故事会专题
【爬虫实战】用pyhon爬百度故事会专栏
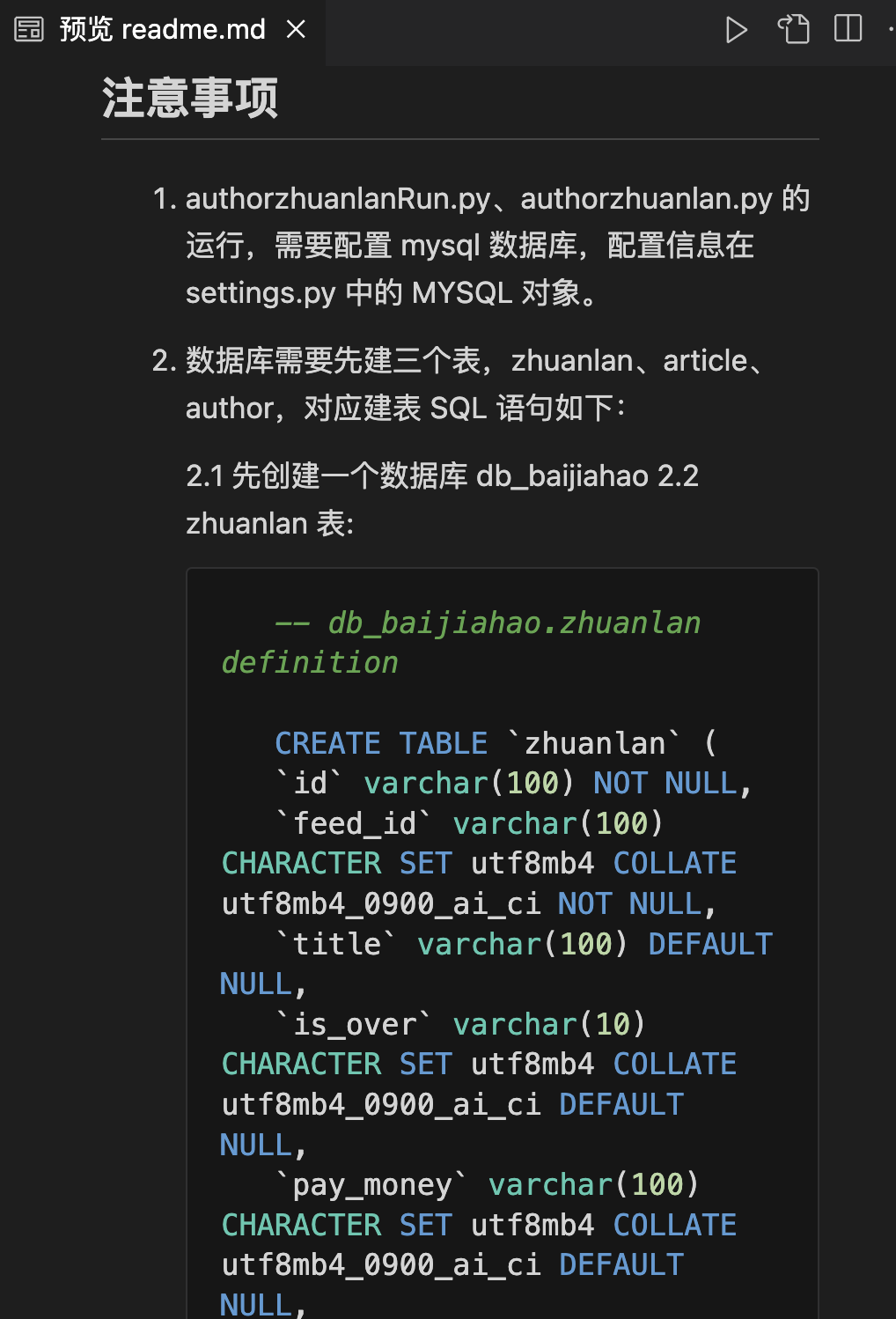
一.爬虫需求 获取对应所有专栏数据;自动实现分页;多线程爬取;批量多账号爬取;保存到mysql、csv(本案例以mysql为例);保存数据时已存在就更新,无数据就添加; 二.最终效果 三.项目代码 3.1 新建项目 本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤: 1.新建项目: scrapy startproject auth