缩略词专题

《计算机英语》缩略词补充
Unit1 FTP(File Transfer Protocol) 文件传输协议 LCD(Liquid Crystal Display) 液晶显示器 GUI(Graphical User Interface) 图形用户界面 VCD(Video Compact Disc)视频光盘 CAD(Computer-Aided Design) 计算机辅助设计 CAM(Computer-Aided Manu

LeetCode 2828.判别首字母缩略词
给你一个字符串数组 words 和一个字符串 s ,请你判断 s 是不是 words 的 首字母缩略词 。 如果可以按顺序串联 words 中每个字符串的第一个字符形成字符串 s ,则认为 s 是 words 的首字母缩略词。例如,“ab” 可以由 [“apple”, “banana”] 形成,但是无法从 [“bear”, “aardvark”] 形成。 如果 s 是 words 的首字母缩略

【hcie-cloud】【23】容器编排【k8s】【Kubernetes常用工作负载、Kubernetes调度器简介、Helm简介、缩略词】【下】
文章目录 单机容器面临的问题、Kubernetes介绍与安装、Kubernetes对象的基本操作、Kubernetes YAML文件编写基础Kubernetes常用工作负载Kubernetes常用工作负载简介创建一个无状态nginx集群无状态工作负载Deployment说明无状态工作负载Deployment常见操作创建一个有状态的MySQL有状态工作负载StatefulSet说明创建一个Za
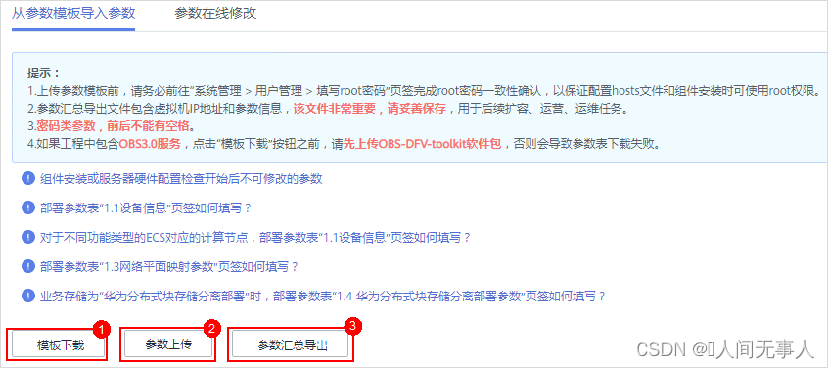
【hcie-cloud】【11】华为云Stack资源与服务扩建【云服务扩容、自动化变更平台公共服务组件、华为云Stack典型高阶服务扩容简介、缩略词】【下】
文章目录 扩容工程简介、扩容管理规模、计算资源扩容与减容云服务扩容云服务扩容简介华为云Stack云服务扩容背景华为云Stack可选基础云服务华为云Stack可选网络服务华为云Stack可选高阶服务华为云Stack云服务扩容流程 自动化变更平台&公共服务组件背景介绍自动化变更平台&公共服务组件介绍公共网络平面介绍LB组件等价路由与VIP设计原理等价路由与VIP网络平面规划示例高阶服务公共主机规
【每日一题】【12.20】2828.判别首字母缩略词
🔥博客主页: A_SHOWY🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_ 1.题目链接 2828. 判别首字母缩略词https://leetcode.cn/problems/check-if-a-string-is-an-acronym-of-words/ 2.题目描述 今天的题目是一个简单的遍历,直接for循环一遍遍历结束。判断数组的每一个元素的
【每日一题】【12.20】2828.判别首字母缩略词
🔥博客主页: A_SHOWY🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_ 1.题目链接 2828. 判别首字母缩略词https://leetcode.cn/problems/check-if-a-string-is-an-acronym-of-words/ 2.题目描述 今天的题目是一个简单的遍历,直接for循环一遍遍历结束。判断数组的每一个元素的
2828. 判别首字母缩略词 --力扣 --JAVA
题目 给你一个字符串数组 words 和一个字符串 s ,请你判断 s 是不是 words 的 首字母缩略词 。 如果可以按顺序串联 words 中每个字符串的第一个字符形成字符串 s ,则认为 s 是 words 的首字母缩略词。例如,"ab" 可以由 ["apple", "banana"] 形成,但是无法从 ["bear", "aardvark"] 形成。 如果 s 是 words 的首字
leecode | 判别首字母缩略词 | easy
题意简单,讲一下。 就是给定一个字符串容器,一个字符串,字符串容器中每个字符串的第一个元素拼接起来(顺序,依次拼接)的结果 与 上面提供的字符串一样,判别成功。 //没啥思路 直接 手撸 暴力上手class Solution {public:bool isAcronym(vector<string>& words, string s) {if(words.size() != s.siz

使用NLTK对英文文章分句,避免缩略词标点符号干扰
对于英文语料,我们想要获得句子时,可以通过正则或者NLTK工具切分。例如,NLTK: from nltk.tokenize import sent_tokenizedocument=''sentences=sent_tokenize(document) NLTK会根据“.?!”等符号切分。但是当句子中含有缩写词时,可能会产生错误的切分: sent_tokenize('fight among
SCI中缩略词的使用
1)一个词或词组在文中出现三次或以上才可以用缩写否则需要写出全称。也就是说如果只出现一次或两次,每次都要写出全称。出现的次数是在摘要、正文(从前言到讨论)、每个图注以及每个表注中分别计算的。 例如:如果一个词在摘要中出现一次,正文中出现多次,图注中又出现一次,那么摘要中只要用全称,不要用缩写。正文中第一次出现时用全称,后面用缩写;图注中用全称,不用缩写。 2)缩略语在文中第一次出现时需要定义。
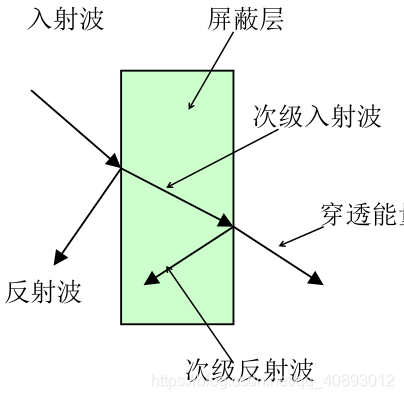
射频中的常见名词、定义、缩略词
1 微波 微波是电磁波按频谱划分的定义,是指波长从1m至0.1mm范围内的电磁波, 其相应的频率从0.3GHz至3000GHz.这段电磁频谱包括分米波(频率从0.3GHz至3GHz)\厘米波(频率从3GHz至30GHz)\毫米波(频率从30GHz至300GHz)和亚毫米波(频率从300GHz至3000GHz,有些文献中微波定义不含此段)四个波段 (含上限,不含下限) 。具有似光性/似声性/穿透性