探微专题
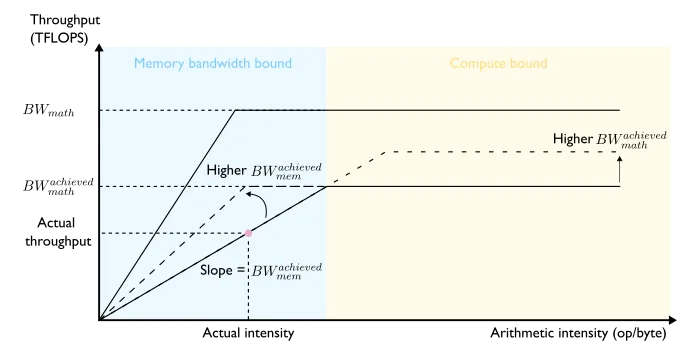
LLM 推理优化探微 (4) :模型性能瓶颈分类及优化策略
编者按: 在人工智能浪潮袭卷全球的大背景下,进一步提升人工智能模型性能,满足更多应用需求已经刻不容缓。如何优化模型延迟和吞吐量,成为了业界亟待解决的重要问题。 我们今天为大家带来的这篇文章,其观点为:不同的性能瓶颈需要采取不同的优化策略,识别并解决主要的性能瓶颈是提升模型性能的关键。 文章指出,主要有 4 种影响模型性能的瓶颈:计算能力受限、内存带宽受限、通信受限和开销受限。作者分别介绍了针对这
LLM 推理优化探微 (3) :如何有效控制 KV 缓存的内存占用,优化推理速度?
编者按: 随着 LLM 赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,Baihai IDP 推出 Pierre Lienhart 的系列文章,从多个维度全面剖析 Transformer 大语言模型的推理过程,以期帮助读者对这个技术难点建立系统的理解,并在实践中做出正确的模型服务部署决策。 本文是该系列文章

LLM 推理优化探微 (2) :Transformer 模型 KV 缓存技术详解
编者按:随着 LLM 赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,Baihai IDP 推出 Pierre Lienhart 的系列文章,从多个维度全面剖析 Transformer 大语言模型的推理过程,以期帮助读者对这个技术难点建立系统的理解,并在实践中做出正确的模型服务部署决策。 本文是该系列文章的