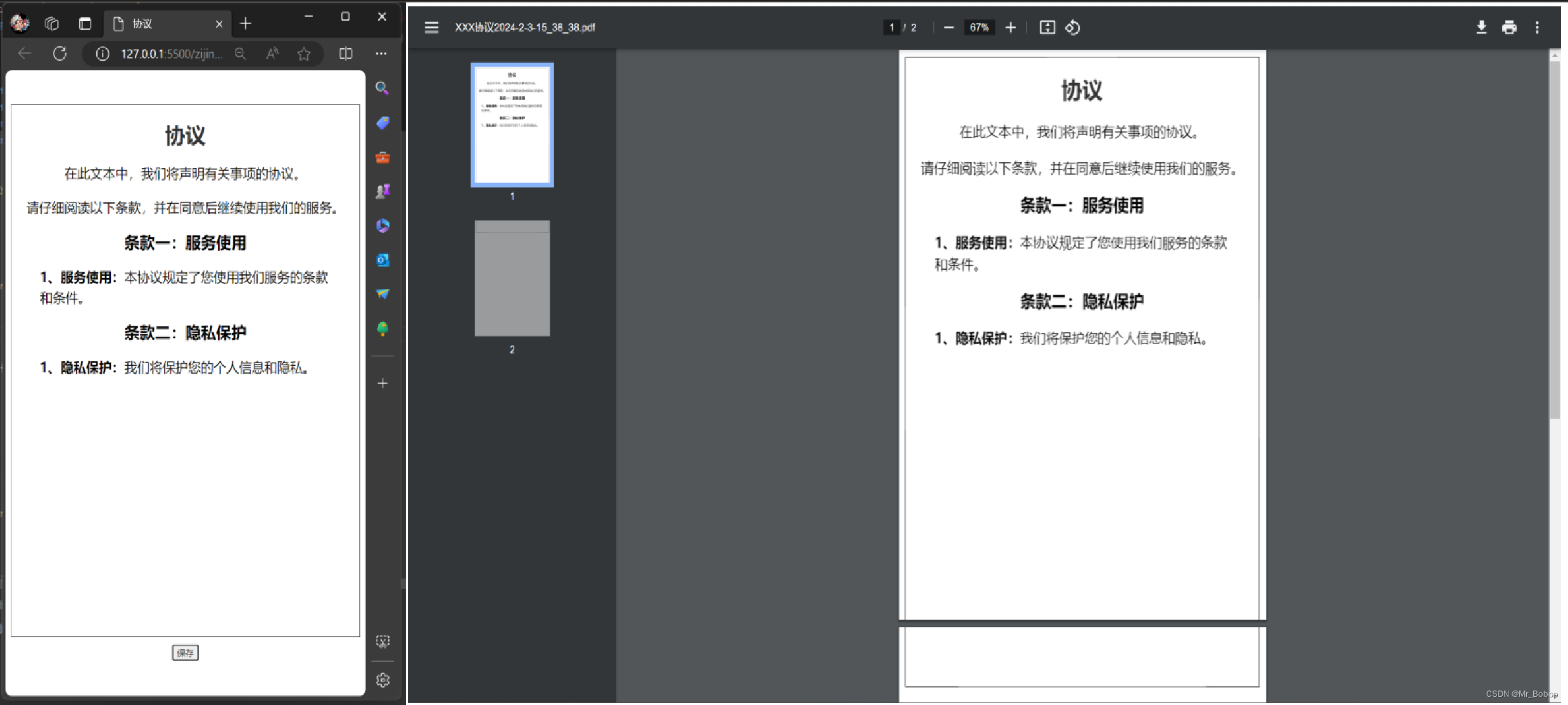
通过html2canvas和jsPDF将网页内容导出成pdf
jsPDF参考:https://github.com/parallax/jsPDF html2canvas参考:https://github.com/niklasvh/html2canvas 或者 https://html2canvas.hertzen.com 思路 使用html2canvas将选中DOM生成截图对象将截图对象借助jsPDF导出为PDF文件 代码 这是一个示例,内容都放在了