某书专题

记录某书请求返回406及响应{“code“:-1,“success“:false}
今天测试某个平台的爬虫时使用requests post请求正常写了个测试脚本把各种参数带上出来以后出现了406情况,和网站数据是完全一样的 以为是 X-S、X-T参接不对,但在postman里测试又是可以的成功,以为是检验了参数顺序,测试发现也没校验 最后发现是校验了data里内容,必须是无空格的json, 我… 最后,贴一下成功请求的结果
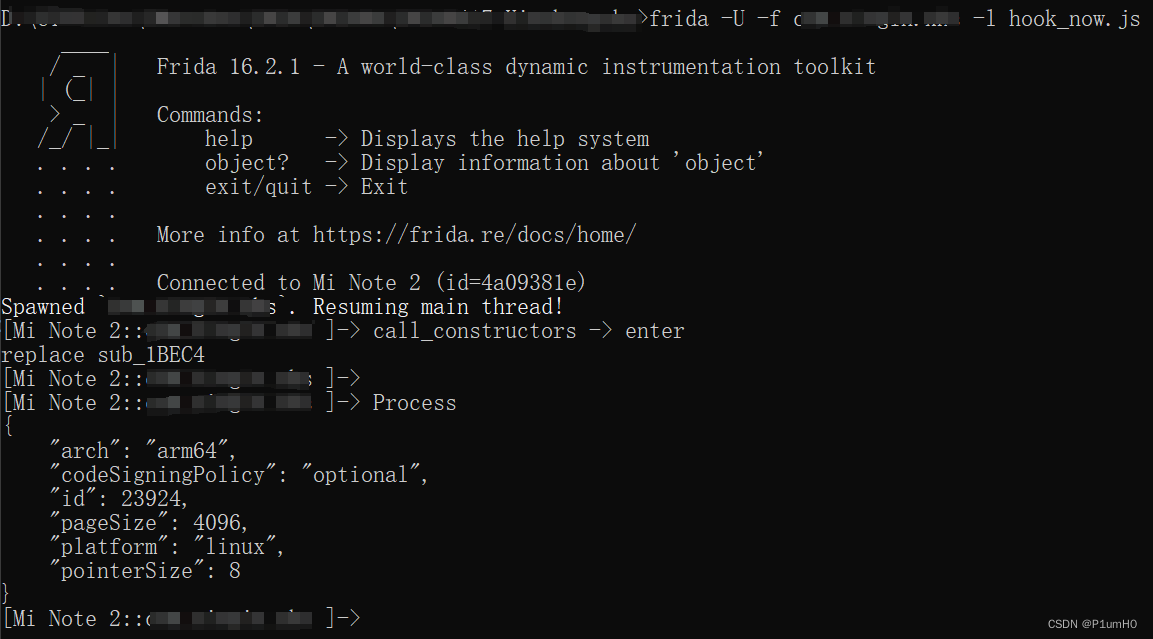
某书Frida检测绕过记录
某书Frida检测绕过记录 前言Frida启动APPHook android_dlopen_ext查看加载的库分析libmsaoaidsec.soFrida检测绕过后记 前言 本来想要分析请求参数加密过程,结果发现APP做了Frida检测,于是记录一下绕过姿势(暴力但有用) Frida版本:16.2.1 APP版本:8.31.0 Frida启动APP frida -U -f
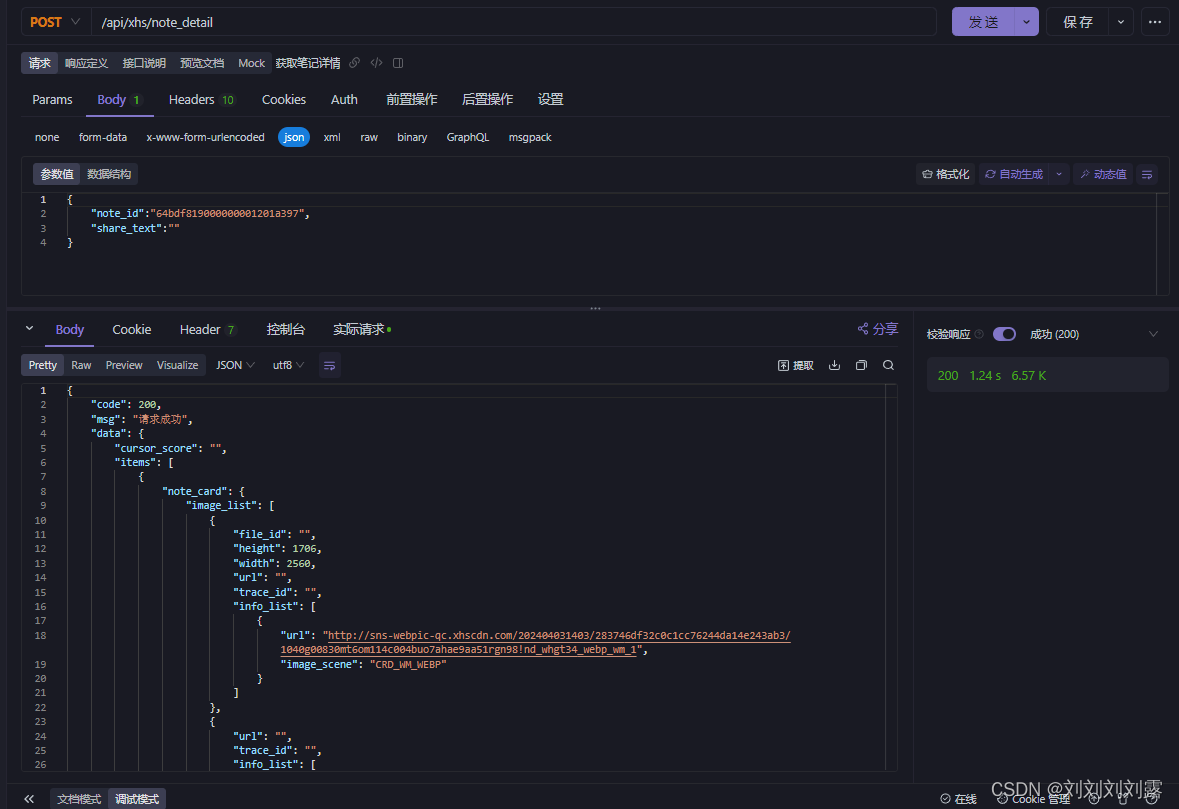
使用Python获取红某书笔记详情并批量无水印下载
根据红某手最新版 请求接口必须要携带x-s x-s-c x-t,而调用官方接口又必须携带cookie,缺一不可,获取笔记详情可以通过爬取网页的形式获取,虽然也是无水印,但是一些详情信息只能获取大概,并不是详细的数值,因此既不想自己破解x-s x-s-c x-t,又想获取详细信息怎么办呢? 调用API MoreAPI 已经集成红某书、某音、KS等常用平台的各系列API,使用方法也非常简单
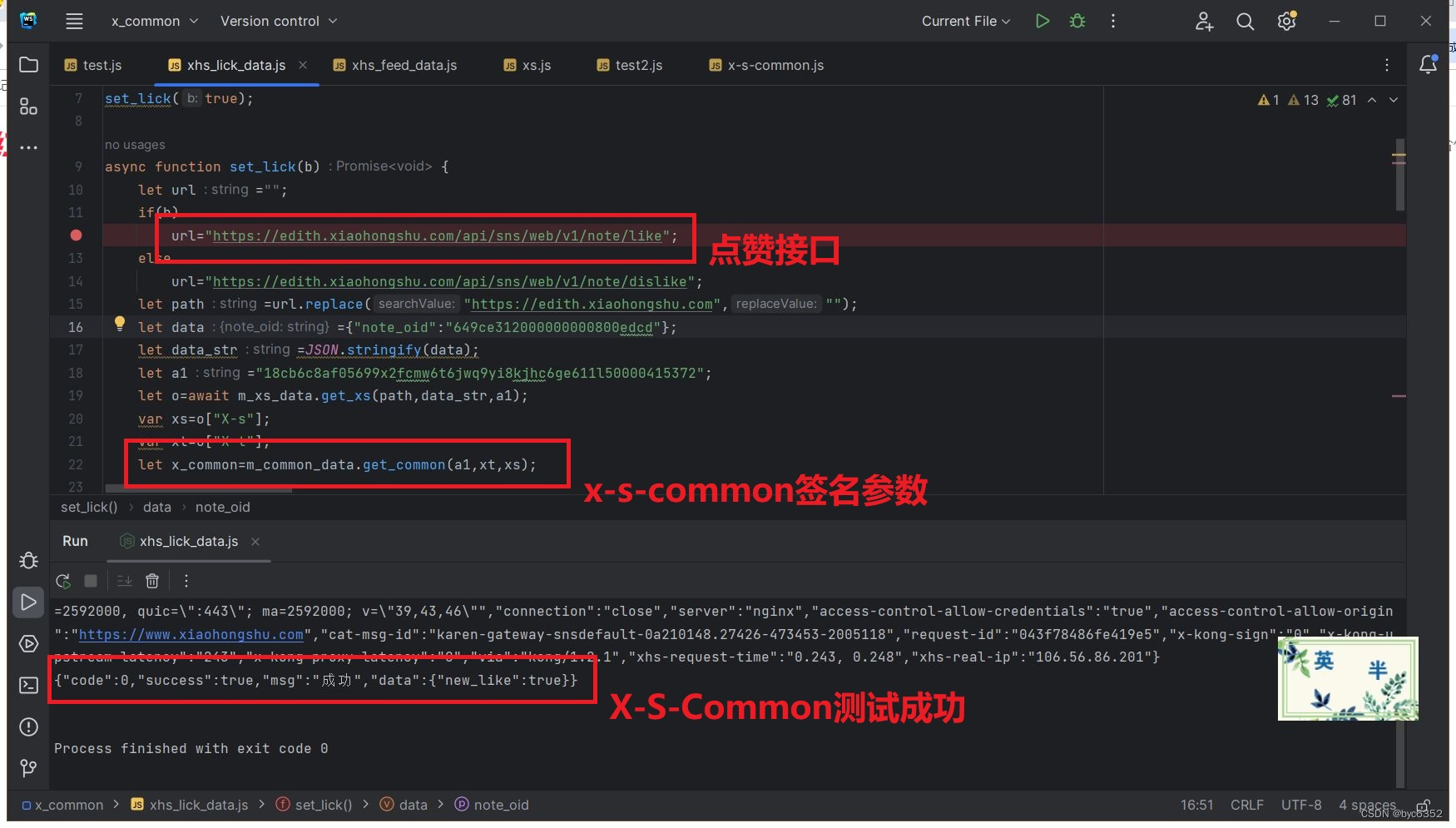
2024年某书最新x-s-common签名算法分析以及点赞api接口测试nodejs(2024-01-05)
2024年某书又更新了x-s-common算法,现在的版本是:3.6.8。这个签名算法现在是越来越重要了,许多接口都要用到。比如:评论,点赞等接口,没有这个算法采集不到数据。 一、chrome逆向x-s-common算法 1、x-s-common 打开chrome,按f12,打开开发者模式,随便找一接口,全局搜索:x-s-common,找到
影刀实例二,小某书如何持续下载图片
一,案例背景: 小某书平台,利用影刀rpa搜索关键词,然后下载对应文章的图片. 二,思路 1. 登录小某书平台,将网页放大最大【手动完成,作为初始状态】 2. 利用影刀命令【打开输入对话框】获得要搜索的关键词 3.利用命令【填写输入框】接受2的结果,填入搜索框,并点击搜索 4.因为之想下载图文,不涉及视频,所以在点击 【图文】 5.重点来了,本来批量获得相类似的元素一般
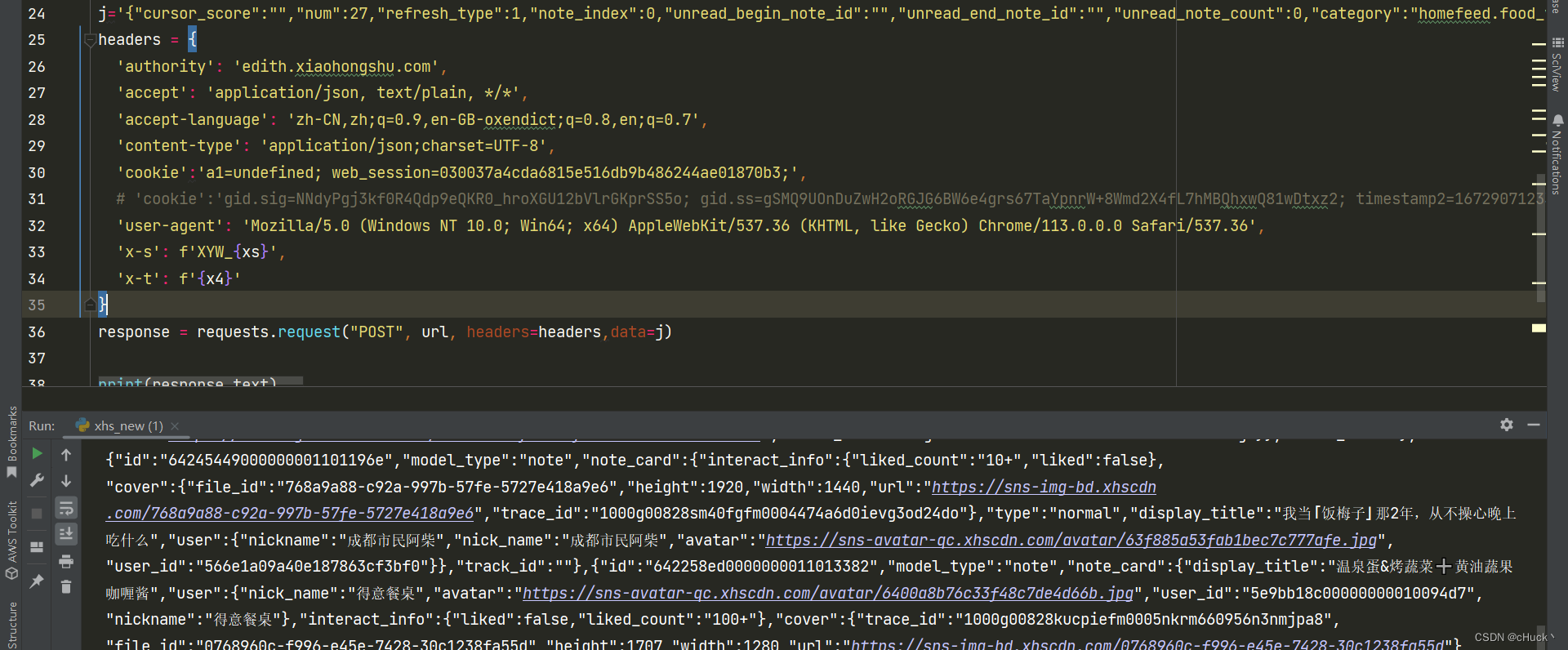
【某书】新版x-s纯算法,纯分享
纯分享思路!!!! 纯分享思路!!!! 纯分享思路!!!! 纯分享思路!!!! 新版x-s,x-t加密,XYW_后面那段是base64,处理下得到{"signSvn":"50","signType":"x1","appId":"xhs-pc-web","signVersion":"1","payload":5750ca90480c12e265865dc4849e951c5bdf907067